A programação orientada a objetos (POO) é um paradigma de programação que organiza o código em “objetos” – estruturas que combinam dados (atributos) e comportamentos (métodos). Python, por ser uma linguagem multiparadigma, possui um suporte robusto à POO, permitindo que desenvolvedores criem aplicações mais organizadas, reutilizáveis e de fácil manutenção. Neste artigo, abordaremos os principais princípios da orientação a objetos: encapsulamento, herança, polimorfismo e abstração, apresentando exemplos didáticos para cada um.
1. Conceitos Básicos de Orientação a Objetos
Antes de explorarmos os princípios, vamos relembrar dois conceitos fundamentais:
Classe: É um “molde” ou “projeto” que define os atributos (dados) e os métodos (funções) que seus objetos terão.
Objeto: É uma instância de uma classe. Cada objeto possui seu próprio estado, representado pelos valores dos atributos.
Exemplo simples de classe e objeto em Python:
class Pessoa:
def __init__(self, nome, idade):
self.nome = nome
self.idade = idade
def apresentar(self):
print(f"Olá, meu nome é {self.nome} e tenho {self.idade} anos.")
# Criação de objetos
p1 = Pessoa("Alice", 30)
p2 = Pessoa("Bruno", 25)
p1.apresentar() # Saída: Olá, meu nome é Alice e tenho 30 anos.
p2.apresentar() # Saída: Olá, meu nome é Bruno e tenho 25 anos.
2. Princípios da Orientação a Objetos
2.1 Encapsulamento
Encapsulamento é o mecanismo que agrupa dados e métodos que operam sobre esses dados dentro de uma mesma unidade (classe), restringindo o acesso direto a alguns componentes. Isso ajuda a proteger o estado interno do objeto e permite modificar a implementação interna sem afetar a interface pública.
Exemplo de encapsulamento com atributos privados:
class ContaBancaria:
def __init__(self, saldo_inicial):
self.__saldo = saldo_inicial # Atributo privado
def depositar(self, valor):
if valor > 0:
self.__saldo += valor
print(f"Depósito de R${valor} realizado com sucesso.")
def sacar(self, valor):
if 0 < valor <= self.__saldo:
self.__saldo -= valor
print(f"Saque de R${valor} realizado com sucesso.")
else:
print("Saldo insuficiente ou valor inválido.")
def mostrar_saldo(self):
print(f"Saldo atual: R${self.__saldo}")
# Uso da classe
conta = ContaBancaria(1000)
conta.depositar(500)
conta.sacar(300)
conta.mostrar_saldo()
# A tentativa de acesso direto ao atributo privado resultará em erro:
# print(conta.__saldo) -> AttributeError
No exemplo acima, o atributo __saldo é privado e não pode ser acessado diretamente fora da classe. Os métodos depositar, sacar e mostrar_saldo formam a interface pública para interagir com esse dado.
2.2 Herança
Herança permite que uma classe herde atributos e métodos de outra, promovendo a reutilização de código e a criação de hierarquias. A classe que herda é chamada de subclasse ou classe derivada, enquanto a classe de onde se herda é chamada de superclasse ou classe base.
Exemplo de herança:
class Veiculo:
def __init__(self, marca, modelo):
self.marca = marca
self.modelo = modelo
def exibir_info(self):
print(f"Marca: {self.marca}, Modelo: {self.modelo}")
# Classe derivada que herda de Veiculo
class Carro(Veiculo):
def __init__(self, marca, modelo, portas):
super().__init__(marca, modelo) # Chama o construtor da superclasse
self.portas = portas
def exibir_info(self):
super().exibir_info()
print(f"Portas: {self.portas}")
# Uso das classes
veiculo = Veiculo("Genérico", "Modelo X")
veiculo.exibir_info()
print("----")
carro = Carro("Toyota", "Corolla", 4)
carro.exibir_info()
Aqui, a classe Carro herda de Veiculo e adiciona o atributo portas, além de sobrescrever o método exibir_info para incluir informações específicas do carro.
