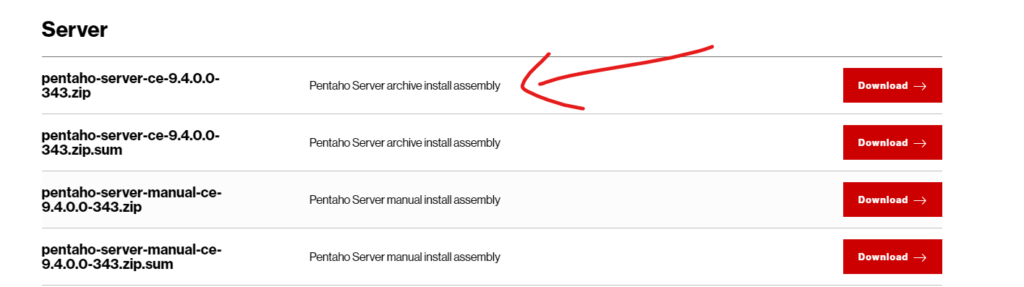
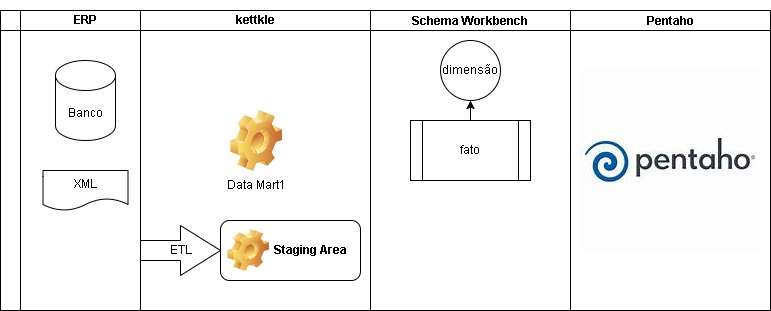
Neste modelo, podemos ver como as coisas funcionam.
O ERP que possui os dados se conecta com a ferramenta kettkle, que extrai os dados gerando os data marts que são grandes grupos de dados extraídos do ERP.
Após importados os dados do ERP, o Schema Workbench gera e processa os dados em dimensões de dados. Que a grosso modo são os dados trabalhados, para um dado objetivo. Exemplo processamento de dados em dimensão de tempo (classificando em hierarquias como ano, mes , trimestre , etc.).
Por fim, a partir dos dados criados no schema são consumidos em OLAPs usando o Pentaho para criar relatórios e analises, dashboards.
Kettkle
O termo “Kettle” refere-se a “K.E.T.T.L.E.”, que é um acrônimo para “Kettle Extraction Transformation Transport Load Environment”. Kettle é o nome original do projeto que agora é mais comumente conhecido como “Pentaho Data Integration” (PDI).
O PDI/Kettle é uma ferramenta de integração de dados open-source.
Ele fornece funcionalidades ETL (Extract, Transform, Load – Extração, Transformação e Carga), permitindo aos usuários definir processos para extrair dados de várias fontes, transformá-los conforme necessário e, em seguida, carregá-los em sistemas de destino, como bancos de dados, data warehouses, ou outras aplicações.
O Kettle foi projetado para ser flexível e extensível, suportando uma ampla variedade de fontes de dados e destinos, transformações e operações de carga. A interface gráfica do PDI permite que os usuários “desenhem” seus processos ETL, arrastando e soltando componentes e conectando-os para definir fluxos de dados.
Algumas características notáveis do Kettle/PDI incluem:
Spoon: É a interface gráfica utilizada para criar, editar e executar transformações e jobs.
Pan: Permite executar transformações a partir da linha de comando.
Kitchen: Permite executar jobs a partir da linha de comando.
Carte: Um servidor web simples para execução remota de transformações e jobs.
O Kettle foi um dos componentes principais da suíte Pentaho quando esta foi lançada. Com o tempo, o nome “Kettle” foi um pouco ofuscado em favor de “Pentaho Data Integration”, mas muitos ainda usam os termos de forma intercambiável, especialmente aqueles que têm experiência com as versões mais antigas da ferramenta.
