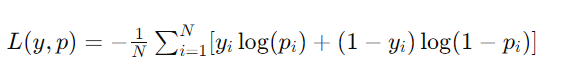Vivemos em uma era em que a quantidade de dados gerados diariamente é imensa. Empresas, organizações e até mesmo indivíduos têm acesso a uma quantidade sem precedentes de informações. No entanto, a grande questão é: como podemos aproveitar ao máximo esses dados para obter insights valiosos?
É aí que entra o Kaggle, uma plataforma online que se tornou referência quando se trata de análise de dados. O Kaggle é um verdadeiro tesouro para cientistas de dados, entusiastas e profissionais que buscam dados confiáveis e diversificados.
O que é o Kaggle?
O Kaggle é uma comunidade online que reúne cientistas de dados e entusiastas de todo o mundo. Seu principal objetivo é fornecer um espaço onde as pessoas possam compartilhar, colaborar e competir em projetos de análise de dados.
Uma das características mais interessantes do Kaggle é a sua vasta coleção de conjuntos de dados. Esses conjuntos são disponibilizados por empresas, organizações governamentais e até mesmo por outros membros da comunidade. Isso significa que você pode encontrar dados sobre praticamente qualquer assunto que possa imaginar.
Como usar o Kaggle?
Para começar a usar o Kaggle, basta visitar o site https://www.kaggle.com/ e criar uma conta gratuita. Depois de fazer isso, você terá acesso a uma variedade de recursos e ferramentas.
Uma das principais vantagens de usar o Kaggle é a capacidade de participar de competições de análise de dados. Essas competições são uma ótima maneira de testar suas habilidades e aprender com outros membros da comunidade. Além disso, elas muitas vezes oferecem prêmios em dinheiro ou oportunidades de emprego para os melhores colocados.
Outro recurso interessante do Kaggle é o Kernels. Os Kernels são notebooks interativos que permitem que você crie, execute e compartilhe código Python. Isso é especialmente útil para aqueles que estão começando na área de análise de dados e desejam aprender com exemplos práticos.
Por que usar o Kaggle?
O Kaggle é uma ferramenta poderosa para qualquer pessoa interessada em análise de dados. Aqui estão algumas razões para considerar o uso dessa plataforma:
Ampla variedade de conjuntos de dados: o Kaggle oferece uma enorme quantidade de dados sobre os mais diversos temas, permitindo que você encontre exatamente o que precisa para o seu projeto.
Comunidade ativa: o Kaggle é frequentado por uma comunidade de cientistas de dados e entusiastas que estão sempre dispostos a compartilhar conhecimento e ajudar uns aos outros.
Recursos educacionais: além das competições e Kernels, o Kaggle também oferece cursos e tutoriais gratuitos para quem deseja aprender mais sobre análise de dados.
Em resumo, o Kaggle é uma plataforma essencial para quem trabalha com análise de dados. Seja você um cientista de dados experiente ou apenas um entusiasta, o Kaggle oferece uma infinidade de recursos e oportunidades para aprimorar suas habilidades e encontrar os dados necessários para seus projetos.
Este é um roteiro de instalação e preparação do seu UBUNTU para rodar o kinect.
O Kinect é parte integrante do XBOX 365, que apesar de já bem antigo (2024) ainda é uma tecnologia disruptiva, trazendo muitos benefícios para quem trabalha com IA e processamento de imagem.
O intuito deste tutorial é demonstrar o que é necessário para rodar o kinect no PC com linux.
Hardware
Logicamente, o kinect 365 é necessário.
Porem não somente ele, o hardware foi construído para o XBOX e possui um conector proprietário, que precisa alem de um adaptador, também de fonte externa para o PC.
Voce pode facilmente encontrar este adaptador se procurar “adaptador kinect xbox PC” em qualquer site de compras.
Software
Existe um pacote para linux que permite rodar o kinect, é o libfreenect.
