srvFalar
Foi disponibilizado mais um serviço, agora online de sintetização de voz. Nele é possível fazer a conversão de texto para voz usando o Google API.
Neste projeto apresento duas formas de usar texto para fala, ONLINE e Offline.
Site de documentação da Maurinsoft
Site de documentação da Maurinsoft
Foi disponibilizado mais um serviço, agora online de sintetização de voz. Nele é possível fazer a conversão de texto para voz usando o Google API.
Neste projeto apresento duas formas de usar texto para fala, ONLINE e Offline.
O srvOuve, é um projeto de minha autoria, que permite criar aplicação de Voz para Texto. Neste projeto, iremos utilizar várias abordagens diferentes, para criar uma aplicação para atender essa finalidade.
Neste primeiro projeto finalizado, criamos um serviço de voz para texto que precisa ser online.
https://github.com/marcelomaurin/srvOuve
O projeto srvOuve, permite utilizar diversos serviços diferentes, ouvindo tanto online como offline, unificando assim a forma de obter esses serviços em um único canal.
Permitindo criar integrações mais ageis.
No exemplo do vídeo usamos o MNote como ferramenta de integração. Onde ele recebe o texto “escutado” pelo srvOuve e repassa ao CHATGPT, permitindo assim que esse responda, e depois convertendo em texto de voz, através do srvFalar, outro projeto de minha autoria.

Este é um roteiro de instalação e preparação do seu UBUNTU para rodar o kinect.
O Kinect é parte integrante do XBOX 365, que apesar de já bem antigo (2024) ainda é uma tecnologia disruptiva, trazendo muitos benefícios para quem trabalha com IA e processamento de imagem.
O intuito deste tutorial é demonstrar o que é necessário para rodar o kinect no PC com linux.
Logicamente, o kinect 365 é necessário.

Porem não somente ele, o hardware foi construído para o XBOX e possui um conector proprietário, que precisa alem de um adaptador, também de fonte externa para o PC.

Voce pode facilmente encontrar este adaptador se procurar “adaptador kinect xbox PC” em qualquer site de compras.
Existe um pacote para linux que permite rodar o kinect, é o libfreenect.
Se olharmos na lista de repositórios do ubuntu por freenect, encontraremos os seguintes pacotes:
Para instalar esses pacotes siga o roteiro, instalando primeiro os pacotes requeridos.
sudo apt install build-essential cmake
sudo apt install libusb-1.0-0-dev
sudo apt install python-dev python-numpy
sudo apt install swig
sudo apt install libudev-dev
sudo apt install libglfw3-dev
sudo apt install freeglut3-devAgora iremos instalar os pacotes
sudo apt install freenect
sudo apt install libfreenect-bin
sudo apt install libfreenect-demos
sudo apt install libfreenect-dev
sudo apt install libfreenect-doc
sudo apt install libfreenect0.5
Existe um conjunto de demos que foram criados para permitir usar o kinect. Vamos entender cada um.
freenect-cpp_pcview, oferece uma visualização básica da saída RGB e de profundidade usando C++.Demonstra o uso do kinect.

No nosso próximo artigo, irei demonstrar o uso do kinect, e fazer um exemplo de código em C.
Espero que tenham gostado.
Vamos fazer a seguinte conta usando uma calculadora cientifica
R^2 = 200^2 + 100^2 +2 * 200 * 100 * cos 30
Para fazer isso em um unico passo.
Na calculadora cientifica faça os seguintes passos, clicando os botões da calculadora
Faça 200 [x^2] [+] 100 [x^2] [+] 2 [*] 200 [*] 100 [*] [cos] 30 [=] [raiz] [ans]
achando angulo
tag ang = co/ca
tag ang = 291,42 / 118,38
na calculadora ang = 291,42 [/] 118,38 [=] [shift] [tan] [ans]
Para criar uma matriz de confusão no python, usaremos as bibliotecas do scikit-learn, para tanto, precisaremos instalar.
pip install scikit-learn
Segue abaixo o código, onde faremos a matriz de confusão.
