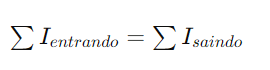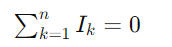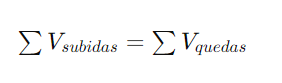Desenvolvimento com KINECT
No primeiro artigo, apresentei a instalação do kinect no ubuntu.
Agora iremos falar e mostrar um pouco sobre seu desenvolvimento.
GITHUB do Projeto
O projeto do libfreenect fica neste repositório.
https://github.com/OpenKinect/libfreenect.git
Site do Projeto
https://openkinect.org/wiki/Low_Level
Meu GITHUB
Ja os meus conjuntos de testes, inclusive os apresentados nos artigos relacionados, podem ser vistos, neste repositório.
https://github.com/marcelomaurin/kinect
Instalação de desenvolvimento
O processo de instalação completo foi visto no artigo anterior, porem para efeito de desenvolvimento os pacotes necessários são:
sudo apt install libudev-dev
sudo apt install libglfw3-dev
sudo apt install freeglut3-dev
sudo apt install libfreenect-devSendo os 3 pacotes iniciais, apenas apoio, e o libfreenect-dev realmente a lib necessária.
Hello World da Biblioteca
Neste primeiro projeto, pouca coisa faremos, apenas iremos compilar identificando o device.
#include <stdio.h>
#include <stdlib.h>
#include <libfreenect.h>
freenect_context *f_ctx;
freenect_device *f_dev;
int user_device_number = 0; // Normalmente 0 se você tiver apenas um Kinect
void depth_cb(freenect_device *dev, void *v_depth, uint32_t timestamp) {
// Callback para dados de profundidade - não usado neste exemplo
}
void rgb_cb(freenect_device *dev, void *rgb, uint32_t timestamp) {
// Salva uma imagem RGB capturada pelo Kinect
FILE *image = fopen("output_image.ppm", "wb");
if (image == NULL) {
printf("Erro ao abrir o arquivo para escrita\n");
return;
}
fprintf(image, "P6\n# Kinect RGB test\n640 480\n255\n");
fwrite(rgb, 640*480*3, 1, image);
fclose(image);
printf("Imagem salva como output_image.ppm\n");
// Depois de salvar a imagem, podemos sair do loop principal
freenect_stop_video(dev);
freenect_close_device(dev);
freenect_shutdown(f_ctx);
exit(0);
}
int main() {
if (freenect_init(&f_ctx, NULL) < 0) {
printf("freenect_init() falhou\n");
return 1;
}
if (freenect_open_device(f_ctx, &f_dev, user_device_number) < 0) {
printf("Não foi possível abrir o dispositivo\n");
freenect_shutdown(f_ctx);
return 1;
}
freenect_set_depth_callback(f_dev, depth_cb);
freenect_set_video_callback(f_dev, rgb_cb);
freenect_set_video_mode(f_dev, freenect_find_video_mode(FREENECT_RESOLUTION_MEDIUM, FREENECT_VIDEO_RGB));
freenect_start_video(f_dev);
while (freenect_process_events(f_ctx) >= 0) {
// Processa eventos do Kinect até que a captura de imagem seja concluída
}
return 0;
}Neste exemplo o programa pega o kinect e tira uma foto, salvando na maquina local.
Vamos entender o código.
A freenect_init inicia a api.
A próxima função freenect_open_device, abre o device conforme o número que estiver descrito. Isso permite abrir mais de um kinect na mesma maquina.
As funções freenect_set_depth_callback e freenect_set_video_callback criam funções de callback, para controle, se voce não sabe o que é leia este artigo:
A função freenect_set_video_mode indica os parâmetros de resolução.
Por ultimo a função freenect_start_video, dá inicio ao kinect que aciona o callback quando pronto.
Makefile
Criamos aqui o arquivo de compilação do projeto.
CC=gcc
CFLAGS=-c -Wall -I/usr/include/libfreenect
LDFLAGS=-L/usr/lib/x86_64-linux-gnu -lfreenect
SOURCES=kinect.c
OBJECTS=$(SOURCES:.c=.o)
EXECUTABLE=kinect
all: $(SOURCES) $(EXECUTABLE)
$(EXECUTABLE): $(OBJECTS)
$(CC) $(OBJECTS) -o $@ $(LDFLAGS)
.c.o:
$(CC) $(CFLAGS) $< -o $@
clean:
rm -f $(OBJECTS) $(EXECUTABLE)Perceba aqui que o pulo do gato neste makefile, é a inclusão da pasta /usr/lib/x86_64-linux-gnu que é onde a lib se encontra. Bem como a /usr/include/libfreenect que é onde o header se encontra.
Compilando o projeto
Para compilar esse projeto, é necessário apenas rodar o script na pasta src do ubuntu:
make all
Compilando o projeto

Rodando o programa
Agora iremos rodar o programa, isso é a parte mais simples.

Ao rodar, ele captura uma foto, e salva, conforme apresentado.

Foto capturada pelo kinect.