Este é um roteiro de instalação e preparação do seu UBUNTU para rodar o kinect.
O Kinect é parte integrante do XBOX 365, que apesar de já bem antigo (2024) ainda é uma tecnologia disruptiva, trazendo muitos benefícios para quem trabalha com IA e processamento de imagem.
O intuito deste tutorial é demonstrar o que é necessário para rodar o kinect no PC com linux.
Hardware
Logicamente, o kinect 365 é necessário.
Porem não somente ele, o hardware foi construído para o XBOX e possui um conector proprietário, que precisa alem de um adaptador, também de fonte externa para o PC.
Voce pode facilmente encontrar este adaptador se procurar “adaptador kinect xbox PC” em qualquer site de compras.
Software
Existe um pacote para linux que permite rodar o kinect, é o libfreenect.
Se olharmos na lista de repositórios do ubuntu por freenect, encontraremos os seguintes pacotes:
freenect – library for accessing Kinect device — metapackage
libfreenect-bin – library for accessing Kinect device — utilities and samples
libfreenect-demos -library for accessing Kinect device — dummy package
libfreenect-dev – library for accessing Kinect device — development files
libfreenect-doc – library for accessing Kinect device — documentation
libfreenect0.5 – library for accessing Kinect device
Para instalar esses pacotes siga o roteiro, instalando primeiro os pacotes requeridos.
Existe um conjunto de demos que foram criados para permitir usar o kinect. Vamos entender cada um.
freenect-camtest: Uma ferramenta de teste para verificar o funcionamento básico das câmeras RGB e de profundidade do Kinect.
freenect-chunkview: Utilitário para visualizar dados de “chunk” (pedaço), útil para debugar ou entender como os dados são transferidos do Kinect.
freenect-cpp_pcview: Um visualizador de nuvem de pontos escrito em C++, demonstrando como processar e visualizar dados de profundidade em 3D.
freenect-cppview: Similar ao freenect-cpp_pcview, oferece uma visualização básica da saída RGB e de profundidade usando C++.
freenect-glview: Provavelmente um dos exemplos mais usados, oferece uma visualização ao vivo simples das câmeras RGB e de profundidade usando OpenGL.
freenect-glpclview: Uma ferramenta avançada para visualizar a saída do Kinect como uma nuvem de pontos 3D, utilizando a biblioteca PCL (Point Cloud Library) e OpenGL para renderização.
freenect-hiview: Uma ferramenta de visualização que pode ser usada para exibir dados de alta resolução do Kinect.
Teste com freenect-glview
Demonstra o uso do kinect.
No nosso próximo artigo, irei demonstrar o uso do kinect, e fazer um exemplo de código em C.
No programa teste03.py, apresento como capturar a imagem e fiz alguns tratamentos de fundo, usando opencv.
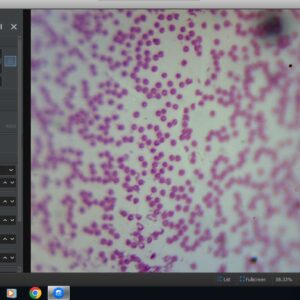
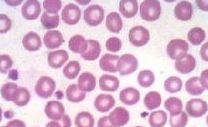
Neste artigo, irei preparar imagens para gerar o reconhecimento da hemácia.
Para tanto fiz a captura da hemácia, através da microscopia. Utilizando um microscópio com lente de ampliação de 20x, com uma câmera USB de 2Mb pixels.
Pegando a figura abaixo:
Irei tratar a imagem abaixo, para tentar reconhecer e contar as hemácias.
Para tanto o primeiro trabalho, é trabalhar com a imagem, fazendo duas etapas:
Retirar fundo da imagem da hemácia, e incluí-la em um banco de imagens de fundo.
Neste artigo, irei tratar cada uma destas atividades.
Retirar o Fundo da Imagem
Agora que tenho a imagem, usarei o site
https://www.remove.bg/
Para retirar o fundo da imagem. O procedimento é bem simples, faz-se o upload da imagem já recortada, para o site, e lá retira-se o fundo, com o auxilio de ferramentas do próprio site.
O site é bem intuitivo e pode ser usado livremente.
Ao final criamos a imagem sem o fundo, que iremos utilizar.
Criando imagem Positiva
A imagem positiva é a imagem que deve possuir a hemácia.
Neste primeiro momento eu preciso de uma base de imagens.
Para isso preciso baixar um grande volume de imagens para gerar tanto imagens positivas como negativas.
Eu peguei as imagem recortada, com os fundos apresentados no aplicativo, e fui recortando montando um banco de imagens coloridos.
Imagens de Teste
Para as imagens de teste, eu peguei imagens de internet e recortei.
Conforme apresentado a baixo:
Para ter sucesso, precisarei refazer esse teste, com pelo menos uma dúzia de hemácias, produzindo pelo menos 1000 imagens.
Este trabalho é longo e demorará vários dias.
Trabalhando com as imagens
No próximo artigo iremos processar a imagens de treino, criando uma base real de treinamento.
Agora irei faze-lo no Windows usando o Visual Studio.
Isso se dá porque geralmente eu prefiro o Linux ao Windows para desenvolvimento. A escolha é pessoal, e foi um hábito adquirido, no passar dos anos, pois o Linux, em minha opinião, oferece uma oportunidade maior de crescimento profissional. No que tange aprendizado de baixo nível.
Porem sem querer entrar nas questões de plataforma, há também necessidade, vez ou outra, usar o windows para desenvolvimento.
E para ser sincero, muitas vezes me sinto desconfortável, até pela falta de prática do uso desta plataforma.
Instalando o OPENCV no Windows
Porem para chegar nesse ponto, irei apresentar alguns artigos, que devem ser necessários para este fim.
O primeiro é a instalação do OpenCV e sua respectiva configuração no ambiente windows.