Schema Workbench
O “Schema Workbench” é uma ferramenta associada ao Pentaho Analysis Services (também conhecido como Mondrian).
Sua principal função é fornecer uma interface gráfica para a criação e edição de esquemas OLAP (On-Line Analytical Processing). Estes esquemas definem cubos, dimensões, hierarquias e medidas que são usadas para criar consultas multidimensionais e análises em dados armazenados em bancos de dados relacionais.
Aqui estão alguns pontos-chave sobre o papel do Schema Workbench:
Definição de Cubos: Dentro de um esquema OLAP, o conceito central é o de um “cubo”. Um cubo é uma estrutura de dados multidimensional que permite a análise rápida de grandes volumes de dados a partir de diferentes perspectivas ou dimensões. Com o Schema Workbench, os usuários podem definir quais tabelas e colunas do banco de dados serão usadas para criar esses cubos.
Criação de Dimensões e Hierarquias: Dimensões são categorias de análise (como tempo, geografia, produtos, etc.) e podem ter hierarquias (por exemplo, uma hierarquia de tempo pode ter ano, mês e dia). O Schema Workbench permite que os usuários definam e organizem essas dimensões e hierarquias.
Medidas: Estes são os valores que você quer analisar, como vendas, custos, lucros, etc. Com o Schema Workbench, os usuários podem definir quais colunas do banco de dados representam medidas e como elas serão calculadas.
Validação: Após criar ou editar um esquema, o Schema Workbench fornece ferramentas para validar o esquema para garantir que ele seja correto e funcione como esperado.
Teste de Consultas MDX: MDX (MultiDimensional eXpressions) é a linguagem de consulta usada em sistemas OLAP. O Schema Workbench oferece uma interface onde os usuários podem testar suas consultas MDX para verificar os resultados do esquema recém-criado ou modificado.
Exportação e Integração: Uma vez que um esquema é definido e validado, ele pode ser exportado e integrado ao servidor Pentaho Analysis (Mondrian) para ser usado em aplicações de business intelligence.
O Schema Workbench simplifica a tarefa de definir e organizar a estrutura dos dados para análise OLAP, tornando mais fácil para os desenvolvedores e analistas de BI criar soluções de análise robustas usando o Pentaho/Mondrian.
Pentaho
O Pentaho fornece um ecossistema integrado de ferramentas para business intelligence, desde a integração de dados até a visualização. O Schema Workbench, associado ao Pentaho Analysis Services (Mondrian), é usado para criar esquemas OLAP que definem como os dados são estruturados para análise multidimensional. Depois de definir um esquema com o Schema Workbench, ele pode ser usado no Pentaho para criar relatórios, análises e dashboards.
Visão Geral
Aqui está uma visão geral de como os dados dos esquemas criados no Schema Workbench são visualizados no Pentaho:
Criação e Publicação de Esquemas:
Começa-se por usar o Schema Workbench para criar um esquema OLAP, definindo cubos, dimensões, hierarquias e medidas.
Após a definição do esquema, ele é publicado ou implantado no Pentaho Analysis Services (Mondrian).
Pentaho User Console (PUC):
O PUC é a interface web central para acessar e trabalhar com as ferramentas de BI do Pentaho.
Dentro do PUC, os usuários podem criar novas análises OLAP usando os esquemas publicados. Estas análises permitem aos usuários arrastar e soltar dimensões e medidas para criar tabelas pivot, gráficos e outros tipos de visualizações.
Os usuários também podem criar relatórios e dashboards que incorporam visualizações baseadas em análises OLAP.
Saiku:
Saiku é um plugin popular para o Pentaho que oferece uma interface intuitiva para criar análises OLAP. Ele pode conectar-se diretamente aos esquemas definidos no Schema Workbench.
Saiku permite aos usuários explorar dados, realizar drill-down e drill-up, filtrar dados e criar visualizações, tudo em uma interface drag-and-drop.