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Valores reais (verdadeiros)
y_true = [2, 0, 2, 2, 0, 1]
# Valores previstos pelo modelo
y_pred = [0, 0, 2, 2, 0, 2]
# Gerar a matriz de confusão
conf_matrix = confusion_matrix(y_true, y_pred)
# Imprimir a matriz de confusão
print("Matriz de Confusão:")
print(conf_matrix)
# Para uma visualização melhor, você pode usar a biblioteca Seaborn para plotar a matriz de confusão
plt.figure(figsize=(10,7))
sns.heatmap(conf_matrix, annot=True, fmt="d")
plt.xlabel('Valores Previstos')
plt.ylabel('Valores Verdadeiros')
plt.title('Matriz de Confusão')
plt.show()
No código acima, podemos ver dois vetores, y_true, y_pred, onde os valores obtidos na leitura dos itens estão no vetor y_pred.
A matriz de referencia, é posta no y_true.
Por fim criamos a matriz de confusão:
conf_matrix = confusion_matrix(y_true, y_pred)
Criação da matriz de confusão


Execute o instalador, e aguarde o processo de instalação.
Após a instalação, rode o programa
cargo –version
teste do rust instalado
Após a sua instalação, o mesmo deve ser mostrado conforme apresentado.

Crie um hello world.rs
// This is a comment, and is ignored by the compiler.
// You can test this code by clicking the "Run" button over there ->
// or if you prefer to use your keyboard, you can use the "Ctrl + Enter"
// shortcut.
// This code is editable, feel free to hack it!
// You can always return to the original code by clicking the "Reset" button ->
// This is the main function.
fn main() {
// Statements here are executed when the compiled binary is called.
// Print text to the console.
println!("Hello World!");
}Pronto agora é só salvar na maquina.
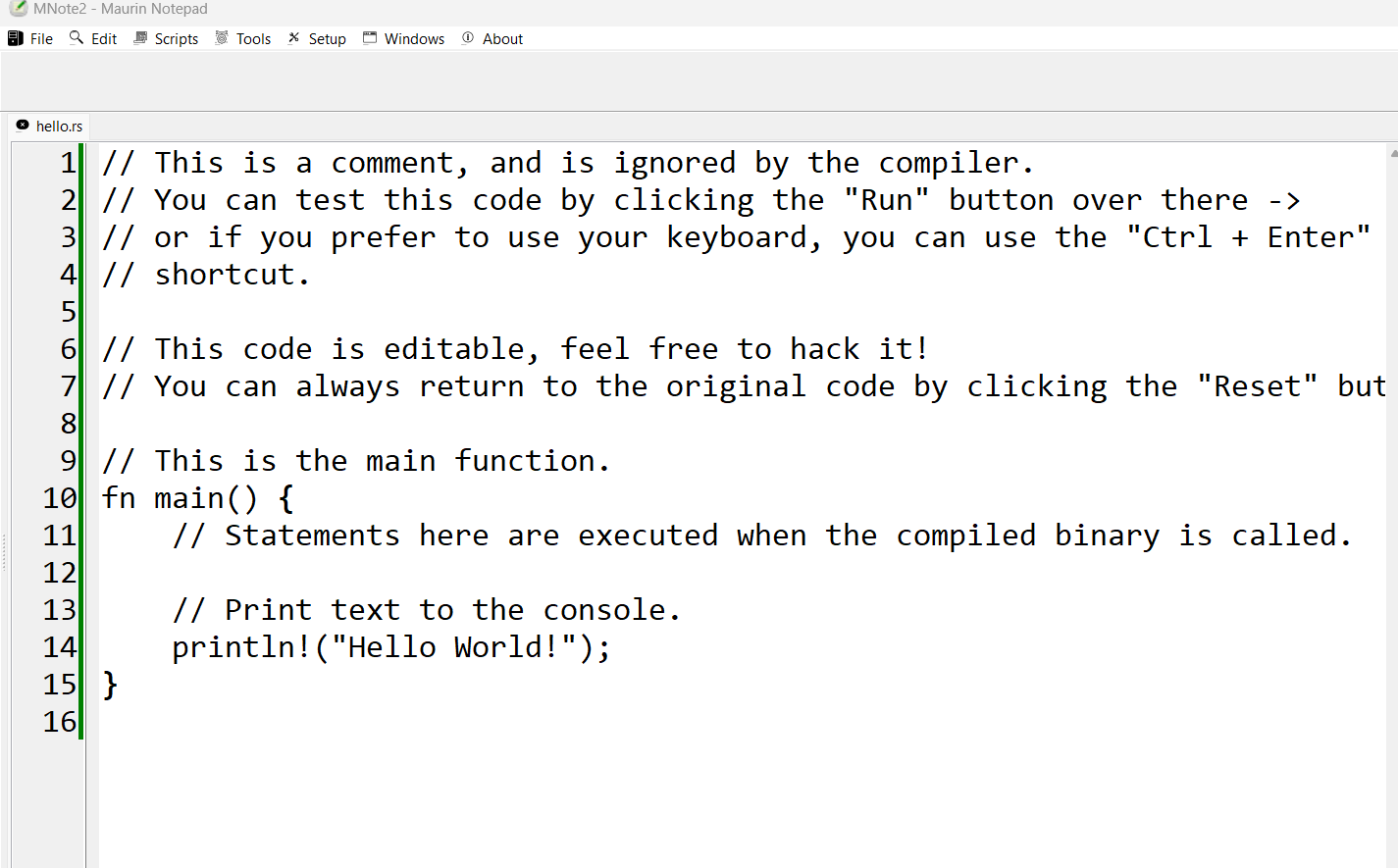
Agora iremos criar o projeto
cargo init hello
Cria o projeto do rust
Será criado uma pasta com o mesmo nome do projeto.
