
Biblioteca Spacy para Python
Spacy é uma biblioteca de processamento de linguagem natural, desenvolvida para auxiliar na analise e identificação do contexto de textos.
Ela pode ser utilizada, quando há necessidade de entender o que foi escrito.
A lib é mantida pelo site:
Muito utilizada em NLP (Natural Linguage Process) Processamento de Linguagem Natural.
A biblioteca tenta analisar texto, sobre os aspectos de sua estrutura morfológica e sintática.
Identificando o sujeito da frase, os verbos e etc. Traçando também uma relação de dependência entre as diversas partes.
Todos os exemplos aqui descritos, estão em meu repositório:
Github
https://github.com/marcelomaurin/ExSpacy
Instalação do Spacy
Estarei usando o python 3, e o procedimento de instalação é relativamente simples.
Instalando a biblioteca
pip3 install spacyNo nosso repositório na pasta src/install, inclui um script ./install.sh que automatiza a instalação.
Porem considero que o usuário tenha instalado o python 3 previamente.
Para rodar o procedimento de instalação rode:
> /src/install/install.shModelos
Modelos são treinados para reconhecer aspectos de diversos idiomas, tais como o portugues.
Existem diversos modelos em diversos idiomas, voce pode escolher o modelo que deseja instalar através do link:
Os modelos em português não destoam do português Brasil, pois as regras ortográficas são as mesmas em qualquer pais com a língua.
Ao rodar nosso install o padrão do modelo com melhor acurácia, já será instalado automáticamente.
Primeiro Exemplo
Agora iremos colocar a mão na massa!
Neste primeiro modelo, apresentamos um texto e analisamos o mesmo de forma sintática.
Esterei apresentando o Ex01 do nosso git:
import spacy
nlp = spacy.load("pt_core_news_lg")
import pt_core_news_lg
nlp = pt_core_news_lg.load()
doc = nlp("O Marcelo pegou COVID-19 em setembro de 2019, porem não teve problemas com isso")
for token in doc:
print("Token:"+token.text)
print("Pos:"+token.pos_)
Nele importamos a lib spacy, e em seguida carregamos a rede treinada pt_core_news_lg. Após isso identificamos o texto alvo através da variável doc.
E em seguida mostramos alguns resultados tokenizados.
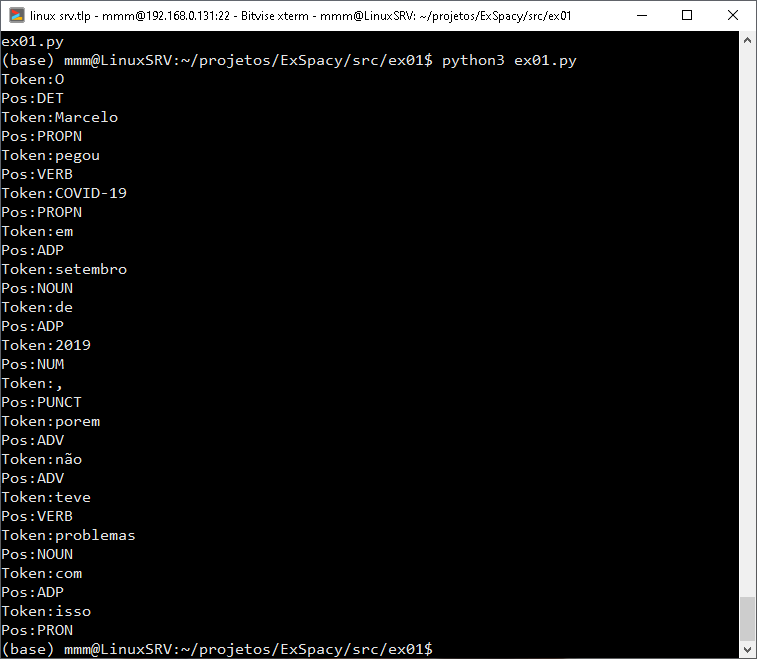
O POS faz a analise do que significa o token.
Maior informação sobre a morfologia aplicada ao spacy pode ser vista no link abaixo:
https://spacy.io/api/morphologizer
Pudemos ver neste artigo os primeiros fundamentos da lib spaCy, espero que tenham gostado.