Dashboards:
Os esquemas OLAP criados no Schema Workbench também podem ser usados como fontes de dados para dashboards no Pentaho.
Estes dashboards podem combinar visualizações OLAP com outros tipos de conteúdo, como relatórios, gráficos, mapas e mais.
Performance:
Os esquemas definidos no Schema Workbench e visualizados no Pentaho aproveitam a capacidade do Mondrian de executar consultas MDX (MultiDimensional eXpressions) rapidamente, permitindo que os usuários analisem grandes volumes de dados em tempo real.
Em resumo, o Schema Workbench é usado para definir a estrutura dos dados para análise multidimensional. Uma vez definidos e publicados, esses esquemas são a base para a criação de análises, relatórios e dashboards no ecossistema Pentaho, permitindo aos usuários visualizar e explorar seus dados de várias maneiras.
O objetivo deste artigo é apresentar uma visão geral sobre este protocolo.
Histórico
Criado em 1987 a ISO8583 descreve o intercâmbio entre requisições bancárias.
Funcionamento
Sem entrar muito no detalhe do funcionamento.
Basicamente a imagem abaixo, ilustra o funcionamento do protocolo em linhas gerais.
Visão geral do protocolo
De forma geral, o PDV ou POS solicita a operadora uma dada solicitação.
Por exemplo:
inicio de pagamento com cartão de crédito.
No corpo da solicitação, irão alguns dados identificadores da solicitação.
A operadora, pode conforme o tipo da solicitação, perguntar algumas coisas, como senha, tipo de cartão entre outras coisas.
Ou mesmo solicitar a visualização de outras.
A esta solicitação (chamamos de ação), que deve ser respondida pelo PDV ou POS.
A operadora pode realizar quantas perguntas forem necessárias para atendimento de suas necessidades.
Ao fim a operadora envia a resposta final, dando por encerrado a operação.
Em linhas bem gerais é assim que funciona o protocolo ISO 8583.
Estaremos entrando em detalhes, mais adiante.
Porem para entendimento geral, é um protocolo mestre/escravo, onde após a solicitação inicial, a operadora passa a solicitar informações, que devem ser respondidas.
Identificadores de tipo de mensagens
O identificador de tipo de mensagem é um campo numérico de 4 dígitos que especifica o tipo da mensagem que deve ser processado.
Formatação do cabeçalho da solicitação
V: número de versão da ISO 8583 (0 indica que é ISO 8583:1987; 1 indica ISO 8583:1992).
n: Classe da Mensagem conforme a tabela abaixo: | 0 Reserved for ISO use | 1 Authorization | 2 Financial | | 3 File action | 4 Reversal/Chargeback | 5 Reconciliation | | 6 Administration | 7 Fee collection | 8 Network management | | 9 Reserved for ISO use | | |
X: Função da Mensagem conforme tabela: | 0 Request | 1 Request response | 2 Advice | | 3 Advice response | 4 Notification | 5 – 9 Reserved for ISO use |
Y: Origem da Transação | 0 Acquirer | 1 Acquirer repeat | 2 Card issuer | | 3 Card issuer repeat | 4 Other | 5 Other repeat | | 6 –9 Reserved for ISO use | | |
Simulando PDV e Simulando Autorizadora
Eu vasculhando a internet achei o site da neapay, conforme referência.
Baixei um download simulator_ISSUER_ISO8583_host_auth_PRO.
A aplicação trabalha com JAVA, e é uma boa pedida quem deseja testar e aprender mais sobre o protocolo.
Cython é uma ferramenta de integração Entre Python e C/C++, permitindo criar interfaces integráveis entre as duas linguagens.
O uso do cython tende a auxiliar ambos os programadores dos dois mundos.
Para os programadores C/C++ o uso do python permite criar funções mais dinâmicas e rápidas de serem construídas. Permitindo acesso a tecnologias que o programador C demoraria mais para construir nas interfaces nativas.
Para o programador Python, permite utilizar todo o poder o C e C++ integrado com códigos rápidos e ágeis do Python.
Estaremos neste artigo, instalando o cython na máquina, e no próximo criando um case para que possamos utiliza-lo.
