Parte do material deste tutorial veio do CHATGPT4.
Origem
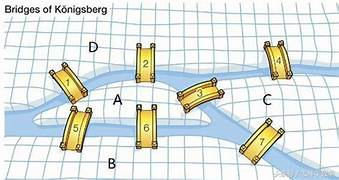
Problema das Pontes de Königsberg (1736): Leonhard Euler demonstrou ser impossível caminhar pela cidade de Königsberg, passando por cada uma das sete pontes exatamente uma vez e retornando ao ponto de partida. Este problema é a origem da teoria dos grafos.
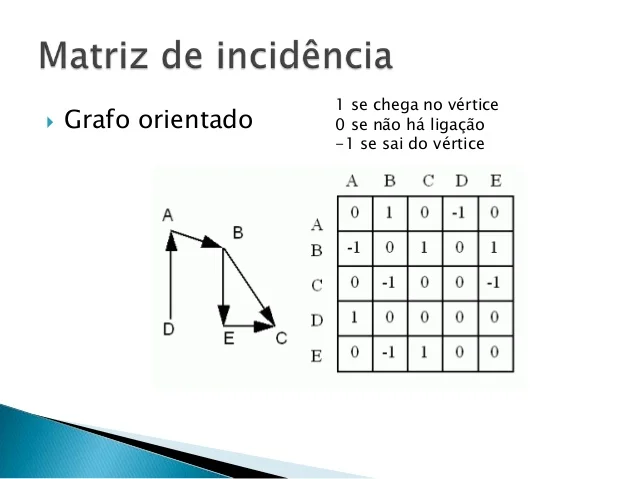
Gustav Kirchhoff: Introduziu a matriz de incidência e estudou árvores abrangentes.
James Joseph Sylvester: Investigou grafos planares.
Teoremas e Problemas Notáveis
Teorema das quatro cores: Qualquer mapa em um plano pode ser colorido com no máximo quatro cores distintas, de modo que regiões adjacentes não tenham a mesma cor. Provado em 1976.
Problema do caixeiro-viajante: Busca o caminho mais curto que visita cada cidade exatamente uma vez, retornando à origem.
Algoritmos de Dijkstra e Floyd-Warshall: Encontram caminhos mais curtos em grafos.
Aplicações Modernas
Século XXI: Uso extensivo da teoria dos grafos em redes sociais, internet das coisas e sistemas complexos.
Essa síntese destaca os marcos e conceitos mais relevantes na evolução da teoria dos grafos.
Elementos dos Grafos
Os grafos são relações entre partes, e podemos entender seus elementos como se segue:
Elementos Básicos de Grafos
Vértices (ou Nós): São as entidades do grafo. Em contextos práticos, podem representar cidades, computadores em uma rede, pessoas em uma rede social, entre outros.
Arestas (ou Ligações): São as conexões entre os vértices. Em um mapa, por exemplo, uma aresta pode representar uma estrada conectando duas cidades.
Grafos Dirigidos vs. Não Dirigidos: Em um grafo dirigido (ou digrafo), as arestas têm uma direção, indo de um vértice para outro. Em grafos não dirigidos, as arestas não têm direção.
Peso: As arestas podem ter um peso associado, que pode representar distâncias, custos, etc.
Implementações
A implementação de um grafo pode ser feita de várias formas, pois é um conceito.
Porem as formas mais comuns são descritos a seguir:
Lista de Adjacência
É uma lista onde, para cada vértice do grafo, armazenamos uma lista de seus vértices adjacentes. É uma forma eficiente de armazenar grafos esparso.
Exemplo em python:
Matriz de Adjacência
A matriz de adjacência é uma das formas mais comuns de representar um grafo em termos de estrutura de dados. Ela utiliza uma matriz bidimensional (um array de arrays) para expressar as relações entre os vértices de um grafo.
Características Básicas
Tamanho da Matriz: Se um grafo tem V vértices, sua matriz de adjacência será de tamanho V×V.
Grafos Não Dirigidos:
Se o vértice i estiver conectado ao vértice j, então matriz[i][j] = 1 (ou o peso da aresta, em grafos ponderados).
Como o grafo é não dirigido, matriz[j][i] também será 1.
Em outras palavras, a matriz é simétrica em relação à sua diagonal principal.
Grafos Dirigidos (Digrafos):
Se existir uma aresta dirigida do vértice i para o vértice j, então matriz[i][j] = 1 (ou o peso da aresta).
Neste caso, a matriz não é necessariamente simétrica.