Se olharmos na lista de repositórios do ubuntu por freenect, encontraremos os seguintes pacotes:
freenect – library for accessing Kinect device — metapackage
libfreenect-bin – library for accessing Kinect device — utilities and samples
libfreenect-demos -library for accessing Kinect device — dummy package
libfreenect-dev – library for accessing Kinect device — development files
libfreenect-doc – library for accessing Kinect device — documentation
libfreenect0.5 – library for accessing Kinect device
Para instalar esses pacotes siga o roteiro, instalando primeiro os pacotes requeridos.
Existe um conjunto de demos que foram criados para permitir usar o kinect. Vamos entender cada um.
freenect-camtest: Uma ferramenta de teste para verificar o funcionamento básico das câmeras RGB e de profundidade do Kinect.
freenect-chunkview: Utilitário para visualizar dados de “chunk” (pedaço), útil para debugar ou entender como os dados são transferidos do Kinect.
freenect-cpp_pcview: Um visualizador de nuvem de pontos escrito em C++, demonstrando como processar e visualizar dados de profundidade em 3D.
freenect-cppview: Similar ao freenect-cpp_pcview, oferece uma visualização básica da saída RGB e de profundidade usando C++.
freenect-glview: Provavelmente um dos exemplos mais usados, oferece uma visualização ao vivo simples das câmeras RGB e de profundidade usando OpenGL.
freenect-glpclview: Uma ferramenta avançada para visualizar a saída do Kinect como uma nuvem de pontos 3D, utilizando a biblioteca PCL (Point Cloud Library) e OpenGL para renderização.
freenect-hiview: Uma ferramenta de visualização que pode ser usada para exibir dados de alta resolução do Kinect.
Teste com freenect-glview
Demonstra o uso do kinect.
No nosso próximo artigo, irei demonstrar o uso do kinect, e fazer um exemplo de código em C.
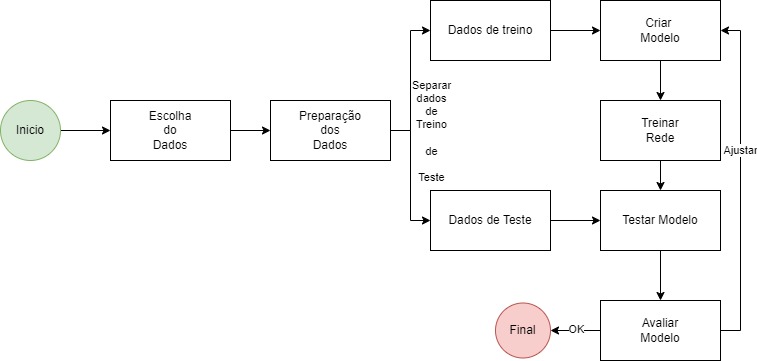
Neste fluxo bem simplificado, apresentamos uma visão de criação de uma IA.
Na primeira etapa, escolhemos os dados e entendemos a qualidade e características desses dados.
Em projetos de IA, nem sempre temos prontos os dados, muitas vezes precisamos preparar e coletar tais dados.
Em um segundo faz a preparação dos dados, acertando problemas e ajustando os dados. Na vida real, é praticamente impossível pegar bases prontas de clientes. Muitas vezes as bases de clientes, exigem uma analise e pré processamento, para realizar ajustes ou cortes. Necessários para obter dados coerentes com que queremos analisar.
A próxima etapa é separar dados em treinamento e testes. Onde usa-se o bom senso para avaliar as escolhas dos dados. Sendo uma referencia 70 /30% , onde 70 % dos itens serão utilizados para treinamento e os demais, serão usados para teste. Levando sempre em consideração a diversidade dos dados tanto para testes, como para treinamentos. A escolha aleatória dos 30% garante uma melhor probabilidade de sucesso, pois evita selecionar modelos com caracteristicas próximas , que podem iludir ou derrubar as estatísticas dos resultados.
Treinamento
O treinamento consiste em pegar os dados e aplicar a um modelo de IA conhecido, podendo ser NLP , redes convulocionais, ou outros tipos como Grafos.
Nesta etapa cria-se as estruturas e linguagem necessária para gerar a rede treinada.
Testes ou Validação
Nesta etapa usa-se os dados para gerar as informações separadas para validar a rede criada.