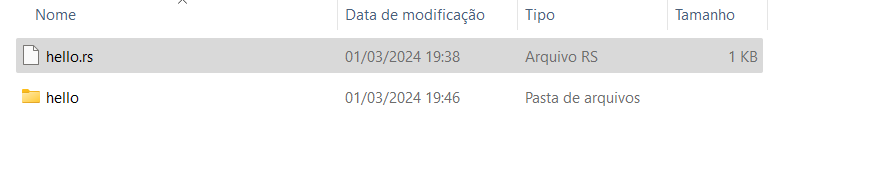
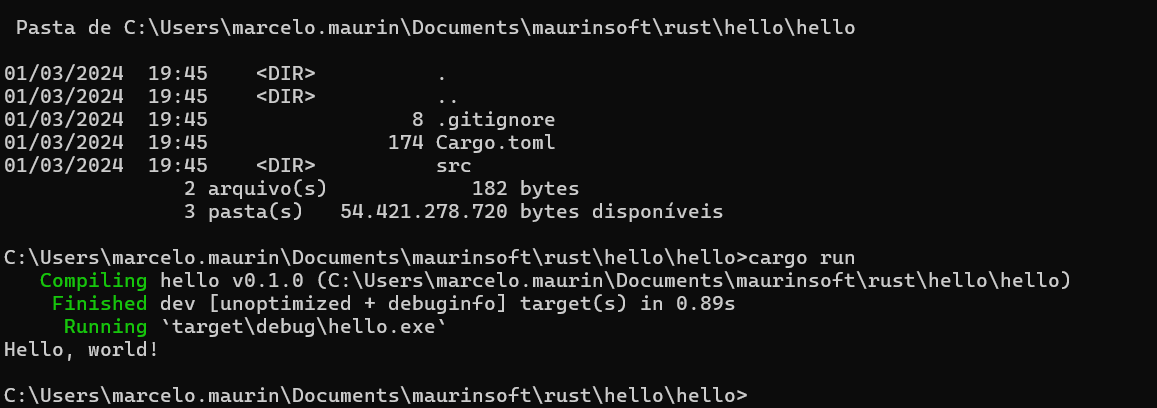
Entre na pasta do projeto, hello, e digite.
cargo run
Compila e roda a aplicação
Neste fluxo bem simplificado, apresentamos uma visão de criação de uma IA.
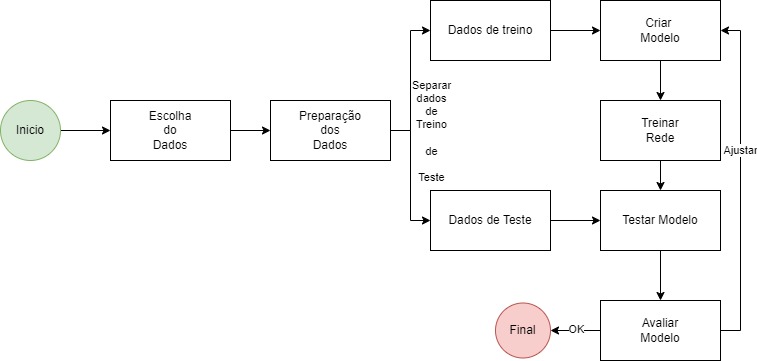
Na primeira etapa, escolhemos os dados e entendemos a qualidade e características desses dados.