Grafos Ponderados:
Em vez de conter apenas valores binários (0 ou 1), a matriz contém os pesos das arestas. Se não houver conexão entre dois vértices, um valor padrão (geralmente 0 ou infinito) é usado.
Diagonal Principal: Em muitos grafos, a diagonal principal (matriz[i][i] para todos os i) contém zeros, porque muitos grafos não têm laços (uma aresta que conecta um vértice a si mesmo). Se o grafo permitir laços, o valor na diagonal principal representará a presença (ou o peso) de tal laço.
Vantagens e Desvantagens da Matriz de Adjacência
Vantagens:
Acesso direto: A verificação da existência de uma aresta entre dois vértices é realizada em tempo constante.
Representação intuitiva: É fácil visualizar e entender, especialmente para grafos pequenos.
Desvantagens:
Uso de espaço: Para um grafo com V vértices, é necessário V² espaço, o que pode ser ineficiente para grafos grandes e esparsos.
Iterar sobre os vizinhos: Em um grafo esparso, descobrir os vizinhos de um vértice exige que se verifique toda uma linha ou coluna, o que pode ser ineficiente.
Exemplo
Para o grafo com vértices A,B,C e arestas (A,B),(B,C):
A matriz de adjacência (não ponderada) seria:
A B C
A [0, 1, 0]
B [1, 0, 1]
C [0, 1, 0]
Se este fosse um grafo ponderado, onde a aresta (A,B) tem peso 3 e (B,C) tem peso 2, a matriz seria:
A B C
A [0, 3, 0]
B [3, 0, 2]
C [0, 2, 0]
Exemplo de Solução de Problema de Rota
Apresentaremos um problema de Rota, onde teremos apenas 5 pontes para ir do ponto A ao ponto C.
Nele apresentaremos uma proposta descritiva e depois uma proposta em Python.
Vamos ao grafo dado:
Vértices:A,B,C,D,E Ligações: A−B,B−E,E−C,D−A,B−C
A matriz de adjacência é uma matriz n×n onde n é o número de vértices. A entrada M(i,j) será 1 se o vértice i estiver ligado ao vértice j e 0 caso contrário.
Resolvendo o problema com python
Uma maneira simples de fazer isso é usando uma busca em largura (BFS). Vamos criar um exemplo em Python para isso:
import heapq
def heuristic(node, goal):
# Como um grafo não possui coordenadas espaciais, podemos usar uma heurística trivial.
return 0
def a_star(graph, start, goal):
open_list = [(0, start)]
g_costs = {node: float('inf') for node in range(len(graph))}
g_costs[start] = 0
came_from = {}
while open_list:
current_cost, current_node = heapq.heappop(open_list)
if current_node == goal:
path = []
while current_node in came_from:
path.insert(0, current_node)
current_node = came_from[current_node]
path.insert(0, start)
return path
for neighbor, cost in enumerate(graph[current_node]):
if cost == 1: # Existe uma aresta
tentative_g_cost = g_costs[current_node] + 1
if tentative_g_cost < g_costs[neighbor]:
came_from[neighbor] = current_node
g_costs[neighbor] = tentative_g_cost
f_cost = tentative_g_cost + heuristic(neighbor, goal)
heapq.heappush(open_list, (f_cost, neighbor))
return None
graph = [
[0, 1, 0, 1, 0], # A
[1, 0, 1, 0, 1], # B
[0, 1, 0, 0, 1], # C
[1, 0, 0, 0, 0], # D
[0, 1, 1, 0, 0] # E
]
path = a_star(graph, 0, 2)
if path:
print(" -> ".join(chr(65 + node) for node in path))
else:
print("Não foi encontrado um caminho de A para C.")
Resultado:
A -> B -> C
Outros usos de Grafo:
Outro problema complexo
Agora teremos como objetivo desenvolver um NLP que irá analisar de comandos dados de forma textual, utilizando grafos como base de tomada de decisão.
Para isso temos duas tabelas:
Palavras: Contem uma lista de palavras usadas nos textos.
Comandos: Contem uma lista de comandos possíveis.
Usaremos como exemplo de vértice apenas quando duas palavras em sequencia estiverem atendidas em determinado grafo, ai ligaremos estes aos comandos.
Tabela Palavras:
Esta tabela contém uma lista de palavras chave que podem ser usadas para determinar ações.
Palavras
Grave
Diário
Reproduza
Música
Ligue
Luz
Tabela Ações:
Esta tabela associa sequências de palavras a ações específicas.