Analisando os resultados a partir de respostas conhecidas.
Melhoria ou Validação
A partir da analise dos resultados, são de fato, avaliados duas decisões:
Finalização do projeto ou etapa
Retorno a etapa de codificação, ajustando técnicas ou processos para corrigir problemas identificados.
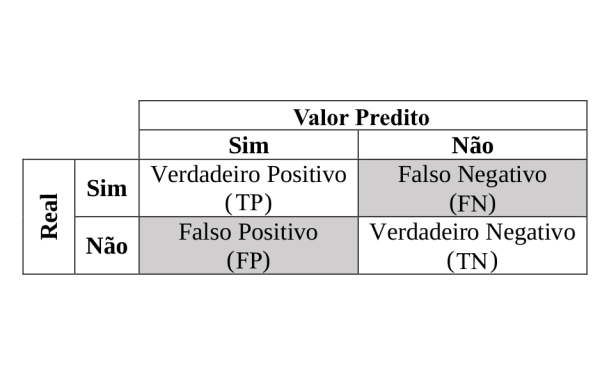
r = Sensibilidade (Sensivity) ou Repescagem (RECALL)
Logarithmic Loss (Perda Logarítmica)
A perda logarítmica, também conhecida como log loss ou cross-entropy loss, é uma medida de desempenho usada em problemas de classificação, especialmente em classificações binárias e multiclasse. Essa métrica quantifica quão distantes estão as probabilidades previstas de um modelo em relação aos valores verdadeiros ou reais (0 ou 1). A ideia é penalizar não apenas as classificações incorretas, mas também a confiança errada nas previsões.
Para uma previsão perfeita, a perda logarítmica é 0, e ela aumenta à medida que a previsão se afasta do valor real. Um aspecto importante da perda logarítmica é que ela penaliza severamente as previsões que estão confiantemente erradas. Por exemplo, uma previsão errada com alta certeza (por exemplo, prever a probabilidade de uma classe como 0.9 quando a classe verdadeira é a outra) resultará em uma penalidade maior do que uma previsão errada com baixa certeza.
A fórmula para a perda logarítmica em classificação binária é dada por:
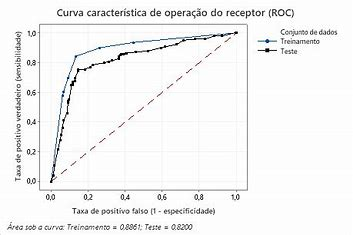
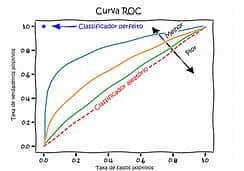
Receiver Operator Characteristic (ROC)
A Característica de Operação do Receptor (ROC, do inglês “Receiver Operating Characteristic”) é uma ferramenta utilizada para avaliar o desempenho de modelos de classificação binária. Ela é representada graficamente por uma curva que compara a taxa de verdadeiros positivos (sensibilidade) com a taxa de falsos positivos (1 – especificidade), para diferentes limiares de decisão.
A área sob a curva ROC (AUC, do inglês “Area Under the ROC Curve”) é um indicador da capacidade do modelo de discriminar entre as duas classes. Um valor de AUC igual a 1 indica um modelo perfeito, capaz de separar completamente as duas classes sem erros. Um valor de AUC igual a 0,5 sugere um desempenho não melhor do que o acaso, ou seja, o modelo não tem capacidade de discriminação entre as classes.
A curva ROC é particularmente útil porque permite a avaliação do desempenho do modelo em diferentes limiares, facilitando a escolha de um ponto de corte que equilibre entre a captura de verdadeiros positivos e a minimização de falsos positivos, de acordo com o contexto e os custos associados a cada tipo de erro.
AUC – Area Under Curve
AUC, que significa “Área Sob a Curva”, é um termo amplamente utilizado em análise de dados e machine learning, especialmente quando se refere à Curva ROC (Característica de Operação do Receptor). A AUC é uma métrica que quantifica o desempenho geral de um modelo de classificação, independentemente do limiar de decisão aplicado.