Primeiramente vamos baixar o opencv no site:
https://opencv.org/
Site do OpenCV
Baixe a ultima versão desta lib.
De forma geral ao tentar instalar, ele compacta na pasta: C:\Users\marce\Downloads
Eu costumo mover ele para o raiz do D:\ , no caso, caso não use um segundo disco, faça em seu c:\
Pronto a instalação do OpenCV foi realizada.
Preparando ambiente Visual Studio
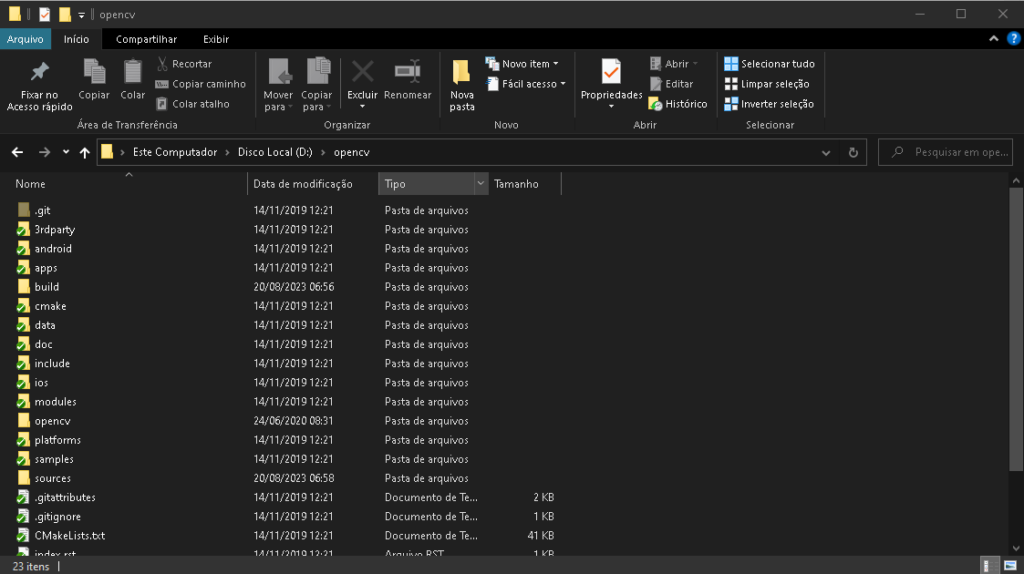
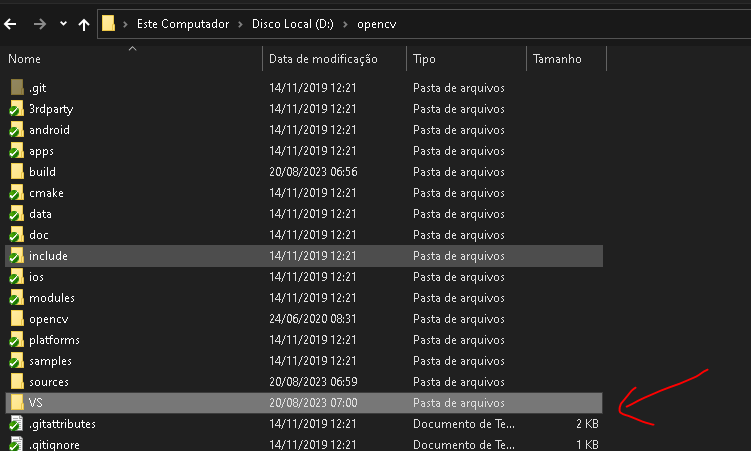
Agora vou criar uma pasta VS, dentro do meu D:\opencv\
O C precisa de duas coisas para funcionar, se tratando de bibliotecas, includes e libs.
Includes são os cabeçalhos das funções.
Libs são os binários (DLLs)
Copiando a pasta include, já marcada acima, dentro do VS.
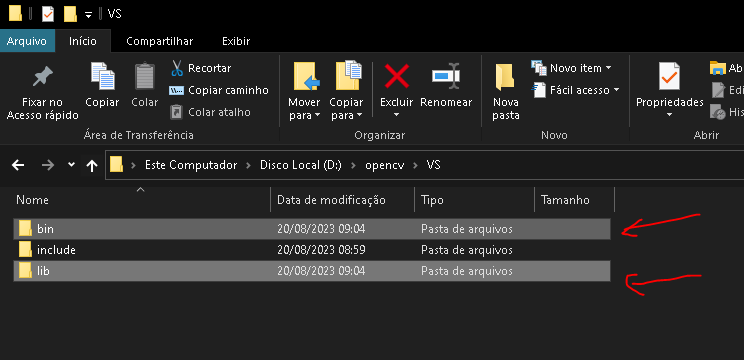
