Grafos Teoria e Prática – Parte II
11 de setembro de 2023Neste segundo artigo irei utilizar os grafos para realizar uma pesquisa.
Para isso usarei partes do projeto já criado.
Se você não viu o primeiro artigo, recomendo que veja ele primeiro:
Este segundo artigo é mais prático, então vamos a mão na massa!
Criando conexão:
import mysql.connector
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words('portuguese'))
# Configuração da conexão com o banco
DB_CONFIG = {
"host": "localhost",
"user": "username",
"password": "password",
"database": "graph_db"
}
"""Cria arestas com base em frases de exemplo."""
frases = [
"Comece a gravação de áudio",
"Salve esse texto importante",
"Defina um alerta para amanhã",
"Quero a gravação dessa reunião",
"Salve a anotação rapidamente"
]
comandos = [
"Iniciar gravação",
"Salvar texto",
"Configurar alerta",
"Iniciar gravação",
"Salvar anotação"
]
#Treinamento e teste
matriz = [
["Comece a gravar agora", "Iniciar gravação"],
["Inicie a gravação do áudio", "Iniciar gravação"],
["Por favor, ative a gravação", "Iniciar gravação"],
["Vamos começar a gravação", "Iniciar gravação"],
["Quero que comece a gravar", "Iniciar gravação"],
["Dê início à gravação", "Iniciar gravação"],
["Preciso gravar isso", "Iniciar gravação"],
["Vamos gravar essa conversa", "Iniciar gravação"],
["Inicie a captação do áudio", "Iniciar gravação"],
["Gostaria de gravar este momento", "Iniciar gravação"],
["Por gentileza, inicie a gravação", "Iniciar gravação"],
["Capture esse áudio", "Iniciar gravação"],
["Quero guardar esse som", "Iniciar gravação"],
["Vamos documentar esse áudio", "Iniciar gravação"],
["Grave essa sessão", "Iniciar gravação"],
["Desejo registrar esse som", "Iniciar gravação"],
["Vamos dar start na gravação", "Iniciar gravação"],
["Por favor, comece a gravar", "Iniciar gravação"],
["Gostaria de iniciar a gravação", "Iniciar gravação"],
["Desejo capturar este áudio", "Iniciar gravação"],
["Preserve este texto", "Salvar texto"],
["Quero guardar essa informação", "Salvar texto"],
["Salve estas palavras", "Salvar texto"],
["Documente este conteúdo", "Salvar texto"],
["Registre esta informação", "Salvar texto"],
["Gostaria de salvar este documento", "Salvar texto"],
["Por favor, salve esse texto", "Salvar texto"],
["Desejo guardar este conteúdo", "Salvar texto"],
["Capture esta informação em texto", "Salvar texto"],
["Guarde essa anotação", "Salvar texto"],
["Defina um alarme para 9h", "Configurar alerta"],
["Quero ser alertado às 10h", "Configurar alerta"],
["Lembre-me de algo às 11h", "Configurar alerta"],
["Ative um lembrete para o meio-dia", "Configurar alerta"],
["Preciso de um alerta para as 13h", "Configurar alerta"],
["Por favor, configure um alerta para 14h", "Configurar alerta"],
["Quero ser notificado às 15h", "Configurar alerta"],
["Defina um lembrete para 16h", "Configurar alerta"],
["Lembre-me disso às 17h", "Configurar alerta"],
["Configure um alerta para 18h", "Configurar alerta"],
["Faça uma nota disto", "Salvar anotação"],
["Quero que isso fique registrado", "Salvar anotação"],
["Documente esta observação", "Salvar anotação"],
["Anote isto, por favor", "Salvar anotação"],
["Preserve esta anotação", "Salvar anotação"],
["Por favor, faça uma nota sobre isso", "Salvar anotação"],
["Desejo que isso seja anotado", "Salvar anotação"],
["Guarde este registro", "Salvar anotação"],
["Capture esta nota", "Salvar anotação"],
["Quero esta informação documentada", "Salvar anotação"],
]Agora criamos a função de conexão com banco de dados:
def connect_to_database():
"""Retorna uma conexão com o banco de dados."""
return mysql.connector.connect(**DB_CONFIG)Eu pedi ao chatGPT criar a matriz estática contendo variações de solicitações de comando.
Desta forma poderia apresentar o texto e testar os resultados.