Características Principais da AUC
Avaliação de Desempenho: A AUC mede a capacidade do modelo de discriminar entre classes positivas e negativas. Um modelo com uma AUC de 1.0 é considerado perfeito, capaz de separar perfeitamente as duas classes. Um modelo com uma AUC de 0.5 não tem capacidade de discriminação, equivalente a um palpite aleatório.
Independente do Limiar: A AUC é particularmente útil porque é independente do ponto de corte escolhido. Isso significa que ela fornece uma medida do desempenho do modelo que não é afetada pela seleção de um limiar específico para a classificação de positivos e negativos.
Comparação de Modelos: A AUC permite comparar o desempenho de diferentes modelos de classificação diretamente. Um modelo com uma AUC maior é geralmente considerado melhor na discriminação das classes.
Aplicável em Diversos Contextos: Embora frequentemente associada à Curva ROC, o conceito de AUC pode ser aplicado a outras curvas, como a Curva Precision-Recall, especialmente em contextos onde as classes são muito desbalanceadas.
Limitações
Não Capta Todas as Dimensões de Desempenho: Embora a AUC forneça uma medida útil do desempenho geral de um modelo, ela não captura todas as nuances, como o equilíbrio entre sensibilidade e especificidade ou a precisão das previsões positivas (precisão).
Desbalanceamento de Classes: Em situações com desbalanceamento acentuado de classes, a AUC pode ser enganosa, sugerindo um desempenho melhor do que o modelo realmente apresenta, especialmente se a preocupação é com a precisão da classificação da classe minoritária.
Conclusão
A AUC é uma métrica valiosa para avaliar e comparar modelos de classificação, oferecendo uma visão geral da capacidade do modelo de discriminar entre classes. Contudo, é importante considerá-la junto a outras métricas para obter uma avaliação completa do desempenho do modelo.
Uso da biblioteca spacy para pesquisa de caracteres usando matcher.
#!pip install spacy
import spacy
import spacy.util
from spacy.matcher import Matcher
# Verifica se o modelo 'pt_core_news_sm' está instalado
if not spacy.util.is_package("pt_core_news_sm"):
# Se não estiver instalado, baixa o modelo
!python -m spacy download pt_core_news_sm
else:
print("Modelo 'pt_core_news_sm' já está instalado.")
# Carrega o modelo de linguagem do spaCy
nlp = spacy.load("pt_core_news_sm")
# Cria o objeto Matcher e o vincula ao vocabulário do modelo de linguagem
matcher = Matcher(nlp.vocab)
def ContarOcorrenciasPalavra(palavra, lista_textos):
# Ajusta a palavra para lowercase
palavra = palavra.lower()
total_ocorrencias = 0
# Define o padrão para procurar a palavra, considerando a correspondência de texto exato em lowercase
pattern = [{"TEXT": palavra}]
matcher.add("PADRAO", [pattern])
# Converte o texto para lowercase e processa com o spaCy
doc = nlp(lista_textos.lower())
matches = matcher(doc)
# Para cada correspondência encontrada, imprime detalhes
for match_id, start, end in matches:
matched_span = lista_textos[start:end]
print(f"Achou no Texto: {lista_textos}; Palavra: '{matched_span}' na POS: {start} até {end}")
total_ocorrencias += 1
return total_ocorrencias
textos = ["Neste exemplo de caso de uso.", "São exemplos de figura de linguagem aplicadas ao exemplo.", "Este exemplo possui um erro semantico.", "Tal qual o exemplo a seguir."]
for texto in textos:
print("Texto:"+texto)
ContarOcorrenciasPalavra("exemplo",texto)
ContarOcorrenciasPalavra("uso",texto)
ContarOcorrenciasPalavra("figura",texto)
ContarOcorrenciasPalavra("aplicadas",texto)
Saída do programa ao rodar
Texto:Neste exemplo de caso de uso.
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Texto:São exemplos de figura de linguagem aplicadas ao exemplo.
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Texto:Este exemplo possui um erro semantico.
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Texto:Tal qual o exemplo a seguir.
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4