No caminho D:\opencv\build\x64\vc16 ou equivalente, pois o build contem os arquivos pré compilados, onde no meu caso irei utilizar a plataforma win 64 bits, por isso o X64. Copiarei as pastas bin e lib da pasta, para o VS, conforme mostrado a seguir:
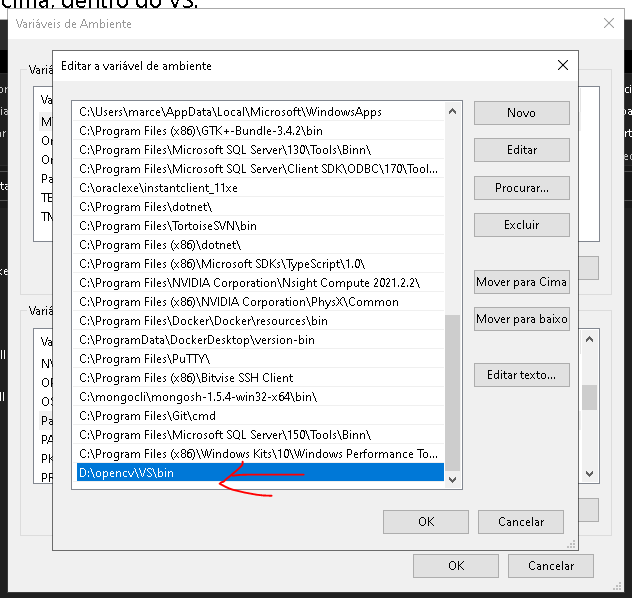
Agora precisamos incluir o caminho completo do bin, nas variáveis de ambiente:
Criando Hello World
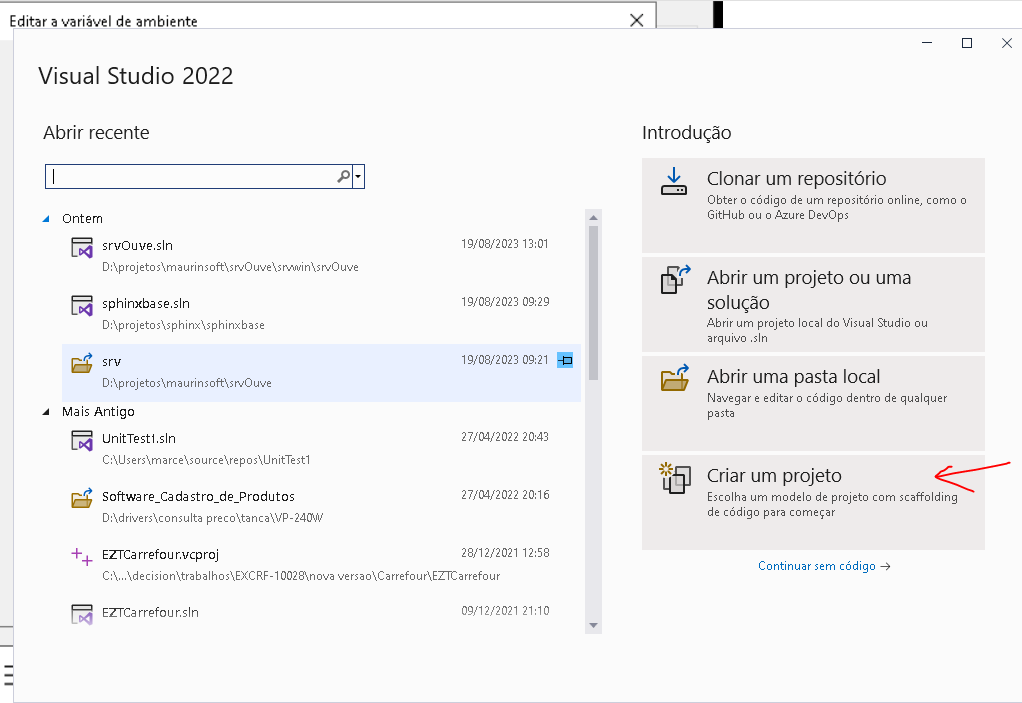
Agora vamos dar inicio a criação do projeto no visual studio.
Entre no Visual Studio e crie um projeto.
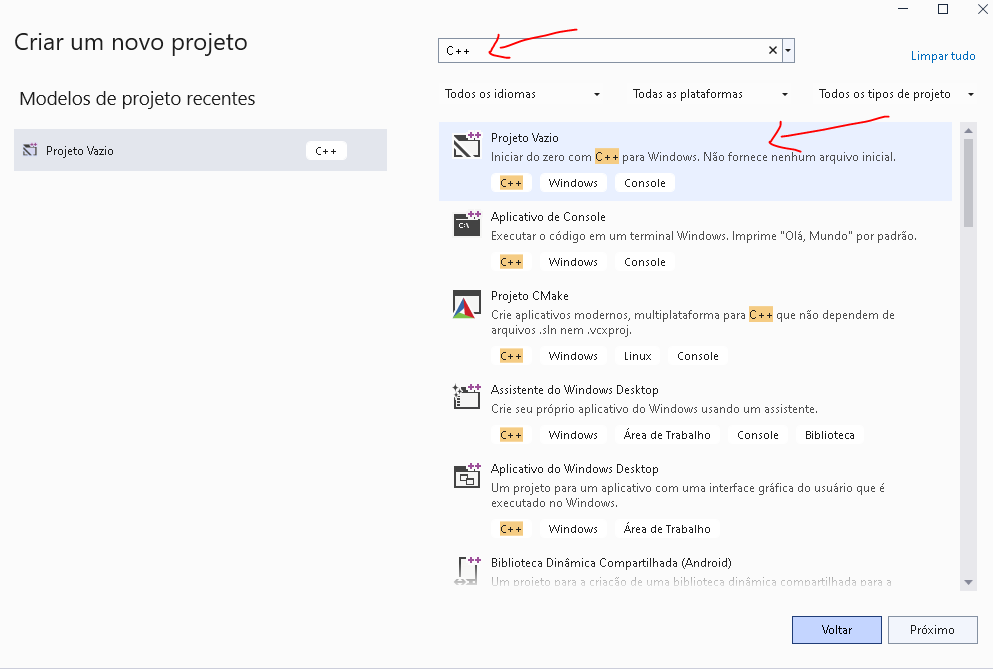
Agora, selecionamos o tipo de projeto:
Como o visual studio tem muitos templates, é mais fácil pesquisar c++ na aba de pesquisa, e selecionar Projeto Vazio, conforme figura acima.
