Primeira lista de exercícios – Sistemas digitais
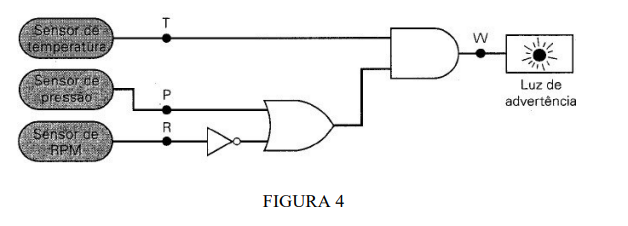
1) Muitos sistemas de controle industrial requerem a ativação de uma função de saída
sempre que qualquer de suas várias de entradas for ativada. Por exemplo, em um processo
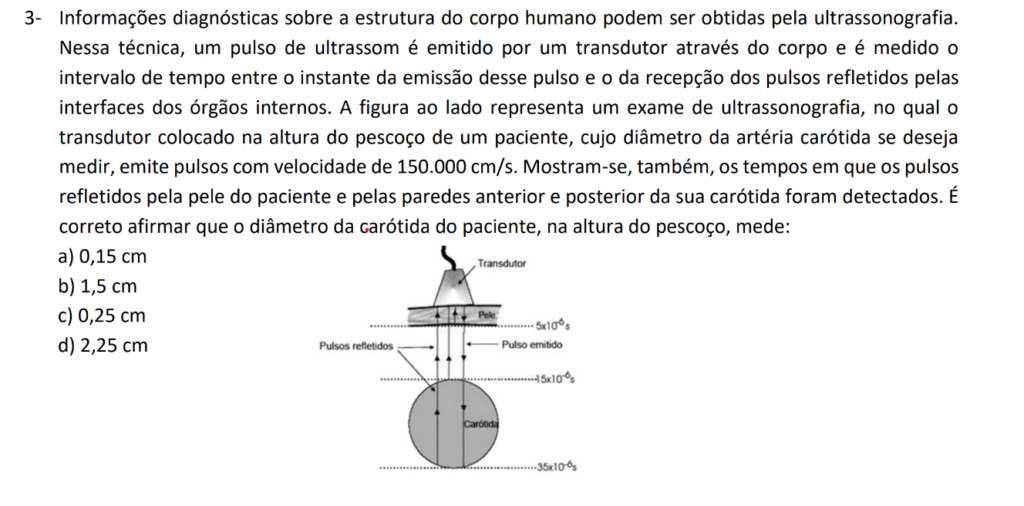
químico, pode ser necessário que um alarme seja ativado sempre que a temperatura do processo
exceder um valor máximo ou sempre que a pressão ultrapassar certo limite. A figura 1 é um
diagrama em blocos desse sistema. O circuito transdutor de temperatura produz uma tensão de
saída proporcional à temperatura do processo. Essa tensão, VT, é comparada com uma tensão de
referência para temperatura, VTR, em um circuito comparador de tensão. A saída do comparador
de tensão, TH, é normalmente uma tensão baixa (nível lógico 0), mas essa saída muda para uma
tensão alta (nível lógico 1) quando VT excede VTR, indicando que a temperatura do processo é
muito alta. Uma configuração similar é usada para a medição de pressão, de modo que a saída do
comparador, PH, muda de baixa para alta quando a pressão for muito alta. Qual a finalidade da
porta OR?