Lembrando que como uso grafos duplamente ligados, a qualidade dos resultados depende muito do treinamento.
matriz_teste = [
["Dê início à captura de som", "Iniciar gravação"],
["Gostaria de ouvir isso depois", "Iniciar gravação"],
["Por gentileza, registre este momento", "Iniciar gravação"],
["Ative o modo gravação", "Iniciar gravação"],
["Preserve este áudio para mim", "Iniciar gravação"],
["Assegure que este texto esteja seguro", "Salvar texto"],
["Faça uma cópia deste conteúdo", "Salvar texto"],
["Deixe este texto registrado", "Salvar texto"],
["Fixe esta informação", "Salvar texto"],
["Quero ter este texto para depois", "Salvar texto"],
["Estabeleça um aviso para 19h", "Configurar alerta"],
["Preciso ser lembrado às 20h", "Configurar alerta"],
["Por favor, defina um bip para 21h", "Configurar alerta"],
["Quero um aviso sonoro para as 22h", "Configurar alerta"],
["Faça um lembrete vibrar às 23h", "Configurar alerta"],
["Gostaria de ter isso em minhas notas", "Salvar anotação"],
["Anote isto para mim", "Salvar anotação"],
["Mantenha esta informação como uma nota", "Salvar anotação"],
["Quero isto em formato de anotação", "Salvar anotação"],
["Por favor, transforme isso em uma nota", "Salvar anotação"]
]
No artigo anterior, criamos apenas algumas frases para popular nossa base.
Iremos modificar um pouco nosso programa
Nas palavras vamos incluir a opção de cadastro, porem se já existir ja passamos o ID:
# Função para cadastrar palavras
def CadastraWords(word_name):
connection = connect_to_database()
cursor = connection.cursor()
# Verifica se a palavra já está cadastrada
cursor.execute("SELECT word_id FROM words WHERE word_name = %s", (word_name,))
result = cursor.fetchone()
if result:
return result[0]
cursor.execute("INSERT INTO words (word_name) VALUES (%s)", (word_name,))
connection.commit()
word_id = cursor.lastrowid
cursor.close()
connection.close()
return word_idJá na opção de arestas, iremos usar o CadastraWords, conforme apresentado a seguir:
def CriaArestas(Word1, Word2, Cmd):
print(Word1)
print(Word2)
"""Cria uma aresta associando Word1 e Word2 ao comando Cmd."""
#word1_id = get_id_words(Word1, "word_name")
#word2_id = get_id_words(Word2, "word_name")
word1_id = CadastraWords(Word1)
word2_id = CadastraWords(Word2)
cmd_id = get_id_commands(Cmd, "command_name")
print(word1_id);
print(word2_id);
print(cmd_id);
if not word1_id or not word2_id or not cmd_id:
print("Erro: Um ou mais valores não foram encontrados no banco de dados.")
return
connection = connect_to_database()
cursor = connection.cursor()
insert_query = """
INSERT INTO edges (word_id1, word_id2, command_id)
VALUES (%s, %s, %s)
"""
try:
cursor.execute(insert_query, (word1_id, word2_id, cmd_id))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir aresta: {err}")
cursor.close()
connection.close()Por fim iremos incluir nos grafos os itens do treinamento:
Função para popular com dados de teste
Nela criamos e povoamos os 200 testes.
# Função para popular com dados de teste
def Popula_Teste():
stop_words = set(stopwords.words('portuguese'))
for item in matriz_teste:
frase, comando = item
words = word_tokenize(frase, language="portuguese")
filtered_words = [w for w in words if w.lower() not in stop_words and w.isalpha()]
for i in range(len(filtered_words) - 1):
CriaArestas(filtered_words[i], filtered_words[i + 1], comando)
Agora iremos chamar a função e testar:
Popula_Teste()Primeiros Testes
Agora iremos utilizar nossa matriz de teste (matriz_teste) para aferir quais os resultados que ele acha. Lembrando que para realizar tal façanha usamos novos códigos.
Nesta primeira função testamos o resultado, individualmente.
def Teste_Validacao(Frase, comando):
stop_words = set(stopwords.words('portuguese'))
connection = connect_to_database()
cursor = connection.cursor()
# Tokenize e limpe a frase
words = word_tokenize(Frase, language="portuguese")
filtered_words = [w.lower() for w in words if w.lower() not in stop_words and w.isalpha()]
# Obtenha o ID do comando
cursor.execute("SELECT command_id FROM commands WHERE command_name = %s", (comando,))
command_id = cursor.fetchone()
if not command_id:
return "Comando não encontrado."