2.3 Polimorfismo
Polimorfismo é a capacidade de diferentes classes responderem de forma específica à mesma mensagem (método). Ou seja, métodos com o mesmo nome podem ter implementações diferentes em classes distintas.
Exemplo de polimorfismo:
class Animal:
def emitir_som(self):
pass # Método abstrato, sem implementação
class Cachorro(Animal):
def emitir_som(self):
print("Au Au")
class Gato(Animal):
def emitir_som(self):
print("Miau")
# Função que recebe um objeto do tipo Animal e chama emitir_som
def fazer_animal_emitir_som(animal):
animal.emitir_som()
# Uso do polimorfismo
cachorro = Cachorro()
gato = Gato()
fazer_animal_emitir_som(cachorro) # Saída: Au Au
fazer_animal_emitir_som(gato) # Saída: Miau
Apesar dos objetos Cachorro e Gato serem instâncias de classes diferentes, ambos implementam o método emitir_som. Assim, a função fazer_animal_emitir_som pode receber qualquer objeto derivado de Animal e executar o método correspondente.
2.4 Abstração
Abstração consiste em ocultar os detalhes de implementação e mostrar apenas a funcionalidade essencial ao usuário. Em Python, podemos utilizar classes abstratas para definir métodos que devem ser implementados por suas subclasses. A biblioteca abc (Abstract Base Classes) facilita a criação de classes abstratas.
Exemplo de abstração usando o módulo abc:
from abc import ABC, abstractmethod
class FormaGeometrica(ABC):
@abstractmethod
def calcular_area(self):
pass
class Quadrado(FormaGeometrica):
def __init__(self, lado):
self.lado = lado
def calcular_area(self):
return self.lado ** 2
class Circulo(FormaGeometrica):
def __init__(self, raio):
self.raio = raio
def calcular_area(self):
import math
return math.pi * (self.raio ** 2)
# Tentativa de instanciar a classe abstrata gera erro:
# forma = FormaGeometrica() -> TypeError
# Uso das classes concretas
quadrado = Quadrado(4)
circulo = Circulo(3)
print(f"Área do quadrado: {quadrado.calcular_area()}") # Saída: 16
print(f"Área do círculo: {circulo.calcular_area():.2f}") # Saída: valor aproximado
No exemplo, FormaGeometrica é uma classe abstrata que define o método calcular_area como abstrato. As classes Quadrado e Circulo implementam esse método de acordo com suas fórmulas específicas.
Conclusão
A orientação a objetos em Python oferece uma maneira estruturada e intuitiva de organizar o código. Ao utilizar os princípios de encapsulamento, herança, polimorfismo e abstração, os desenvolvedores podem criar sistemas mais robustos, modulares e fáceis de manter. Esperamos que os exemplos apresentados neste artigo ajudem a compreender melhor esses conceitos e inspirem a aplicação deles em seus projetos!
Sendo os 3 pacotes iniciais, apenas apoio, e o libfreenect-dev realmente a lib necessária.
Hello World da Biblioteca
Neste primeiro projeto, pouca coisa faremos, apenas iremos compilar identificando o device.