Em projetos de IA, nem sempre temos prontos os dados, muitas vezes precisamos preparar e coletar tais dados.
Em um segundo faz a preparação dos dados, acertando problemas e ajustando os dados. Na vida real, é praticamente impossível pegar bases prontas de clientes. Muitas vezes as bases de clientes, exigem uma analise e pré processamento, para realizar ajustes ou cortes. Necessários para obter dados coerentes com que queremos analisar.
A próxima etapa é separar dados em treinamento e testes. Onde usa-se o bom senso para avaliar as escolhas dos dados. Sendo uma referencia 70 /30% , onde 70 % dos itens serão utilizados para treinamento e os demais, serão usados para teste. Levando sempre em consideração a diversidade dos dados tanto para testes, como para treinamentos. A escolha aleatória dos 30% garante uma melhor probabilidade de sucesso, pois evita selecionar modelos com caracteristicas próximas , que podem iludir ou derrubar as estatísticas dos resultados.
O treinamento consiste em pegar os dados e aplicar a um modelo de IA conhecido, podendo ser NLP , redes convulocionais, ou outros tipos como Grafos.
Nesta etapa cria-se as estruturas e linguagem necessária para gerar a rede treinada.
Nesta etapa usa-se os dados para gerar as informações separadas para validar a rede criada.
Analisando os resultados a partir de respostas conhecidas.
A partir da analise dos resultados, são de fato, avaliados duas decisões:
Finalização do projeto ou etapa
Retorno a etapa de codificação, ajustando técnicas ou processos para corrigir problemas identificados.

Gustav Robert Kirchhoff foi um físico alemão que fez contribuições significativas em vários campos da física e da química. Ele é mais conhecido por suas leis que descrevem o fluxo de corrente elétrica em circuitos elétricos, as Leis de Kirchhoff, que são fundamentais para a engenharia elétrica e a física.
Kirchhoff nasceu em 1824 e faleceu em 1887. Durante sua vida, ele trabalhou em problemas de termodinâmica, óptica e espectroscopia, além de eletricidade. Junto com Robert Bunsen, Kirchhoff desenvolveu a espectroscopia, que é um método para analisar a composição química de materiais baseado na luz que eles emitem ou absorvem. Através desse trabalho, eles foram capazes de descobrir novos elementos químicos, como o césio e o rubídio.
As duas leis de Kirchhoff para circuitos elétricos, formuladas em 1845, são:
Essas leis são aplicadas no design e análise de circuitos elétricos, permitindo calcular correntes e tensões em diversos pontos de um circuito. Além de suas contribuições para a física, as descobertas de Kirchhoff tiveram um impacto duradouro em várias áreas da ciência e tecnologia.
As Leis de Kirchhoff são dois princípios aplicados em circuitos elétricos que ajudam a entender a conservação da carga e da energia em tais sistemas. Elas são fundamentais para a análise de circuitos elétricos em engenharia e física. As leis foram formuladas por Gustav Kirchhoff em 1845 e são conhecidas como Lei dos Nós (Primeira Lei) e Lei das Malhas (Segunda Lei).
A Primeira Lei de Kirchhoff, ou Lei dos Nós, afirma que a soma algébrica das correntes em qualquer nó de um circuito é igual a zero. Isso significa que a quantidade total de corrente elétrica que flui para um nó é igual à quantidade total de corrente que sai dele. Matematicamente, isso pode ser expresso como:
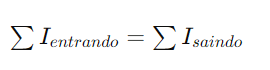
ou, de forma mais geral,
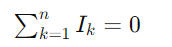
onde ��Ik representa a corrente da k-ésima conexão em um nó, com correntes entrando no nó tratadas como positivas e correntes saindo como negativas. Essa lei é uma consequência da conservação da carga elétrica.