Abordaremos apenas a instalação do cython, pois entendemos que os demais ambientes são de responsábilidade dos desenvolvedores.
Instalação do Cython no Linux
Para instalar o cython é necessário ter o python 3.7 ou superior.
Caso tenha uma versão menor, será necessário atualizar sua versão.
Voce tem uma empresa, voce desenvolve programas Open Source no meu segmento.
Porque deveria contratar um concorrente?
Naquele momento, percebi que minhas intensões não estavam sendo claras. E resolvi publicar este artigo.
Projeto Open Source nunca concorre com aplicações comerciais. Eu nunca ví, em meus 24 anos de carreira, uma empresa que faliu por conta de um software open source.
A única coisa que ví, foi a Microsoft, que depois de muito sofrimento, aderiu ao mundo open source. Hoje está ganhando dinheiro com Linux.
Então, se voce souber de alguma empresa que faliu por conta de um projeto open source, é bom falar agora, ou cale-se para sempre.
Software Open Source, são em sua essencia ferramentas de fomento e desenvolvimento.
Quando desenvolvemos um projeto Open source estável e seguro, este, cria um leque de possibilidades e serviços que qualquer empresa pode agregar.
De fato, projetos open source criam oportunidades, não as tira.
O Linux é o maior CASE do mundo open source, mas não é o unico.
Existem vários, como:
APACHE
Blender
Docker
GIT
KUBERNETES
R
SUGARCRM
Entre tantos outros.
O Apache mesmo, fomentou e desenvolveu diversos serviços e produtos. Sendo a base para produtos incriveis pagos.
VAREJO OPEN SOURCE
Poucas ações tem contríbuido mais com o varejo que o ACBR, projeto Open Source destinado a alavancar empresas no desenvolvimento de soluções para PDV e Self Checkout.
Conheço grandes player que trabalhei que a base de funcionamento do seu PDV é baseado no ACBR.
Apesar de termos um grande player, como o ACBR, existem poucas soluções Open Source destinadas ao Varejo.
Vamos falar de minhas soluções
Os projetos que desenvolvo, são sempre atrelados a Hardware, minha paixão.
Sempre que criei uma lib, ou desenvolvo conexão com um hardware, este pode e deve ser integrado, dentro de uma cadeia ou software house.
Vamos falar sobre alguns projetos:
O srvCP é um software (servidor) destinado a integrar com equipamentos de consulta de preço. Este por si só precisa de uma base de produtos, que deve ser integrada de um PDV ou CRM. Dificilmente um cliente entrega meu software sem ter um PDV ou CRM em sua loja.
Pois este precisa de uma base de produtos saneados.
Então, o srvCP não prejudica desenvolvedores de software, muito pelo contrário, agrega uma oportunidade, permitindo agregar o benefício de uso de leitores de preço sem a necessidade de desenvolvimento e manutenção deste equipamento.
Agora iremos falar sobre outro projeto o RFID, este projeto destinado a criar um leitor de RFID de mesa, não tem o objetivo de fornecer equipamentos para o varejo, ou atacadistas. Pois o seu desenvolvimento implica em assemblagem de equipamentos eletrônicos, bem como impressão. O que por fim acaba saindo mais caro que seus equipamentos industriais. Porem, este pode ser usado em ambientes de desenvolvimento, e equipes de TI, permitindo a simulação em seu PDV de cartões. Sem a real necessidade de compra de seus pares industrializados. O uso deste, permite aprimorar e desenvolver conceitos na indústria de software.
Outro exemplo, é o software de emissão de etiqueta, este projeto permite criar um serviço de impressão de etiquetas, permitindo a integração com o CRM, através de uma web api. Permitindo imprimir etiquetas de gondolas de forma fácil e transparente.
Por fim, iremos falar sobre o projeto Leitor Balança, este projeto visa criar um serviço de leitura de balança, que permite através de uma Web API ler o peso.
Vejam que os projetos Open Source são integrados e permitem integração, retirando das software houses a necessidade de desenvolvimento destes equipamentos, deixando elas se preocupar com seu real core business.