Sequência de Palavras
Ação
Grave Diário
Gravação de entradas no diário
Reproduza Música
Tocar música
Ligue Luz
Acender a luz
Neste caso, o grafo seria algo assim:
O vértice “Grave” tem uma aresta direcionada para “Diário”, que representa a ação “Gravação de entradas no diário”.
O vértice “Reproduza” tem uma aresta direcionada para “Música”, representando a ação “Tocar música”.
O vértice “Ligue” tem uma aresta direcionada para “Luz”, representando a ação “Acender a luz”.
A ideia aqui é que, se alguém dissesse “Grave meu Diário”, o sistema reconheceria a sequência “Grave Diário” e acionaria a função correspondente de “Gravação de entradas no diário”. As stop words, como “meu”, seriam ignoradas pelo sistema.
Para implementar isso, você poderia criar um dicionário em Python que mapeia sequências de palavras (arestas) a ações, e então usar esse dicionário para determinar a ação apropriada com base na entrada do usuário.
Passos:
Instalar as bibliotecas necessárias
Configurar o banco de dados
Criar a tabela de arestas no banco de dados
Implementar funções em Python para interagir com o banco de dados
1. Instalar as bibliotecas necessárias
Certifique-se de que você tem o MySQL instalado e em execução. Depois, você pode instalar o conector MySQL para Python:
Crie um novo banco de dados chamado graph_db e um usuário para esse banco de dados. Você pode fazer isso usando a interface de linha de comando do MySQL ou um cliente GUI como o MySQL Workbench.
Criação do Banco
Aqui está uma sugestão de estrutura:
words: Guarda os vértices do tipo palavra.
commands: Guarda os vértices do tipo comando.
edges: Guarda as arestas, referenciando palavras e comandos.
SQL para criação das tabelas:
CREATE DATABASE graph_db;
USE graph_db;
-- Tabela de palavras
CREATE TABLE words (
word_id INT AUTO_INCREMENT PRIMARY KEY,
word_name VARCHAR(50) UNIQUE NOT NULL
);
-- Tabela de comandos
CREATE TABLE commands (
command_id INT AUTO_INCREMENT PRIMARY KEY,
command_name VARCHAR(50) UNIQUE NOT NULL
);
-- Tabela de arestas
CREATE TABLE edges (
edge_id INT AUTO_INCREMENT PRIMARY KEY,
word_id1 INT,
word_id2 INT,
command_id INT,
FOREIGN KEY (word_id1) REFERENCES words(word_id),
FOREIGN KEY (word_id2) REFERENCES words(word_id),
FOREIGN KEY (command_id) REFERENCES commands(command_id)
);
Nesta estrutura:
A tabela words tem um ID único para cada palavra e um nome que é exclusivo.
A tabela commands tem um ID único para cada comando e um nome que é exclusivo.
A tabela edges tem um ID único para cada aresta. As colunas word_id e command_id são chaves estrangeiras que apontam para os IDs nas tabelas words e commands, respectivamente.
Com essa estrutura, a tabela edges representa as relações entre palavras e comandos. Isso significa que cada entrada (linha) na tabela edges é uma relação entre uma palavra específica na tabela words e um comando específico na tabela commands.
Configurando aplicação e Banco de dados
Iremos primeiramente criar as ferramentas basicas para cadastrar as informações e o ambiente.
Então temos a conexão com o banco de dados.
import mysql.connector
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words('portuguese'))
# Configuração da conexão com o banco
DB_CONFIG = {
"host": "localhost",
"user": "your_username",
"password": "your_password",
"database": "graph_db"
}
"""Cria arestas com base em frases de exemplo."""
frases = [
"Comece a gravação de áudio",
"Salve esse texto importante",
"Defina um alerta para amanhã",
"Quero a gravação dessa reunião",
"Salve a anotação rapidamente"
]
comandos = [
"Iniciar gravação",
"Salvar texto",
"Configurar alerta",
"Iniciar gravação",
"Salvar anotação"
]
Criaremos a função de criar a conexão:
def connect_to_database():
"""Retorna uma conexão com o banco de dados."""
return mysql.connector.connect(**DB_CONFIG)
Criamos agora a função de pegar o ID:
def get_id(name, table):
"""Busca o ID de um item pelo nome, na tabela especificada."""
connection = connect_to_database()
cursor = connection.cursor()
column = "word_name" if table == "words" else "command_name"
query = f"SELECT * FROM {table} WHERE {column}=%s"
cursor.execute(query, (name,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
Agora criamos a função que popula as arestas:
def populaArestas(word1, word2, command):
"""Popula a tabela edges com as relações entre palavras e comando."""