#include <stdio.h>
#include <stdlib.h>
#include <libfreenect.h>
freenect_context *f_ctx;
freenect_device *f_dev;
int user_device_number = 0; // Normalmente 0 se você tiver apenas um Kinect
void depth_cb(freenect_device *dev, void *v_depth, uint32_t timestamp) {
// Callback para dados de profundidade - não usado neste exemplo
}
void rgb_cb(freenect_device *dev, void *rgb, uint32_t timestamp) {
// Salva uma imagem RGB capturada pelo Kinect
FILE *image = fopen("output_image.ppm", "wb");
if (image == NULL) {
printf("Erro ao abrir o arquivo para escrita\n");
return;
}
fprintf(image, "P6\n# Kinect RGB test\n640 480\n255\n");
fwrite(rgb, 640*480*3, 1, image);
fclose(image);
printf("Imagem salva como output_image.ppm\n");
// Depois de salvar a imagem, podemos sair do loop principal
freenect_stop_video(dev);
freenect_close_device(dev);
freenect_shutdown(f_ctx);
exit(0);
}
int main() {
if (freenect_init(&f_ctx, NULL) < 0) {
printf("freenect_init() falhou\n");
return 1;
}
if (freenect_open_device(f_ctx, &f_dev, user_device_number) < 0) {
printf("Não foi possível abrir o dispositivo\n");
freenect_shutdown(f_ctx);
return 1;
}
freenect_set_depth_callback(f_dev, depth_cb);
freenect_set_video_callback(f_dev, rgb_cb);
freenect_set_video_mode(f_dev, freenect_find_video_mode(FREENECT_RESOLUTION_MEDIUM, FREENECT_VIDEO_RGB));
freenect_start_video(f_dev);
while (freenect_process_events(f_ctx) >= 0) {
// Processa eventos do Kinect até que a captura de imagem seja concluída
}
return 0;
}
Neste exemplo o programa pega o kinect e tira uma foto, salvando na maquina local.
Vamos entender o código.
A freenect_init inicia a api.
A próxima função freenect_open_device, abre o device conforme o número que estiver descrito. Isso permite abrir mais de um kinect na mesma maquina.
As funções freenect_set_depth_callback e freenect_set_video_callback criam funções de callback, para controle, se voce não sabe o que é leia este artigo:
Perceba aqui que o pulo do gato neste makefile, é a inclusão da pasta /usr/lib/x86_64-linux-gnu que é onde a lib se encontra. Bem como a /usr/include/libfreenect que é onde o header se encontra.
Compilando o projeto
Para compilar esse projeto, é necessário apenas rodar o script na pasta src do ubuntu:
make all
Compilando o projeto
Rodando o programa
Agora iremos rodar o programa, isso é a parte mais simples.
Ao rodar, ele captura uma foto, e salva, conforme apresentado.
Uso da biblioteca spacy para pesquisa de caracteres usando matcher.
#!pip install spacy
import spacy
import spacy.util
from spacy.matcher import Matcher
# Verifica se o modelo 'pt_core_news_sm' está instalado
if not spacy.util.is_package("pt_core_news_sm"):
# Se não estiver instalado, baixa o modelo
!python -m spacy download pt_core_news_sm
else:
print("Modelo 'pt_core_news_sm' já está instalado.")
# Carrega o modelo de linguagem do spaCy
nlp = spacy.load("pt_core_news_sm")
# Cria o objeto Matcher e o vincula ao vocabulário do modelo de linguagem
matcher = Matcher(nlp.vocab)
def ContarOcorrenciasPalavra(palavra, lista_textos):
# Ajusta a palavra para lowercase
palavra = palavra.lower()
total_ocorrencias = 0
# Define o padrão para procurar a palavra, considerando a correspondência de texto exato em lowercase
pattern = [{"TEXT": palavra}]
matcher.add("PADRAO", [pattern])
# Converte o texto para lowercase e processa com o spaCy
doc = nlp(lista_textos.lower())
matches = matcher(doc)
# Para cada correspondência encontrada, imprime detalhes
for match_id, start, end in matches:
matched_span = lista_textos[start:end]
print(f"Achou no Texto: {lista_textos}; Palavra: '{matched_span}' na POS: {start} até {end}")
total_ocorrencias += 1
return total_ocorrencias
textos = ["Neste exemplo de caso de uso.", "São exemplos de figura de linguagem aplicadas ao exemplo.", "Este exemplo possui um erro semantico.", "Tal qual o exemplo a seguir."]
for texto in textos:
print("Texto:"+texto)
ContarOcorrenciasPalavra("exemplo",texto)
ContarOcorrenciasPalavra("uso",texto)
ContarOcorrenciasPalavra("figura",texto)
ContarOcorrenciasPalavra("aplicadas",texto)
Saída do programa ao rodar
Texto:Neste exemplo de caso de uso.
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Texto:São exemplos de figura de linguagem aplicadas ao exemplo.
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Texto:Este exemplo possui um erro semantico.