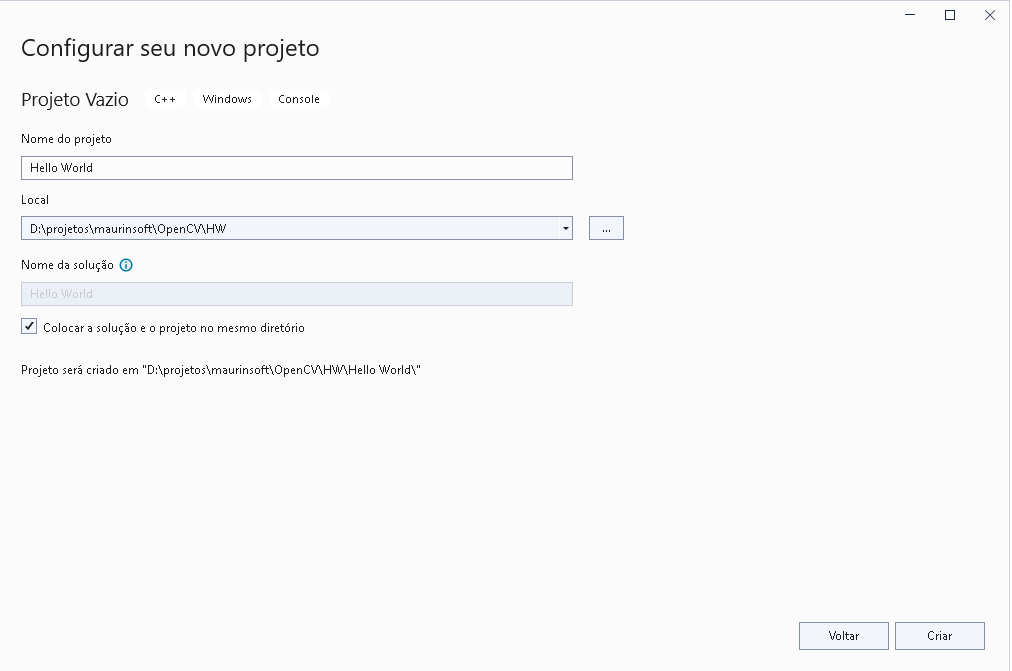
Digite o nome Hello World no Nome do projeto, conforme apresentado, e o local, indique a sua pasta de projeto. Por fim click no botão CRIAR.
Va na aba de gerenciador de Soluções, e click com botão direito no nome do projeto. Selecione NEW > Novo Item.
Mude para main.cpp e pressione adicionar.
Agora, iremos mudar o projeto, para incluir os locais que criamos no opencv.
Em PROJETO > Pagina de Propriedades, conforme figura abaixo:
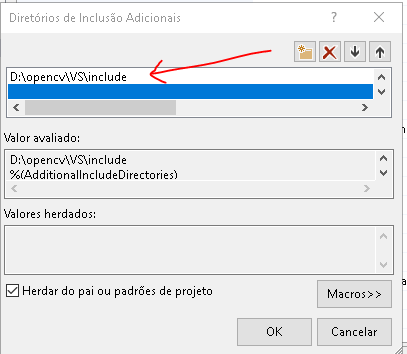
Abra a aba C/C++, localize Diretórios de Inclusão Adicionais, incluindo o seguinte item:
Inclua a pasta do include.
Agora vamos adicionar a lib.
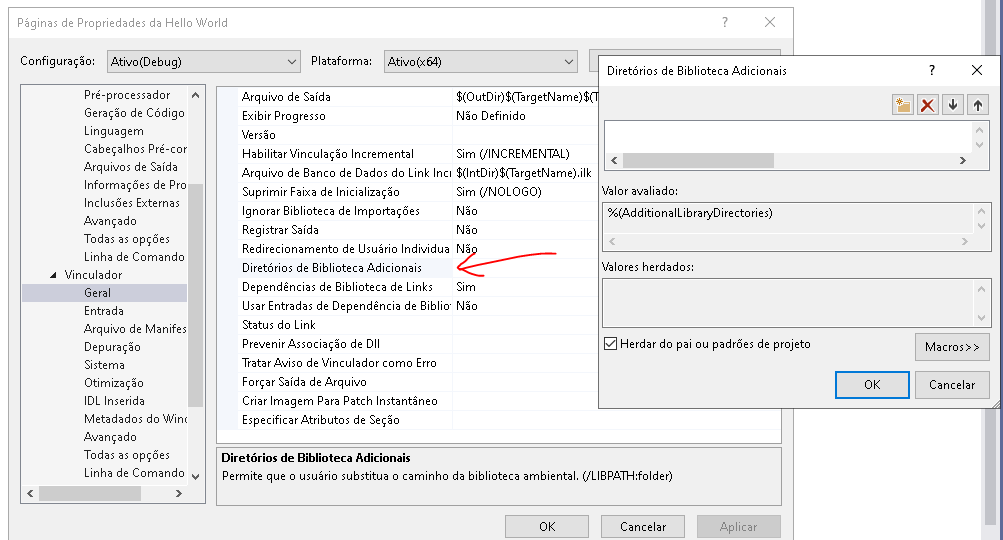
Em GERAL > Vinculador , Diretórios de Biblioteca Adicionais
Inclua o a pasta D:\opencv\VS\lib
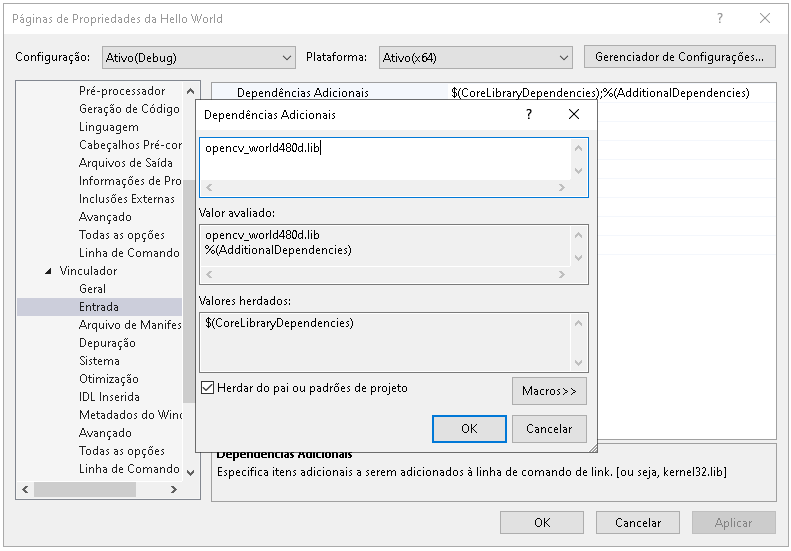
Agora iremos mostrar qual a lib que será adicionada.
A lib que iremos usar para debug, é opencv_world480d.lib.
Para isso vamos em Propriendades de Configuração > Vinculador > Entrada > Dependências Adicionais.
Pronto agora vamos ao código.
Inclusão do fonte:
Iremos usar o fonte que apontamos no artigo anterior, com uma pequena modificação.
#include <opencv2/opencv.hpp>
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
using namespace cv;
using namespace std;
int main(int, char**)
{
Mat frame;
//--- INITIALIZE VIDEOCAPTURE
VideoCapture cap;
// open the default camera using default API
//cap.open(0);
// OR advance usage: select any API backend
int deviceID = 0; // 0 = open default camera
int apiID = cv::CAP_ANY; // 0 = autodetect default API
// open selected camera using selected API
cap.open(deviceID, apiID);
// check if we succeeded
if (!cap.isOpened()) {
cerr << "ERROR! Unable to open camera\n";
return -1;
}
//--- GRAB AND WRITE LOOP
cout << "Start grabbing" << endl
<< "Press any key to terminate" << endl;
for (;;)
{
// wait for a new frame from camera and store it into 'frame'
cap.read(frame);
// check if we succeeded
if (frame.empty()) {
cerr << "ERROR! blank frame grabbed\n";
break;
}
// show live and wait for a key with timeout long enough to show images
imshow("Live", frame);
if (waitKey(5) >= 0)
break;
}
// the camera will be deinitialized automatically in VideoCapture destructor
return 0;
}
Salve o programa, e como de praxe para o windows, reinicie o visual studio, para validar as modificações do ambiente.
Agora é só rodar o OpenCV e pronto.
Por fim para aqueles que quiserem, segue o github:
Neste estudo darei um exemplo de aplicação prática usando o OPENCV.
Este artigo faz parte do trabalho de pós graduação apresentado na disciplina de OpenCV, da UNINOVE.
RA dos Alunos:
621200322 – Marcelo Maurin Martins
621201522 – Aland Montano
621202498 – Luciano Braga
621200985 – Jhone Fontenele
622137013- Douglas Campos
Equipamento:
Para realizar este estudo comprei o VEIN DISPLAY INSTRUMENT ZY-500.
Caracteristicas:
800-1000nm infrared
IR 1080P
Diametro 48mm
Equipamento ZY-500
Como ele Funciona
Ele é basicamente uma webcam USB 2.0, com resolução de 1080 pixel.
Este equipamento emite uma luz infra vermelha, que parcialmente penetra na pele (derme), e é refletida.
Porem em áreas onde existe muito sangue, a luz infra vermelha é absorvida.
Sabendo disso, fica facil identificar as veias proximas da pele.
Abaixo vemos um vídeo onde demonstro a visualização da camera sem nenhum tratamento.
Demonstração em Vídeo
Aqui apresentaremos detalhes do funcionamento da camera.
Neste exemplo mostro a imagem pura, sem processamento
Podemos ver em uma câmera normal, que as veias não se destacam.
Web cam normal
Porem podemos ver exatamente as veias na camera infravermelha.
Nesta imagem, sem filtros, podemos ver as veias claramente.
Imagem sem filtros
Inicio do processo de desenvolvimento
A imagem acima foi obtida, através do processamento do seguinte script PYTHON.
Iremos aplicar as técnicas aprendidas no curso, para avaliar a viabilidade destas na aplicação da solução. Lembrando que como qualquer processo cientifico, a experimentação empírica faz parte do processo.
E nem todas as técnicas serão utilizadas no projeto final.
Exemplo de código em Python
import cv2
device = 5
captura = cv2.VideoCapture(device)
while(1):
ret, frame = captura.read()
cv2.imshow("Camera Detector Veia", frame)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
captura.release()
cv2.destroyAllWindows()
A máquina em questão possui diversos devices (Cameras) acopladas, porem o número pode subir pois scripts em python tem o estranho habito de travar, e as vezes é necessário desligar o dispositivo, e religalo, o que causa um incremento no numero do device devido ao travamento do recurso.
Este travamento é temporario.
Vendo a banda RED
Separando a banda RED e verificando a melhora.
No fragmento de código abaixo, seleciono apenas a banda RED do RGB, onde analiso se há mudança significativa.
O nosso código, já possui a técnica contendo o resultado final empregado.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 15 16:00:05 2022
@author: mmm
"""
import cv2
#from PIL import Image
import numpy as np
import imutils
import pip
import importlib, os
from matplotlib import pyplot as plt
#import Image
from PIL import Image, ImageChops
global fundo
global frame
global gray1
global edged
global ret
device = 2
captura = cv2.VideoCapture(device)
while(1):
ret, frame = captura.read()
cv2.imshow("Camera Detector Veia", frame)
(B, G, R) = cv2.split(frame)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
num_lim = frame.shape[0]
num_col = frame.shape[1]
num_bandas = frame.shape[2]
gray2= np.zeros((num_lim , num_col), dtype="uint8")
gray2= B+G+R//3
#[num_lim, num_col, num_bandas] = frame.shape
dimensions = frame.shape
print('Image Dimension:',dimensions)
print('Image Height :',num_lim)
print('Image width:',num_col)
print('Image Channels:',num_bandas)
thresh = 135
fundo2 = cv2.threshold(gray,thresh,255,cv2.THRESH_BINARY)[1] #imagem limiralizada
#[thresh, fundo2] = cv2.threshold(gray, thresh, 255, cv2.THRESH_OTSU)
cv2.imshow("fundo2",fundo2)
img_filtro= np.zeros((num_lim , num_col, num_bandas), dtype="uint8")
for l in range(num_lim):
for c in range(num_col):
img_filtro[l,c] = ((fundo2[l,c]) & (frame[l,c] ^ fundo2[l,c]))
#img_filtro[l,c] = (frame[l,c] ^ fundo2[l,c])
#img_filtro = ImageChops.difference(fundo, frame)
cv2.imshow("filtrado", img_filtro)
while(1):
#gaus = cv2.GaussianBlur(img_filtro, (3, 3), 0)
#edged = cv2.Canny(img_filtro, 40, 103)
#janela = np.ones((3,3),np.float32)*-1
#palta = cv2.filter2D(img_filtro,-6,janela)
#gaus=cv2.GaussianBlur(img_filtro,(0,0),5)
#palta2=cv2.Scharr(img_filtro, ddepth=-1, dx=1, dy=0, scale=1, borderType=cv2.BORDER_DEFAULT)
#filtro = ImageChops.difference(fundo,gray)
#filtro = ImageChops.logical_xor(fundo,gray)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
RGB = cv2.cvtColor(img_filtro, cv2.COLOR_BGR2RGB)
grayold = gray
gray = cv2.cvtColor(RGB, cv2.COLOR_RGB2GRAY)
#gray = grayold
while(1):
cv2.imshow('gray',gray)
#http://www.lps.usp.br/hae/apostila/filtconv-ead.pdf
#Calculo de gradiente usando Scharr
schar=cv2.Scharr(gray, ddepth=-1, dx=0, dy=1, scale=1, borderType=cv2.BORDER_DEFAULT)
#cv2.imshow("gaus", gaus)
#cv2.imshow("Canny", edged)
cv2.imshow("Scharr", schar)
sobel=cv2.Sobel(schar,-2,1,1)
kernel = np.ones((5,5),np.uint8)
dilation = cv2.dilate(gray,kernel,iterations = 1)
maurin= np.zeros((num_lim , num_col), dtype="uint8")
for l in range(num_lim):
for c in range(num_col):
if(dilation[l,c]>=74 and dilation[l,c]<=76):
maurin[l,c] = 0
else:
maurin[l,c] = dilation[l,c]
thresh = 80
binimg=np.zeros((num_lim,num_col), dtype="uint8")
binimg=cv2.threshold(gray2, thresh, 255, cv2.THRESH_TOZERO)[1]
#cv2.imshow('gaus',gaus)
#cv2.imshow('edged',edged)
cv2.imshow('sobel',sobel)
cv2.imshow('dilation',dilation)
cv2.imshow('maurin:',maurin)
cv2.imshow('bin',binimg)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
captura.release()
cv2.destroyAllWindows()
Neste ultimo fragmento, iremos retirar o fundo do braço, e trabalhar com a imagem para dar destaque.
O resultado final é o que se apresenta.
Na imagem acima, podemos perceber que retiramos o braço dos demais objetos da imagem.
Tambem tratamos a imagem em tons de cinza, que permite posteriormente um trato mais simples da imagem.
Qual a vantagem da imagem acima da original. Primeiramente, a imagem original apesar de ser bem visivel a veia para nós, não conseguimos determinar um tom unico, para apresentar como veias. Na imagem processada, o tom da veia, esta mais distinto da imagem.
O que foi feito
Inicialmente capturamos a camera, através de um device.
Em seguida armazenamos a imagem na variavel frame.
Convertemos a imagem em cinza, através do comando:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
Agora, feita a primeira conversão, iremos pegar as caracteristicas da imagem, através da propriedade shape.
As propriedades de Altura (Height), Width( Largura) e channel (numero de bandas).
Agora iremos separar o braço do fundo, através da Limiarização:
O Filtro de dilatação, torna as marcas das veias mais marcantes.
Dilatation
Sua sintaxe é conforme apresentada.
Dando um incremento a visão da veia.
dilation = cv2.dilate(gray,kernel,iterations = 1)
Por fim apresentamos o vídeo final.
Vídeo detector de veias
Conclusão
Este estudo demonstra que através de técnicas de manipulação de imagem, sem o uso de redes neurais conseguimos trabalhar com imagens, realçando e separando partes que desejamos trabalhar.
Outra parte importante, é a associação de operações:
Onde associamos o fundo da imagem com a imagem, a fim da extração do fundo e aplicação do formato RGB, desassociado ao fundo.
Concomitante com o uso do Dilate (filtro de dilatação) associado ao Scharr, apresentou ótimos resultados, conforme apresentado a seguir.
Associação do Dilate associado ao Scharr, apresentou ótimo resultado.
Tendo como resultado final o código gerado:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 15 16:00:05 2022
@author: mmm
"""
import cv2
#from PIL import Image
import numpy as np
import imutils
import pip
import importlib, os
from matplotlib import pyplot as plt
#import Image
from PIL import Image, ImageChops
global fundo
global frame
global gray1
global edged
global ret
device = 2
captura = cv2.VideoCapture(device)
while(1):
ret, frame = captura.read()
cv2.imshow("Camera Detector Veia", frame)
(B, G, R) = cv2.split(frame)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
num_lim = frame.shape[0]
num_col = frame.shape[1]
num_bandas = frame.shape[2]
gray2= np.zeros((num_lim , num_col), dtype="uint8")
gray2= B+G+R//3
#[num_lim, num_col, num_bandas] = frame.shape
dimensions = frame.shape
print('Image Dimension:',dimensions)
print('Image Height :',num_lim)
print('Image width:',num_col)
print('Image Channels:',num_bandas)
thresh = 135
fundo2 = cv2.threshold(gray,thresh,255,cv2.THRESH_BINARY)[1] #imagem limiralizada
#[thresh, fundo2] = cv2.threshold(gray, thresh, 255, cv2.THRESH_OTSU)
cv2.imshow("fundo2",fundo2)
img_filtro= np.zeros((num_lim , num_col, num_bandas), dtype="uint8")
for l in range(num_lim):
for c in range(num_col):
img_filtro[l,c] = ((fundo2[l,c]) & (frame[l,c] ^ fundo2[l,c]))
#img_filtro[l,c] = (frame[l,c] ^ fundo2[l,c])
#img_filtro = ImageChops.difference(fundo, frame)
cv2.imshow("filtrado", img_filtro)
while(1):
#gaus = cv2.GaussianBlur(img_filtro, (3, 3), 0)
#edged = cv2.Canny(img_filtro, 40, 103)
#janela = np.ones((3,3),np.float32)*-1
#palta = cv2.filter2D(img_filtro,-6,janela)
#gaus=cv2.GaussianBlur(img_filtro,(0,0),5)
#palta2=cv2.Scharr(img_filtro, ddepth=-1, dx=1, dy=0, scale=1, borderType=cv2.BORDER_DEFAULT)
#filtro = ImageChops.difference(fundo,gray)
#filtro = ImageChops.logical_xor(fundo,gray)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
RGB = cv2.cvtColor(img_filtro, cv2.COLOR_BGR2RGB)
grayold = gray
gray = cv2.cvtColor(RGB, cv2.COLOR_RGB2GRAY)
#gray = grayold
while(1):
cv2.imshow('gray',gray)
#http://www.lps.usp.br/hae/apostila/filtconv-ead.pdf
#Calculo de gradiente usando Scharr
schar=cv2.Scharr(gray, ddepth=-1, dx=0, dy=1, scale=1, borderType=cv2.BORDER_DEFAULT)
#cv2.imshow("gaus", gaus)
#cv2.imshow("Canny", edged)
cv2.imshow("Scharr", schar)
sobel=cv2.Sobel(schar,-2,1,1)
kernel = np.ones((5,5),np.uint8)
#dilation = cv2.dilate(gray,kernel,iterations = 1)
dilation = cv2.dilate(schar,kernel,iterations = 1)
maurin= np.zeros((num_lim , num_col), dtype="uint8")
for l in range(num_lim):
for c in range(num_col):
if(dilation[l,c]>=74 and dilation[l,c]<=76):
maurin[l,c] = 0
else:
maurin[l,c] = dilation[l,c]
thresh = 80
binimg=np.zeros((num_lim,num_col), dtype="uint8")
binimg=cv2.threshold(gray2, thresh, 255, cv2.THRESH_TOZERO)[1]
#cv2.imshow('gaus',gaus)
#cv2.imshow('edged',edged)
cv2.imshow('sobel',sobel)
cv2.imshow('dilation',dilation)
cv2.imshow('maurin:',maurin)
cv2.imshow('bin',binimg)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
captura.release()
cv2.destroyAllWindows()
Neste trabalho, podemos verificar que ainda é longo e árduo o trabalho que separa o pré processamento da imagem, bem como não se trata de um trabalho acabado. Há muitas técnicas aqui não empregadas, que poderiam ser ajustadas.
Porem a analise que foi feita em várias das técnicas apresentadas durante o curso, tiveram resultados significativos na identificação e destaque das veias.
Agradecimento especial ao Professor Sidnei Alves de Araujo, da UNINOVE, que incentivou e permitiu a execução de trabalho especial.
Neste artigo irei apresentar um exemplo de código de opencv em C++.
Irei comentar traçando referencias entre o código do C e o código do python.
O Exemplo utililizado será fornecido pela própria biblioteca em python.
Aqui vemos o exemplo comentado do fonte
OpenCV em Python
Para traçar um paralelo usaremos os códigos do opencv, o programa chamado video_v4l2.py
Conforme apresentado abaixo:
#!/usr/bin/env python
'''
VideoCapture sample showcasing some features of the Video4Linux2 backend
Sample shows how VideoCapture class can be used to control parameters
of a webcam such as focus or framerate.
Also the sample provides an example how to access raw images delivered
by the hardware to get a grayscale image in a very efficient fashion.
Keys:
ESC - exit
g - toggle optimized grayscale conversion
'''
# Python 2/3 compatibility
from __future__ import print_function
import numpy as np
import cv2 as cv
def main():
def decode_fourcc(v):
v = int(v)
return "".join([chr((v >> 8 * i) & 0xFF) for i in range(4)])
font = cv.FONT_HERSHEY_SIMPLEX
color = (0, 255, 0)
cap = cv.VideoCapture(0)
cap.set(cv.CAP_PROP_AUTOFOCUS, 0) # Known bug: https://github.com/opencv/opencv/pull/5474
cv.namedWindow("Video")
convert_rgb = True
fps = int(cap.get(cv.CAP_PROP_FPS))
focus = int(min(cap.get(cv.CAP_PROP_FOCUS) * 100, 2**31-1)) # ceil focus to C_LONG as Python3 int can go to +inf
cv.createTrackbar("FPS", "Video", fps, 30, lambda v: cap.set(cv.CAP_PROP_FPS, v))
cv.createTrackbar("Focus", "Video", focus, 100, lambda v: cap.set(cv.CAP_PROP_FOCUS, v / 100))
while True:
_status, img = cap.read()
fourcc = decode_fourcc(cap.get(cv.CAP_PROP_FOURCC))
fps = cap.get(cv.CAP_PROP_FPS)
if not bool(cap.get(cv.CAP_PROP_CONVERT_RGB)):
if fourcc == "MJPG":
img = cv.imdecode(img, cv.IMREAD_GRAYSCALE)
elif fourcc == "YUYV":
img = cv.cvtColor(img, cv.COLOR_YUV2GRAY_YUYV)
else:
print("unsupported format")
break
cv.putText(img, "Mode: {}".format(fourcc), (15, 40), font, 1.0, color)
cv.putText(img, "FPS: {}".format(fps), (15, 80), font, 1.0, color)
cv.imshow("Video", img)
k = cv.waitKey(1)
if k == 27:
break
elif k == ord('g'):
convert_rgb = not convert_rgb
cap.set(cv.CAP_PROP_CONVERT_RGB, 1 if convert_rgb else 0)
print('Done')
if __name__ == '__main__':
print(__doc__)
main()
cv.destroyAllWindows()
A primeira informação importante é a carga das bibliotecas do opencv em python.
import cv2 as cvimport cv2 as cv
carga da lib em python
O proximo ponto importante é onde capturamos o vídeo.
cap = cv.VideoCapture(0)
Captura do vídeo
O Parametro 0, indica que o device de vídeo é o padrão do sistema.
O ponto importante no código é o uso do cap, no código abaixo:
_status, img = cap.read()
captura do frame
Ao chamar a função read, dois parametros são retornados, _status (retorno de sucesso) e img, a imagem capturada.
Por fim, uma janela é montada com a visualização da imagem capturada:
cv.imshow(“Video”, img)
janela é montada
Agora iremos analisar o mesmo código em C.
OpenCV em C
Agora mostraremos o código em C, o exemplo é o videocapture_basic.cpp:
#include <opencv2/core.hpp>
#include <opencv2/videoio.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
#include <stdio.h>
using namespace cv;
using namespace std;
int main(int, char**)
{
Mat frame;
//--- INITIALIZE VIDEOCAPTURE
VideoCapture cap;
// open the default camera using default API
// cap.open(0);
// OR advance usage: select any API backend
int deviceID = 0; // 0 = open default camera
int apiID = cv::CAP_ANY; // 0 = autodetect default API
// open selected camera using selected API
cap.open(deviceID, apiID);
// check if we succeeded
if (!cap.isOpened()) {
cerr << "ERROR! Unable to open camera\n";
return -1;
}
//--- GRAB AND WRITE LOOP
cout << "Start grabbing" << endl
<< "Press any key to terminate" << endl;
for (;;)
{
// wait for a new frame from camera and store it into 'frame'
cap.read(frame);
// check if we succeeded
if (frame.empty()) {
cerr << "ERROR! blank frame grabbed\n";
break;
}
// show live and wait for a key with timeout long enough to show images
imshow("Live", frame);
if (waitKey(5) >= 0)
break;
}
// the camera will be deinitialized automatically in VideoCapture destructor
return 0;
}
O primeiro ponto assim como no código em python, e a chamada da biblioteca em c.
Sem esses includes não teriamos acessos aos tipos do C, como o que segue:
VideoCapture cap;
O tipo VideoCapture é o tipo associado a captura de vídeo da câmera.
Onde usaremos, conforme fragmento abaixo:
int deviceID = 0; // 0 = open default camera
int apiID = cv::CAP_ANY; // 0 = autodetect default API
// open selected camera using selected API
cap.open(deviceID, apiID);
Aqui, definimos o deviceID como 0, ou seja, o valor padrão, veja a semelhança do uso do python.
E apiID, passando o escopo (variavel) CAP_ANY, que tem por valor 0.
Chamamos o método open da classe VideoCapture, indicando o deviceID, e o apiID.
Agora iremos ler a imagem da camera, que podemos fazer, através da seguinte função:
cap.read(frame);
Neste fragmento de código, passamos o parametro frame, que é do tipo Mat.
O frame receberá a imagem capturada.
E por fim, no código abaixo a janela que irá mostrar a imagem na interface gráfica.
imshow("Live", frame);
Conclusão
Apesar das diferenças de linguagem, podemos ver o pontos em comum, e a sutileza da semelhança.
É lógico que os códigos foram escolhidos a dedo. Justamente por conta da semelhança e simplicidade.
O opencv é uma biblioteca rica, cheia de opções e dificuldades, este tutorial, bem como o autor, esta apenas adentrando neste mundo para mim misterioso.
# Encontre o numero de núcleos do seu computador
nproc
# Substitua o 4 pelo resultado obtido em nproc
make -j4
sudo make install
sudo sh -c 'echo "/usr/local/lib" >> /etc/ld.so.conf.d/opencv.conf'
sudo ldconfig
Passo 6: Teste o OpenCV3
Vamos testar um aplicativo de remoção de olhos vermelhos escrito em OpenCV para testar nossas instalações em C ++ e Python.
Os binários compilados irão estar disponíveis após a compilação.
Passo 6.2: Teste o código em Python
Abra o vim, e edite o seguinte código:
vim ipython
# open ipython (execute esta linha no console) ipython # import cv2 and print version (run following commands in ipython) importcv2 print cv2.__version__ # Se o OpenCV3 estiver instalado corretamente, # na linha de comando aparecerá a saída 3.3.1 # Pressione CTRL+D para sair do ipython
Para executar o removedor de olhos vermelhos
python removeRedEyes.py
Sempre que você estiver executando scripts Python que usam o OpenCV, você deve ativar o ambiente virtual que criamos, usando o comando workon.
Registre-se e baixe o código
Tradução
Este artigo é uma adaptação a partir do artigo original, contendo várias modificações, em caso de problemas, envie-nos um email