connection = connect_to_database()
cursor = connection.cursor()
word1_id = get_id(word1, 'words')
word2_id = get_id(word2, 'words')
command_id = get_id(command, 'commands')
if not word1_id or not word2_id or not command_id:
print(f"Erro: Palavras ou comando não encontrados: '{word1}', '{word2}', '{command}'")
return
insert_query = "INSERT INTO edges (word_id, command_id) VALUES (%s, %s)"
# Inserindo relação da primeira palavra com o comando
cursor.execute(insert_query, (word1_id, command_id))
# Inserindo relação da segunda palavra com o comando
cursor.execute(insert_query, (word2_id, command_id))
connection.commit()
cursor.close()
connection.close()
Agora iremos criar os nossos comandos, para isso temos duas funções:
CadastraCMD que cria o registro de comandos.
ExemploCMD que monta os exemplos que iremos usar.
def cadastreCMD(command_name):
"""Cadastra um novo comando na tabela commands."""
connection = connect_to_database()
cursor = connection.cursor()
insert_query = "INSERT INTO commands (command_name) VALUES (%s)"
try:
cursor.execute(insert_query, (command_name,))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir comando '{command_name}': {err}")
cursor.close()
connection.close()
def ExemploCMD():
for cmd in comandos:
cadastreCMD(cmd)
Agora iremos cadastrar nossas palavras, para isso iremos usar o exemplo a seguir:
CadastraWords – Cadastra a lista de palavras avaliadas nos textos
ExemploWords – Lista as frases, criando as palavras.
Serão implementadas da seguinte forma:
def CadastraWords(word_name):
"""Cadastra uma nova palavra na tabela words."""
connection = connect_to_database()
cursor = connection.cursor()
insert_query = "INSERT INTO words (word_name) VALUES (%s)"
try:
cursor.execute(insert_query, (word_name,))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir palavra '{word_name}': {err}")
cursor.close()
connection.close()
def ExemploWords():
for frase in frases:
palavras = frase.split() # Separa a frase em palavras individuais
for palavra in palavras:
# Ignoramos palavras muito comuns (stop words) e números
if palavra.lower() not in stop_words and not palavra.isnumeric():
CadastraWords(palavra)
Agora iremos criar a função:
get_id_from_Table – Retorna o ID de uma dado valor de uma dada tabela para uma dada coluna.
CriaArestas – Cria a tabela de relacionamento (grafo) de Palavras.
def get_id_words(value, column_name):
"""Retorna o ID associado a um valor em uma coluna e tabela específicos."""
connection = connect_to_database()
cursor = connection.cursor()
select_query = f"SELECT word_id FROM words WHERE {column_name} = %s"
cursor.execute(select_query, (value,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
def get_id_commands(value, column_name):
"""Retorna o ID associado a um valor em uma coluna e tabela específicos."""
connection = connect_to_database()
cursor = connection.cursor()
select_query = f"SELECT command_id FROM commands WHERE {column_name} = %s"
cursor.execute(select_query, (value,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
def CriaArestas(Word1, Word2, Cmd):
print(Word1)
print(Word2)
"""Cria uma aresta associando Word1 e Word2 ao comando Cmd."""
word1_id = get_id_words(Word1, "word_name")
word2_id = get_id_words(Word2, "word_name")
cmd_id = get_id_commands(Cmd, "command_name")
print(word1_id);
print(word2_id);
print(cmd_id);
if not word1_id or not word2_id or not cmd_id:
print("Erro: Um ou mais valores não foram encontrados no banco de dados.")
return
connection = connect_to_database()
cursor = connection.cursor()
insert_query = """
INSERT INTO edges (word_id1, word_id2, command_id)
VALUES (%s, %s, %s)
"""
try:
cursor.execute(insert_query, (word1_id, word2_id, cmd_id))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir aresta: {err}")
cursor.close()
connection.close()
Agora iremos povoar as arestas. Para isso usaremos a função:
ExemploAresta – Faz o cadastro das arestas baseado nas stop-words e palavras não numéricas.
def ExemploAresta():
for index, frase in enumerate(frases):
palavras = [palavra for palavra in frase.split() if palavra.lower() not in stop_words and not palavra.isnumeric()]
for i in range(len(palavras) - 1):
# Criamos arestas entre palavras sequenciais e associamos a um comando
CriaArestas(palavras[i], palavras[i+1], comandos[index])
Juntando tudo
Neste código podemos ver onde tudo se encaixa.
Onde criamos os exemplos, e finalizamos o cadastro.