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Texto:Tal qual o exemplo a seguir.
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
No dia de hoje 15/10/2023 , foram criadas novas amostras (30 ) de treinamento de 3 hemácias diferentes.
Totalizando agora 60 amostras de treino.
Adicionei um projeto em python para gerar as imagens cinza a partir das imagens coloridas.
Para isso basta rodar o código em hemacias\python\tools\converte\converte.py
Conforme o código abaixo em python.
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import os
from PIL import Image
def converter_imagens_cinza(diretorio_entrada, diretorio_saida):
# Verifica se o diretório de saída existe. Se não, cria-o.
if not os.path.exists(diretorio_saida):
os.makedirs(diretorio_saida)
# Percorre os arquivos no diretório de entrada
for filename in os.listdir(diretorio_entrada):
print(f"filename:{filename}")
# Verifica se o arquivo é uma imagem .jpg
if filename.lower().endswith(".jpg"):
# Cria os caminhos completos de entrada e saída para o arquivo
caminho_entrada = os.path.join(diretorio_entrada, filename)
caminho_saida = os.path.join(diretorio_saida, filename)
# Abre a imagem
with Image.open(caminho_entrada) as img:
# Converte a imagem para cinza
img_cinza = img.convert("L")
# Salva a imagem convertida no diretório de saída
img_cinza.save(caminho_saida)
print(f"Imagem {filename} convertida para cinza e salva em {caminho_saida}.")
# Converte imagens em positivas coloridas testes:
diretorio_entrada = "D:/projetos/maurinsoft/hemacias/fotos/positivas coloridas testes"
diretorio_saida = "D:/projetos/maurinsoft/hemacias/fotos/positivas cinza testes"
converter_imagens_cinza(diretorio_entrada, diretorio_saida)
# Converte imagens em positivas coloridas treino:
diretorio_entrada = "D:/projetos/maurinsoft/hemacias/fotos/positivas coloridas treino"
diretorio_saida = "D:/projetos/maurinsoft/hemacias/fotos/positivas cinza treino"
converter_imagens_cinza(diretorio_entrada, diretorio_saida)
print('Finalizou\n')
O programa gera as saídas responsáveis pelas imagens de treino.
O Python é uma das linguagens mais simples e intuitivas já criadas, por este motivo, amplamente utilizada por muitos desenvolvedores de diversas áreas. No entanto, à medida que os projetos crescem e se tornam mais complexos, manter o código organizado e de fácil manutenção pode ser um desafio.
Muitas vezes criamos projetos simples, que ganham complexidade e volume a medida que novos recursos ou funcionalidades são agregados.
Em um dado momento temos que repensar o projeto, reorganizando-o de forma a torna-lo mais legível.
Por Que Seguir Boas Práticas?
A manutenção de projetos é um estado de arte a parte do desenvolvimento. Criar projetos de sucesso, é apenas 50% do trabalho, pois um programa precisa ser gerido e mantido por anos. Então garantir que tais mudanças sejam implementadas, faz parte do trabalho de qualquer bom programador.
A colaboração – A muitos anos atras os programadores sonhavam ser Michelangelo, onde fariam e escreveriam obras de arte icônicas, que somente eles os manteriam. Isso mudou. A produção de software se industrializou, tornando um negócio de muitos, e a colaboração na codificação faz parte da vida de qualquer programador, nos dias atuais.
Melhora na organização de códigos, não só ajuda a entender o projeto de forma global, como tambem a não criar redundancias lógicas. Colocando em risco o projeto.
Como fazer isso
Estarei apresentando aqui, uma breve descrição de como separar os códigos em Python.
Módulos
Módulos são um conjunto de arquivos, contidos em uma pasta, que possuem uma hierarquia vinculada a este módulo. São muito úteis, pois conseguimos agrupar tais fontes a um conjunto comum.
Para criar um módulo, simplesmente criamos uma pasta, e adicionamos dentro deste o arquivo. __init__.py.
Adicionaremos outros arquivos .py conforme nossa necessidade.