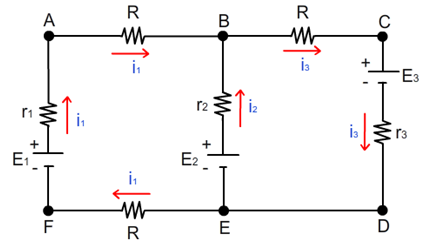
A Segunda Lei de Kirchhoff, ou Lei das Malhas, afirma que a soma algébrica das diferenças de potencial (tensões) em qualquer malha fechada do circuito é igual a zero. Isso significa que a soma das quedas de tensão (consumo de energia) é igual à soma das tensões fornecidas (fontes de energia) em uma malha. Em outras palavras, a energia total em um circuito fechado é conservada. Matematicamente, pode ser expressa como:
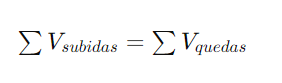
ou, de forma mais geral,
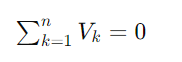
onde Vk representa a diferença de potencial (tensão) na k-ésima componente da malha, com tensões no sentido do percurso assumidas como positivas e tensões contra o percurso como negativas.
Essas duas leis juntas permitem a análise completa de circuitos elétricos complexos, possibilitando calcular correntes e tensões em diversas partes de um circuito.

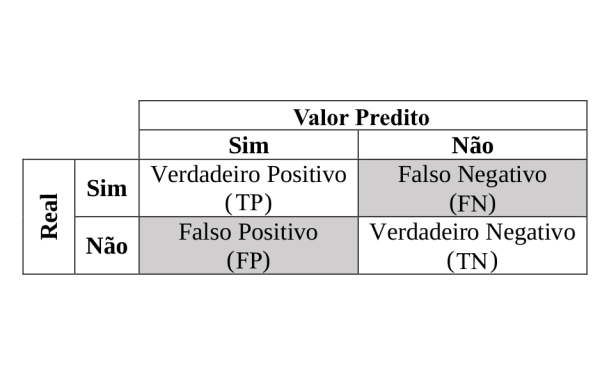
Diz os acertos:
Soma-se os Verdadeiros Positivos + Verdadeiros Negativos dividido pelo total de itens
onde:
a = acuracia
VP = Verdadeiro Positivo
VN = Verdadeiro Negativo
T = Total de itens
Calcula o percentual de erros na matriz de confusão
Onde:
e = Percentual de erro
FP = Falso Positivo
FN = Falso Negativo
T = Total
Onde é possível medir a sensibilidade ao acerto.
onde:
pv = Positivo Verdadeiro
VP = Verdadeiro Positivo
FN = Falso Negativo
Diz quanto da amostra os acertos realmente são eficientes
Onde:
p = Precisão
VP = Verdadeiro Positivo
FP = Falso Positivo
Diz dos Negativos, quantos foram corretamente classificados.
Onde:
nv = Especificidade
VN = Verdadeiro Negativo
FP = Falso Positivo
Onde de todos os Negativos, quantos foram classificados incorretamente
Onde:
pf = Positivo Falso
FP = Falso Positivo
VN = Verdadeiro Negativo
FP = Falso Positivo
De todos os Positivos, quantos foram classificados incorretamente como Negativo
Onde:
nf = Negativos Falsos
FN = Falso Negativos
VP = Verdadeiros Positivos
FN = Falso Negativos
Maximiza os acertos, com relação a precisão, onde valores mais próximos ao 1 são desejados.
Onde:
F1 = Score
p = Precisão ou Precision
r = Sensibilidade (Sensivity) ou Repescagem (RECALL)
A perda logarítmica, também conhecida como log loss ou cross-entropy loss, é uma medida de desempenho usada em problemas de classificação, especialmente em classificações binárias e multiclasse. Essa métrica quantifica quão distantes estão as probabilidades previstas de um modelo em relação aos valores verdadeiros ou reais (0 ou 1). A ideia é penalizar não apenas as classificações incorretas, mas também a confiança errada nas previsões.
Para uma previsão perfeita, a perda logarítmica é 0, e ela aumenta à medida que a previsão se afasta do valor real. Um aspecto importante da perda logarítmica é que ela penaliza severamente as previsões que estão confiantemente erradas. Por exemplo, uma previsão errada com alta certeza (por exemplo, prever a probabilidade de uma classe como 0.9 quando a classe verdadeira é a outra) resultará em uma penalidade maior do que uma previsão errada com baixa certeza.