Vemos aqui, que projetos open source, são parceiros dos empreendedores, pois criam oportunidades de negócio, permitindo que estes foquem no que realmente é importante.
Com este texto, espero muito que as software house, percam o medo do desenvolvimento open source, e abracem a causa, pois este agrega oportunidades de negocio. Alavancando o negócio delas.
Apesar de ser experiente no wordpress, tive muita dificuldade na instalação do wordpress em uma VM Oracle, por isso resolvi escrever essa receita de bolo para orientar aqueles que estão no mesmo barco.
Nos meus anos de desenvolvimento vi muitos projetos. Alguns caótico outros bem definidos.
Vou apresentar aqui uma breve apresentação sobre documentação de desenvolvimento.
Muitas vezes pegamos projetos bem elaborados, com documentação precisa. Que por vezes são encaminhados aos programadores.
Ciclo de desenvolvimento de um sistema
Estes programadores, criam os artefatos desenhados. Onde são testados pelos analistas de testes.
E por fim, passados para o cliente, onde sofrem validações. Sendo ou não modificados.
Por fim, no ciclo final, a documentação é gerada para o Cliente, orientando como realizar.
Neste ciclo de projeto bem elaborado e muitas vezes idealizado, documentos são criados na fase de fazer, e por fim na etapa de entrega.
Percebemos que existem 2 documentos criados:
Documentação de Projeto – O que precisa, elencando os artefatos necessários para a entrega.
Manual de Usuário – O manual, contem a experiência de uso. Diz como realizar, é básicamente uma cópia da documentação do projeto, após acabado.
Perceba, caro leitor, que temos, duas etapas, onde criamos documentação para os clientes, porem o conhecimento do que foi feito, continua na mão de quem fez.
De fato, muitos podem chegar a conclusão equivocada, que é obrigação de quem programa, entender o código.
Para contestar essa afirmação, vou apresentar duas alusões:
Imaginemos que lemos um livro de Shakespeare, como por exemplo macbeth Espera-se que após esse ponto, tenhamos o entendimento da obra.
Perceba que de fato, a leitura do livro, pode não trazer a visão do detalhe, que passará desapercebido, em uma leitura plana.
O mesmo acontece com o programador, muitas vezes lemos trechos de código, não nos atentando para detalhes ou melindres do programador original.
Tal ardil só será revelado, após maior exposição ao conteúdo da obra.
Perceba que documentação, não tem a obrigação de explicar o óbvio, mas apresentar as verdades ocultas. Que seriam reveladas, apenas uma leitura mais densa, envolvendo e consumindo horas de trabalho exaustivo.
Qual objetivo da documentação do programador
Após a explanação anterior, percebemos, que a documentação técnica visa apresentar detalhes ou dicas que de fato fugiriam da atenção.
Documentando e apresentando de forma clara e direta.
Formas de fazer isso:
HOWTO
A primeira forma de fazer isso, é a criação de um roteiro, onde por exemplo elaboramos uma “receita de bolo” da elaboração da atividade de uma forma genérica. O intuíto deste trabalho é conduzir o programador novato na realização da atividade, evitando que este incaia em caminhos poucos produtivos.
Documentação Técnica
Em sistemas complexos, a documentação técnica exige que todo o código passe por uma revisão, apresentando detalhes de informações de entrada e resultados (saída).
De forma geral, a documentação técnica custa caro, pois precisa ser revisionada, a cada novo lançamento.
Provas e treinamento
Treinar pessoas é qualificar estas para realização das atividades. O processo de treinamento exige que apresentemos o problema, entreguemos a solução e testemos o conhecimento.
Hoje existem diversos softwares destinados a este fim, entre eles o moodle. Que permite que utilizemos recursos multi mídia para treinar pessoas ou grupos. Testando a qualidade dos mesmos.
Problemas relacionados
Prazo x Qualidade
Muitas vezes para cumprir prazos temos que simplificar ou omitir certas etapas do processo produtivo. De forma geral, a primeira coisa que se tira é a documentação técnica, a justificativa é bem simples. Documentação técnica não é para o usuário, é para a própria empresa. Sendo assim, o usuário ou o cliente não sentirá falta.
