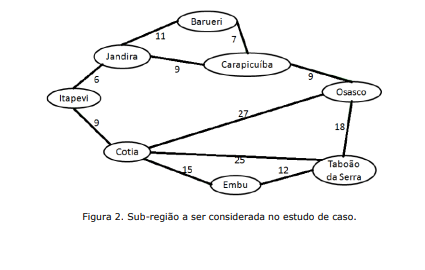
Assim, considerando o grafo da Figura 2, que representa a sub-região circulada na Figura 1, e a tabela heurística da Figura 3, represente o problema (Estado, S, s0, G, A e Matriz de Adjacências) e apresente soluções (caminho e custo em Km) para o problema descrito utilizando os seguintes algoritmos de busca: Menor Custo, Dijkstra (árvore), Melhor Estimativa e A*.
Observação: Para referenciar uma cidade use apenas as três primeiras letras.
Exercício
Usar método de menor custo de Itapevi até Osasco.
Tabela de distância até Osasco em linha reta
Cidade
Distância KM
Barueri
12
Carapicuíba
6
Cotia
17
Embú
15
Itapevi
23
Jandira
18
Osasco
0
Taboão da Serra
8
Estimativa de distância até Osasco
Diagrama de conexões
Conexões e custos associados
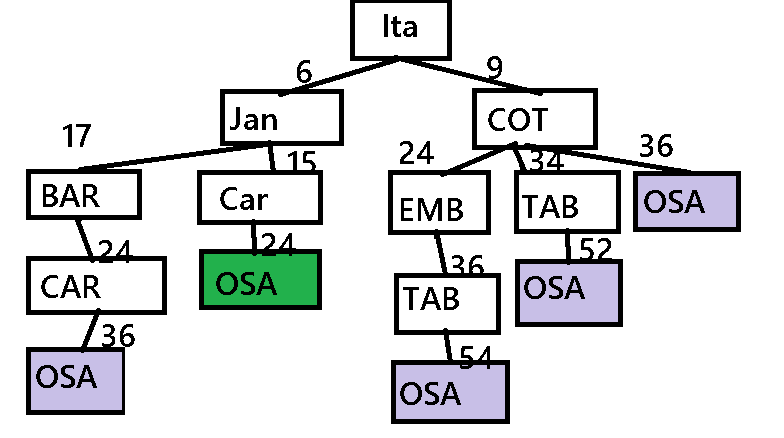
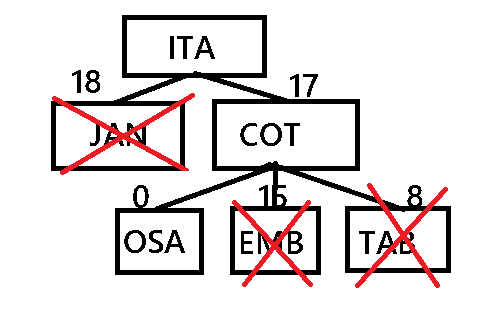
Árvore de busca de menor custo Itapevi/Osasco
Nesta arvore usamos o custo associado de deslocamento, fazendo todas as conexões possíveis.
Ficando definido a melhor rota Itapevi/Jandira/Carapicuíba/Osasco.
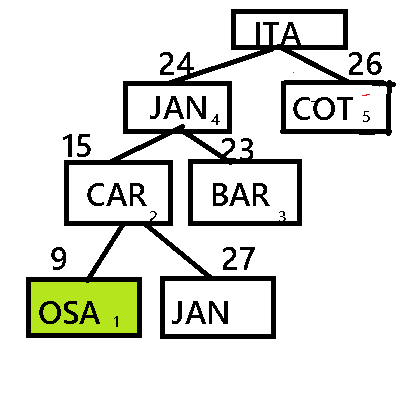
Árvore Dijkstra
Nesta arvore usamos o custo, associado a podas, ignorando os métodos que tem maior custo.
Este método tem podas em Carapicuíba (26) Taboão (36), conforme figura abaixo:
Ficando definido a melhor rota Itapevi/Jandira/Carapicuíba/Osasco.
Árvore Melhor Estimativa
Neste método, usamos a distância até Osasco, pegando sempre a menor distância e ignorando as demais.
Árvore A*
Nesta arvore somamos o custo a distância, criando um valor ficticio. Que será a base da poda.
Aqui iremos mostrar como visualizar as colunas de um data frame carregado.
import pandas as pd
dftotal = pd.read_csv("gasolina-etanol.cvs.gzip",delimiter=";",compression='gzip')
dftotal.columns
O resultado é como demonstrado.
Index(['Região - Sigla', 'Estado - Sigla', 'Município', 'Revenda',
'CNPJ da Revenda', 'Nome da Rua', 'Número Rua', 'Complemento', 'Bairro',
'Cep', 'Produto', 'Data da Coleta', 'Valor de Venda', 'Valor de Compra',
'Unidade de Medida', 'Bandeira'],
dtype='object')
Seguindo o exemplo anterior, a visualização dos dados da Região – Sigla, fica conforme apresentado.
dftotal['Região - Sigla']
Apresentando um resultado, conforme indicado:
0 N
1 N
2 N
3 N
4 N
..
251415 SE
251416 SE
251417 SE
251418 SE
251419 SE
Name: Região - Sigla, Length: 251420, dtype: object
HEAD de data frame
A função head, mostra o cabeçalho das funções, conforme apresentado a seguir.
dftotal.head()
O exemplo apresenta um resultado conforme apresentado a seguir.
Região - Sigla Estado - Sigla Município Revenda CNPJ da Revenda Nome da Rua Número Rua Complemento Bairro Cep Produto Data da Coleta Valor de Venda Valor de Compra Unidade de Medida Bandeira
0 N AC RIO BRANCO AUTO POSTO ISAURAO LTDA 04.594.586/0001-10 RUA ISAURA PARENTE 1412 NaN ESTACAO EXPERIMENTAL 69918-216 GASOLINA ADITIVADA 02/02/2021 5,29 NaN R$ / litro PETROBRAS DISTRIBUIDORA S.A.
1 N AC RIO BRANCO AUTO POSTO ISAURAO LTDA 04.594.586/0001-10 RUA ISAURA PARENTE 1412 NaN ESTACAO EXPERIMENTAL 69918-216 ETANOL 02/02/2021 4,09 NaN R$ / litro PETROBRAS DISTRIBUIDORA S.A.
2 N AC RIO BRANCO AUTO POSTO ISAURAO LTDA 04.594.586/0001-10 RUA ISAURA PARENTE 1412 NaN ESTACAO EXPERIMENTAL 69918-216 GASOLINA 02/02/2021 5,29 NaN R$ / litro PETROBRAS DISTRIBUIDORA S.A.
3 N AC RIO BRANCO COMDEPE COMERCIO DE DERIVADOS DE PETROLEO LTDA 01.198.443/0001-00 AVENIDA NACOES UNIDAS 23 NaN AVIARIO 69909-720 GASOLINA ADITIVADA 02/02/2021 5,29 NaN R$ / litro PETROBRAS DISTRIBUIDORA S.A.
4 N AC RIO BRANCO COMDEPE COMERCIO DE DERIVADOS DE PETROLEO LTDA 01.198.443/0001-00 AVENIDA NACOES UNIDAS 23 NaN AVIARIO 69909-720 GASOLINA 02/02/2021 5,22 NaN R$ / litro PETROBRAS DISTRIBUIDORA S.A.
Média de preço do data frame
No exemplo a seguir usaremos uma média do campo Valor de Venda.
dftotal.mean()
#ou apenas em uma coluna
dftotal['Valor de Venda'].mean()