A fórmula para a perda logarítmica em classificação binária é dada por:
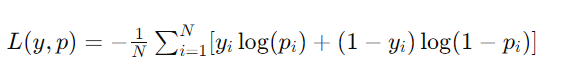
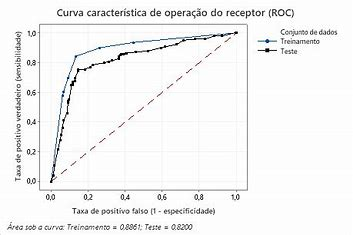
A Característica de Operação do Receptor (ROC, do inglês “Receiver Operating Characteristic”) é uma ferramenta utilizada para avaliar o desempenho de modelos de classificação binária. Ela é representada graficamente por uma curva que compara a taxa de verdadeiros positivos (sensibilidade) com a taxa de falsos positivos (1 – especificidade), para diferentes limiares de decisão.
A área sob a curva ROC (AUC, do inglês “Area Under the ROC Curve”) é um indicador da capacidade do modelo de discriminar entre as duas classes. Um valor de AUC igual a 1 indica um modelo perfeito, capaz de separar completamente as duas classes sem erros. Um valor de AUC igual a 0,5 sugere um desempenho não melhor do que o acaso, ou seja, o modelo não tem capacidade de discriminação entre as classes.
A curva ROC é particularmente útil porque permite a avaliação do desempenho do modelo em diferentes limiares, facilitando a escolha de um ponto de corte que equilibre entre a captura de verdadeiros positivos e a minimização de falsos positivos, de acordo com o contexto e os custos associados a cada tipo de erro.
AUC, que significa “Área Sob a Curva”, é um termo amplamente utilizado em análise de dados e machine learning, especialmente quando se refere à Curva ROC (Característica de Operação do Receptor). A AUC é uma métrica que quantifica o desempenho geral de um modelo de classificação, independentemente do limiar de decisão aplicado.
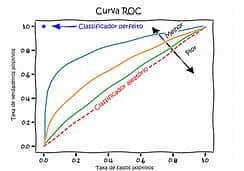
A AUC é uma métrica valiosa para avaliar e comparar modelos de classificação, oferecendo uma visão geral da capacidade do modelo de discriminar entre classes. Contudo, é importante considerá-la junto a outras métricas para obter uma avaliação completa do desempenho do modelo.

Uso da biblioteca spacy para pesquisa de caracteres usando matcher.
#!pip install spacy
import spacy
import spacy.util
from spacy.matcher import Matcher
# Verifica se o modelo 'pt_core_news_sm' está instalado
if not spacy.util.is_package("pt_core_news_sm"):
# Se não estiver instalado, baixa o modelo
!python -m spacy download pt_core_news_sm
else:
print("Modelo 'pt_core_news_sm' já está instalado.")
# Carrega o modelo de linguagem do spaCy
nlp = spacy.load("pt_core_news_sm")
# Cria o objeto Matcher e o vincula ao vocabulário do modelo de linguagem
matcher = Matcher(nlp.vocab)
def ContarOcorrenciasPalavra(palavra, lista_textos):
# Ajusta a palavra para lowercase
palavra = palavra.lower()
total_ocorrencias = 0
# Define o padrão para procurar a palavra, considerando a correspondência de texto exato em lowercase
pattern = [{"TEXT": palavra}]
matcher.add("PADRAO", [pattern])
# Converte o texto para lowercase e processa com o spaCy
doc = nlp(lista_textos.lower())
matches = matcher(doc)
# Para cada correspondência encontrada, imprime detalhes
for match_id, start, end in matches:
matched_span = lista_textos[start:end]
print(f"Achou no Texto: {lista_textos}; Palavra: '{matched_span}' na POS: {start} até {end}")
total_ocorrencias += 1
return total_ocorrencias
textos = ["Neste exemplo de caso de uso.", "São exemplos de figura de linguagem aplicadas ao exemplo.", "Este exemplo possui um erro semantico.", "Tal qual o exemplo a seguir."]
for texto in textos:
print("Texto:"+texto)
ContarOcorrenciasPalavra("exemplo",texto)
ContarOcorrenciasPalavra("uso",texto)
ContarOcorrenciasPalavra("figura",texto)
ContarOcorrenciasPalavra("aplicadas",texto)Saída do programa ao rodar
Texto:Neste exemplo de caso de uso.
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Texto:São exemplos de figura de linguagem aplicadas ao exemplo.
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Texto:Este exemplo possui um erro semantico.
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Texto:Tal qual o exemplo a seguir.
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4