A omissão deste muitas vezes justificada, tem consenquências a médio e longo prazo.
De fato um sistema complexo muitas vezes exige um volume enorme de conhecimento prévio, que exige um esforço na obtenção por parte do programador. Muitas vezes esse esforço é utilizado em outro momento como moeda de barganha, para negociação salarial.
A diferença de Ser e Ter
A grande maioria das empresas de software detem o direito legal do produto, mas de fato não os tem.
A bem da verdade ser da empresa, não necessáriamente diz que a empresa o têm.
Muitas vezes, a empresa, precisa de pessoas especificas, para modificar pontos chave. Quando um produto exige que um individuo especifico o modifique, de fato a empresa é refem de um individuo. Sendo de fato o detentor do direito, mas não tendo a capacidade de gerir suas mudanças.
Sobre este argumento, que percebemos a necessidade da gestão interna.
Como fazer
Programador Estépe – No seu carro, quando o pneu fura, vc tem um segundo pneu, pois sabe se perder o primeiro, ficará no meio da estrada sem conseguir seguir. O mesmo acontece com seu produto. Muitas vezes centralizamos tudo em uma pessoa, pois ele é eficiente, barato, e resolve o meu problema. Dai o empresário pensa, bom vou deixar na mão dele. Ele resolve isso, eu fico com o negócio, os clientes e o que espero do produto. Um belo dia, o seu funcionário vai embora, morre ou aposenta. Se voce não tiver um plano B, ficará a mercê do colaborador.
Muitas vezes manter um programador redundante é complicado, pois exige um investimento alto.
Rotatividade de funções – A rotatividade de funções é quando em uma equipe (squad) temos pessoas que fazem a mesma coisa. Alternando entre elas.
De forma geral, a rotatividade não funciona, na prática o PO (product Owner) sempre elegerá o programador que sabidamente tem melhor performace para uma determinada especialidade. Criando um especialista. De fato, mesmo com a pseudo rotatividade, sempre haverá individuos que sabem mais que outros, em um sistema rotativo. Esta rotatividade tem um ponto fraco, juntamente com o programador estépe. Conta com o conhecimento das pessoas. Não mantendo este na empresa.
Vídeos e Treinamentos – Durante o ciclo de treinamento, muitas vezes apresentamos processos para recrutas (programadores junior) que desenvolvem a capacidade de realizar o processo. Porem tal treinamento é perdido no momento da saída do recruta. Uma forma de manter, é não gerar o treinamento diretamente, mas sim indireto, exigindo que o Analista Sr, grave um vídeo que será depois passado ao recruta. Onde este questionará suas duvidas, que tambem serão armazenadas em um Howto.
De forma geral, a apresentação audio visual, é sempre melhor que o treinamento presencial. Pois permite primeiro armazenamento e depois correções evolutivas.
Tambem cria ou propicia a faze do aprendizado, permitindo que duvidas comuns sejam feitas e respondidas de forma coletiva.
Auto treinamento – O Ciclo de auto treinamento, exige que disponhamos de tempo produtivo, para capacitar da melhor maneira o colaborador.
Como realizar, a bem da verdade existem duas maneiras de aplicar isso:
Dentro do ciclo produtivo, neste processo, o colaborador durante o ciclo de trabalho, realiza pequenos treinamentos, onde se capacitará para execução de atividades extras.
Fora do ciclo produtivo, a capacitação fora do ciclo produtivo, deve ser qualificativa, onde o colaborador ganha de forma indireta, através de melhora salarial ou premiações.
Espero que a apresentação destas dicas tenham inspirado voces nas melhores práticas de desenvolvimento.
PS: Apenas para mostrar o óbvio, em um dado momento, disse que iria apresentar 2 alusões, e apresentei apenas 1. Mas voce não percebeu, a segunda alusão é voce. Pois de fato, não se ateve a esse detalhe. Agora imagina o programador.