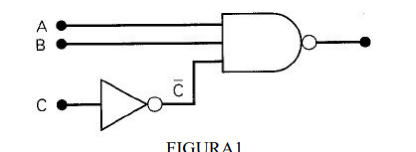
2) Desenhe a forma de onda de saída para a porta OR da figura 2.

a. Suponha que a entrada A na figura 2 seja curto-circuitada para o terra (isto é,
A=0). Desenhe a forma de onda de saída resultante.
b. Suponha que a entrada A na figura 2 seja curto-circuitada para a linha de
alimentação (isto é, A=1). Desenhe a forma de onda de saída resultante
3) Assinale Verdadeiro ou Falso:
a. Se a forma de onda de saída de uma porta OR for a mesma que a de uma das
entradas, a outra entrada está sendo mantida permanentemente em nível BAIXO.
b. Se a forma de onda de saída de uma porta OR for sempre nível ALTO uma de
suas entradas está sendo mantida sempre em nível ALTO.
Sugestão: Monte a tabela verdade da porta OR e desenhe as formas de onda
mencionadas.
4) Troque a porta OR da figura 2 por uma porta AND.
a. Desenhe as formas de onda de saída.
b. Suponha que a entrada A na figura 2 seja curto-circuitada para o terra (isto é,
A=0). Desenhe a forma de onda de saída resultante.
c. Suponha que a entrada A na figura 2 seja curto-circuitada para a linha de
alimentação (isto é, A=1). Desenhe a forma de onda de saída resultante.
5) Tomando como referência o exercício 1, modifique o circuito de modo que o alarme seja
ativado apenas quando a pressão e a temperatura excederem, ao mesmo tempo, seus
valores-limite.
6) Verdadeiro ou Falso:
a. Uma porta AND, não importando quantas entradas tenha, produzirá uma saída
em nível ALTO para apenas uma combinação de níveis de entrada.
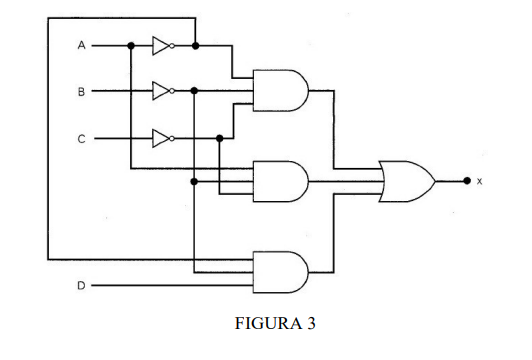
7) Escreva a expressão booleana para a saída x de ambos os circuitos da figura 3. Determine
o valor de x para todas as condições possíveis de entrada e relacione os resultados em
uma tabela-verdade.

b) x = ~A ~B ~C + ~A ~B ~C + ~A ~B D
A B C D X
0 0 0 0 1
0 0 0 0 1
0 0 0 1 1
0 0 1 0 0
0 0 1 0 0
0 0 1 1 1
0 1 0 0 0
0 1 0 1 0
0 1 1 0 0
0 1 1 1 0
1 0 0 0 1
1 0 0 1 1
1 0 0 0 1
1 0 0 1 1
1 0 1 0 0
1 0 1 1 0
1 1 0 0 0
1 1 0 1 0
1 1 1 0 0
1 1 1 1 0
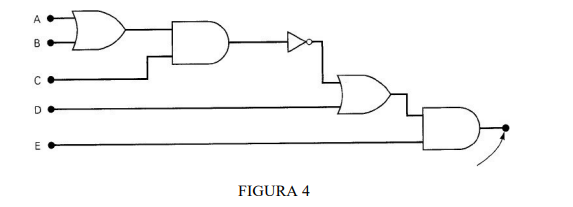
8) Escreva a expressão booleana de saída para a figura 4.
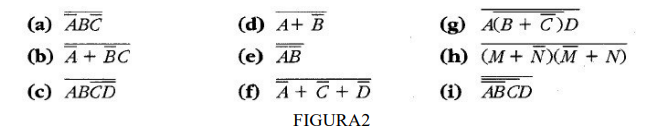
9) Para cada uma das expressões a seguir, desenhe o circuito lógico correspondente usando
portas AND, OR e INVERSORES.

10) Determine a expressão booleana para uma porta NOR de três entradas seguida de um
INVERSOR.
cada um dos seguintes conjuntos de dados de entrada:
a. 0111
b. 1001
c. 0000
d. 0100