Para carregar um codigo de um dado modulo, faremos no programa principal a seguinte chamada:
from meumodulo import meufonte
De forma geral o módulo deverá estar em uma subpasta do seu fonte principal.
Existem variações para criação de módulos, porem a forma mais simples de sua criação , foi descrita aqui.
Programação é feita com tijolos de conhecimento, um único tijolo não te torna um programador, assim como um tijolo não vira uma casa. Porem cada tijolo de conhecimento é importante para compor um grande programador.
Este segundo artigo é mais prático, então vamos a mão na massa!
Criando conexão:
import mysql.connector
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words('portuguese'))
# Configuração da conexão com o banco
DB_CONFIG = {
"host": "localhost",
"user": "username",
"password": "password",
"database": "graph_db"
}
"""Cria arestas com base em frases de exemplo."""
frases = [
"Comece a gravação de áudio",
"Salve esse texto importante",
"Defina um alerta para amanhã",
"Quero a gravação dessa reunião",
"Salve a anotação rapidamente"
]
comandos = [
"Iniciar gravação",
"Salvar texto",
"Configurar alerta",
"Iniciar gravação",
"Salvar anotação"
]
#Treinamento e teste
matriz = [
["Comece a gravar agora", "Iniciar gravação"],
["Inicie a gravação do áudio", "Iniciar gravação"],
["Por favor, ative a gravação", "Iniciar gravação"],
["Vamos começar a gravação", "Iniciar gravação"],
["Quero que comece a gravar", "Iniciar gravação"],
["Dê início à gravação", "Iniciar gravação"],
["Preciso gravar isso", "Iniciar gravação"],
["Vamos gravar essa conversa", "Iniciar gravação"],
["Inicie a captação do áudio", "Iniciar gravação"],
["Gostaria de gravar este momento", "Iniciar gravação"],
["Por gentileza, inicie a gravação", "Iniciar gravação"],
["Capture esse áudio", "Iniciar gravação"],
["Quero guardar esse som", "Iniciar gravação"],
["Vamos documentar esse áudio", "Iniciar gravação"],
["Grave essa sessão", "Iniciar gravação"],
["Desejo registrar esse som", "Iniciar gravação"],
["Vamos dar start na gravação", "Iniciar gravação"],
["Por favor, comece a gravar", "Iniciar gravação"],
["Gostaria de iniciar a gravação", "Iniciar gravação"],
["Desejo capturar este áudio", "Iniciar gravação"],
["Preserve este texto", "Salvar texto"],
["Quero guardar essa informação", "Salvar texto"],
["Salve estas palavras", "Salvar texto"],
["Documente este conteúdo", "Salvar texto"],
["Registre esta informação", "Salvar texto"],
["Gostaria de salvar este documento", "Salvar texto"],
["Por favor, salve esse texto", "Salvar texto"],
["Desejo guardar este conteúdo", "Salvar texto"],
["Capture esta informação em texto", "Salvar texto"],
["Guarde essa anotação", "Salvar texto"],
["Defina um alarme para 9h", "Configurar alerta"],
["Quero ser alertado às 10h", "Configurar alerta"],
["Lembre-me de algo às 11h", "Configurar alerta"],
["Ative um lembrete para o meio-dia", "Configurar alerta"],
["Preciso de um alerta para as 13h", "Configurar alerta"],
["Por favor, configure um alerta para 14h", "Configurar alerta"],
["Quero ser notificado às 15h", "Configurar alerta"],
["Defina um lembrete para 16h", "Configurar alerta"],
["Lembre-me disso às 17h", "Configurar alerta"],
["Configure um alerta para 18h", "Configurar alerta"],
["Faça uma nota disto", "Salvar anotação"],
["Quero que isso fique registrado", "Salvar anotação"],
["Documente esta observação", "Salvar anotação"],
["Anote isto, por favor", "Salvar anotação"],
["Preserve esta anotação", "Salvar anotação"],
["Por favor, faça uma nota sobre isso", "Salvar anotação"],
["Desejo que isso seja anotado", "Salvar anotação"],
["Guarde este registro", "Salvar anotação"],
["Capture esta nota", "Salvar anotação"],
["Quero esta informação documentada", "Salvar anotação"],
]
Agora criamos a função de conexão com banco de dados:
def connect_to_database():
"""Retorna uma conexão com o banco de dados."""
return mysql.connector.connect(**DB_CONFIG)
Eu pedi ao chatGPT criar a matriz estática contendo variações de solicitações de comando.