command_id = command_id[0]
# Verifique a presença de pares de palavras na tabela edges
total_matches = 0
for i in range(len(filtered_words) - 1):
cursor.execute("""SELECT COUNT(*) FROM edges
WHERE word_id1 = (SELECT word_id FROM words WHERE word_name = %s)
AND word_id2 = (SELECT word_id FROM words WHERE word_name = %s)
AND command_id = %s""", (filtered_words[i], filtered_words[i + 1], command_id))
total_matches += cursor.fetchone()[0]
# Matriz de confusão: [Predicted True, Predicted False; Actual True, Actual False]
confusion_matrix = [[0, 0], [0, 0]]
if total_matches > 0: # Se houver combinações, assuma que a previsão é verdadeira
confusion_matrix[0][0] = 1
else: # Se não houver combinações, assuma que a previsão é falsa
confusion_matrix[1][1] = 1
cursor.close()
connection.close()
return confusion_matrixNeste segundo, usamos a matriz para criar uma matriz de confusão:
def plot_confusion_matrix(confusion_matrix, classes, title='Matriz de Confusão', cmap=plt.cm.Blues):
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix, annot=True, cmap=cmap, fmt='g', xticklabels=classes, yticklabels=classes)
plt.ylabel('Comando verdadeiro')
plt.xlabel('Comando previsto')
plt.title(title)
plt.show()
def Testa_Validacao():
conn = connect_to_database()
cursor = conn.cursor()
# Lista de stopwords em português
stop_words = set(stopwords.words('portuguese'))
confusion_matrix = np.zeros((len(comandos), len(comandos)))
for item in matriz_teste:
frase, comando_verdadeiro = item
# Processa a frase: remove stopwords, converte para minúsculo
palavras = [word for word in frase.lower().split() if word not in stop_words and not word.isdigit()]
# Encontre os IDs das palavras
word_ids = []
for palavra in palavras:
cursor.execute("SELECT word_id FROM words WHERE word_name = %s", (palavra,))
result = cursor.fetchone()
if result:
word_ids.append(result[0])
# Encontre a aresta com maior frequência baseada nas palavras
comando_previsto = None
max_count = -1
for i in range(len(word_ids)-1):
cursor.execute("""
SELECT command_id, COUNT(*) as freq
FROM edges
WHERE word_id1 = %s AND word_id2 = %s
GROUP BY command_id
ORDER BY freq DESC
LIMIT 1
""", (word_ids[i], word_ids[i+1]))
result = cursor.fetchone()
if result and result[1] > max_count:
comando_previsto = result[0]
max_count = result[1]
if comando_previsto:
# Converte o ID do comando para nome
cursor.execute("SELECT command_name FROM commands WHERE command_id = %s", (comando_previsto,))
result = cursor.fetchone()
if result:
comando_previsto_name = result[0]
confusion_matrix[comandos.index(comando_verdadeiro)][comandos.index(comando_previsto_name)] += 1
conn.close()
# Plota a matriz de confusão
plt.figure(figsize=(10,7))
sns.heatmap(confusion_matrix, annot=True, cmap="YlGnBu", xticklabels=comandos, yticklabels=comandos)
plt.xlabel('Comando Previsto')
plt.ylabel('Comando Verdadeiro')
plt.show()Por fim, chamamos os dados de Testa_Validacao.
Testa_Validacao()
Gerando uma matriz conforme apresentado:
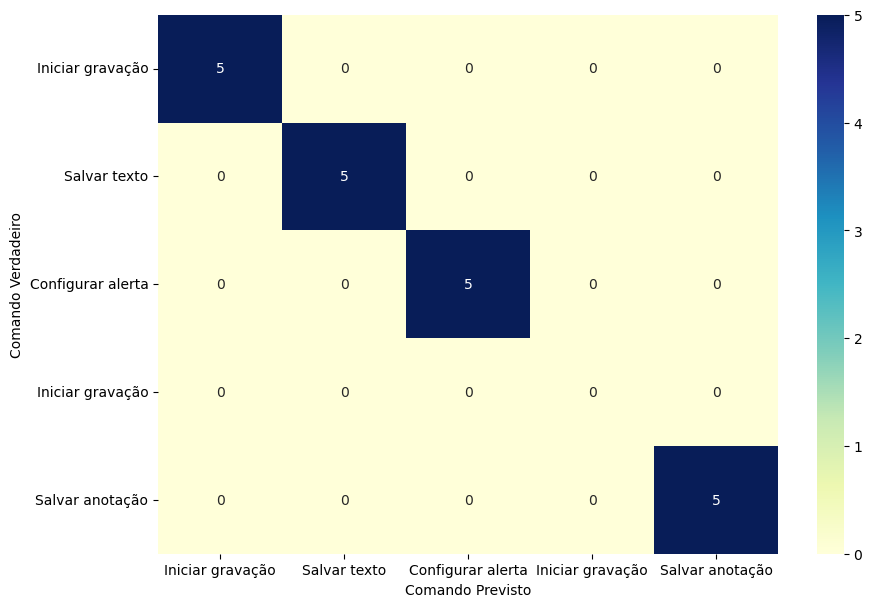
Perceba que a linha diagonal, é o que realmente desejamos. Perceba que houve intencionalmente uma duplicação do iniciar gravação, e que a segunda vez que ele apareceu, os dados não foram mostrados.
A apresentação deste problema pode ocorrer, em especial quando existir muitos grafos e muitos comandos, e seu tratamento será necessário pelo algoritmo que o propuser.
Por fim, para os amantes do fonte de graça, segue a referencia do GITHUB: