Analise de Circuito – Leis de Kirchhoff
Quem é Kirchhoff
Gustav Robert Kirchhoff foi um físico alemão que fez contribuições significativas em vários campos da física e da química. Ele é mais conhecido por suas leis que descrevem o fluxo de corrente elétrica em circuitos elétricos, as Leis de Kirchhoff, que são fundamentais para a engenharia elétrica e a física.
Kirchhoff nasceu em 1824 e faleceu em 1887. Durante sua vida, ele trabalhou em problemas de termodinâmica, óptica e espectroscopia, além de eletricidade. Junto com Robert Bunsen, Kirchhoff desenvolveu a espectroscopia, que é um método para analisar a composição química de materiais baseado na luz que eles emitem ou absorvem. Através desse trabalho, eles foram capazes de descobrir novos elementos químicos, como o césio e o rubídio.
As duas leis de Kirchhoff para circuitos elétricos, formuladas em 1845, são:
- A Lei dos Nós (ou Lei das Correntes de Kirchhoff): A soma das correntes que entram em um ponto (ou nó) do circuito é igual à soma das correntes que saem desse ponto. Isso é uma consequência da conservação da carga elétrica.
- A Lei das Malhas (ou Lei das Tensões de Kirchhoff): A soma das diferenças de potencial elétrico (tensões) em uma malha fechada é igual a zero. Isso é baseado no princípio da conservação de energia.
Essas leis são aplicadas no design e análise de circuitos elétricos, permitindo calcular correntes e tensões em diversos pontos de um circuito. Além de suas contribuições para a física, as descobertas de Kirchhoff tiveram um impacto duradouro em várias áreas da ciência e tecnologia.
Leis de Kirchhoff
As Leis de Kirchhoff são dois princípios aplicados em circuitos elétricos que ajudam a entender a conservação da carga e da energia em tais sistemas. Elas são fundamentais para a análise de circuitos elétricos em engenharia e física. As leis foram formuladas por Gustav Kirchhoff em 1845 e são conhecidas como Lei dos Nós (Primeira Lei) e Lei das Malhas (Segunda Lei).
1. Lei dos Nós (Lei das Correntes de Kirchhoff)
A Primeira Lei de Kirchhoff, ou Lei dos Nós, afirma que a soma algébrica das correntes em qualquer nó de um circuito é igual a zero. Isso significa que a quantidade total de corrente elétrica que flui para um nó é igual à quantidade total de corrente que sai dele. Matematicamente, isso pode ser expresso como:
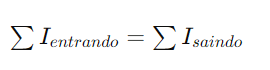
ou, de forma mais geral,
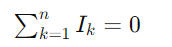
onde ��Ik representa a corrente da k-ésima conexão em um nó, com correntes entrando no nó tratadas como positivas e correntes saindo como negativas. Essa lei é uma consequência da conservação da carga elétrica.
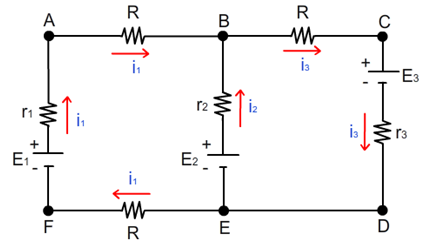
2. Lei das Malhas (Lei das Tensões de Kirchhoff)
A Segunda Lei de Kirchhoff, ou Lei das Malhas, afirma que a soma algébrica das diferenças de potencial (tensões) em qualquer malha fechada do circuito é igual a zero. Isso significa que a soma das quedas de tensão (consumo de energia) é igual à soma das tensões fornecidas (fontes de energia) em uma malha. Em outras palavras, a energia total em um circuito fechado é conservada. Matematicamente, pode ser expressa como:
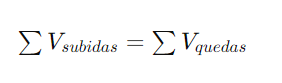
ou, de forma mais geral,
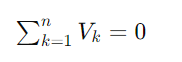
onde Vk representa a diferença de potencial (tensão) na k-ésima componente da malha, com tensões no sentido do percurso assumidas como positivas e tensões contra o percurso como negativas.
Essas duas leis juntas permitem a análise completa de circuitos elétricos complexos, possibilitando calcular correntes e tensões em diversas partes de um circuito.