Desta forma poderia apresentar o texto e testar os resultados.
Lembrando que como uso grafos duplamente ligados, a qualidade dos resultados depende muito do treinamento.
matriz_teste = [
["Dê início à captura de som", "Iniciar gravação"],
["Gostaria de ouvir isso depois", "Iniciar gravação"],
["Por gentileza, registre este momento", "Iniciar gravação"],
["Ative o modo gravação", "Iniciar gravação"],
["Preserve este áudio para mim", "Iniciar gravação"],
["Assegure que este texto esteja seguro", "Salvar texto"],
["Faça uma cópia deste conteúdo", "Salvar texto"],
["Deixe este texto registrado", "Salvar texto"],
["Fixe esta informação", "Salvar texto"],
["Quero ter este texto para depois", "Salvar texto"],
["Estabeleça um aviso para 19h", "Configurar alerta"],
["Preciso ser lembrado às 20h", "Configurar alerta"],
["Por favor, defina um bip para 21h", "Configurar alerta"],
["Quero um aviso sonoro para as 22h", "Configurar alerta"],
["Faça um lembrete vibrar às 23h", "Configurar alerta"],
["Gostaria de ter isso em minhas notas", "Salvar anotação"],
["Anote isto para mim", "Salvar anotação"],
["Mantenha esta informação como uma nota", "Salvar anotação"],
["Quero isto em formato de anotação", "Salvar anotação"],
["Por favor, transforme isso em uma nota", "Salvar anotação"]
]
No artigo anterior, criamos apenas algumas frases para popular nossa base.
Iremos modificar um pouco nosso programa
Nas palavras vamos incluir a opção de cadastro, porem se já existir ja passamos o ID:
# Função para cadastrar palavras
def CadastraWords(word_name):
connection = connect_to_database()
cursor = connection.cursor()
# Verifica se a palavra já está cadastrada
cursor.execute("SELECT word_id FROM words WHERE word_name = %s", (word_name,))
result = cursor.fetchone()
if result:
return result[0]
cursor.execute("INSERT INTO words (word_name) VALUES (%s)", (word_name,))
connection.commit()
word_id = cursor.lastrowid
cursor.close()
connection.close()
return word_id
Já na opção de arestas, iremos usar o CadastraWords, conforme apresentado a seguir:
def CriaArestas(Word1, Word2, Cmd):
print(Word1)
print(Word2)
"""Cria uma aresta associando Word1 e Word2 ao comando Cmd."""
#word1_id = get_id_words(Word1, "word_name")
#word2_id = get_id_words(Word2, "word_name")
word1_id = CadastraWords(Word1)
word2_id = CadastraWords(Word2)
cmd_id = get_id_commands(Cmd, "command_name")
print(word1_id);
print(word2_id);
print(cmd_id);
if not word1_id or not word2_id or not cmd_id:
print("Erro: Um ou mais valores não foram encontrados no banco de dados.")
return
connection = connect_to_database()
cursor = connection.cursor()
insert_query = """
INSERT INTO edges (word_id1, word_id2, command_id)
VALUES (%s, %s, %s)
"""
try:
cursor.execute(insert_query, (word1_id, word2_id, cmd_id))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir aresta: {err}")
cursor.close()
connection.close()
Por fim iremos incluir nos grafos os itens do treinamento:
Função para popular com dados de teste
Nela criamos e povoamos os 200 testes.
# Função para popular com dados de teste
def Popula_Teste():
stop_words = set(stopwords.words('portuguese'))
for item in matriz_teste:
frase, comando = item
words = word_tokenize(frase, language="portuguese")
filtered_words = [w for w in words if w.lower() not in stop_words and w.isalpha()]
for i in range(len(filtered_words) - 1):
CriaArestas(filtered_words[i], filtered_words[i + 1], comando)
Agora iremos chamar a função e testar:
Popula_Teste()
Primeiros Testes
Agora iremos utilizar nossa matriz de teste (matriz_teste) para aferir quais os resultados que ele acha. Lembrando que para realizar tal façanha usamos novos códigos.
Nesta primeira função testamos o resultado, individualmente.
def Teste_Validacao(Frase, comando):
stop_words = set(stopwords.words('portuguese'))
connection = connect_to_database()
cursor = connection.cursor()
# Tokenize e limpe a frase
words = word_tokenize(Frase, language="portuguese")
filtered_words = [w.lower() for w in words if w.lower() not in stop_words and w.isalpha()]
# Obtenha o ID do comando
cursor.execute("SELECT command_id FROM commands WHERE command_name = %s", (comando,))
command_id = cursor.fetchone()
if not command_id:
return "Comando não encontrado."
command_id = command_id[0]
# Verifique a presença de pares de palavras na tabela edges
total_matches = 0
for i in range(len(filtered_words) - 1):
cursor.execute("""SELECT COUNT(*) FROM edges
WHERE word_id1 = (SELECT word_id FROM words WHERE word_name = %s)
AND word_id2 = (SELECT word_id FROM words WHERE word_name = %s)
AND command_id = %s""", (filtered_words[i], filtered_words[i + 1], command_id))
total_matches += cursor.fetchone()[0]
# Matriz de confusão: [Predicted True, Predicted False; Actual True, Actual False]
confusion_matrix = [[0, 0], [0, 0]]
if total_matches > 0: # Se houver combinações, assuma que a previsão é verdadeira
confusion_matrix[0][0] = 1
else: # Se não houver combinações, assuma que a previsão é falsa
confusion_matrix[1][1] = 1
cursor.close()
connection.close()
return confusion_matrix
Neste segundo, usamos a matriz para criar uma matriz de confusão:
def plot_confusion_matrix(confusion_matrix, classes, title='Matriz de Confusão', cmap=plt.cm.Blues):
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix, annot=True, cmap=cmap, fmt='g', xticklabels=classes, yticklabels=classes)
plt.ylabel('Comando verdadeiro')
plt.xlabel('Comando previsto')
plt.title(title)
plt.show()
def Testa_Validacao():
conn = connect_to_database()
cursor = conn.cursor()
# Lista de stopwords em português
stop_words = set(stopwords.words('portuguese'))
confusion_matrix = np.zeros((len(comandos), len(comandos)))
for item in matriz_teste:
frase, comando_verdadeiro = item
# Processa a frase: remove stopwords, converte para minúsculo
palavras = [word for word in frase.lower().split() if word not in stop_words and not word.isdigit()]
# Encontre os IDs das palavras
word_ids = []
for palavra in palavras:
cursor.execute("SELECT word_id FROM words WHERE word_name = %s", (palavra,))
result = cursor.fetchone()
if result:
word_ids.append(result[0])
# Encontre a aresta com maior frequência baseada nas palavras
comando_previsto = None
max_count = -1
for i in range(len(word_ids)-1):
cursor.execute("""
SELECT command_id, COUNT(*) as freq
FROM edges
WHERE word_id1 = %s AND word_id2 = %s
GROUP BY command_id
ORDER BY freq DESC
LIMIT 1
""", (word_ids[i], word_ids[i+1]))
result = cursor.fetchone()
if result and result[1] > max_count:
comando_previsto = result[0]
max_count = result[1]
if comando_previsto:
# Converte o ID do comando para nome
cursor.execute("SELECT command_name FROM commands WHERE command_id = %s", (comando_previsto,))
result = cursor.fetchone()
if result:
comando_previsto_name = result[0]
confusion_matrix[comandos.index(comando_verdadeiro)][comandos.index(comando_previsto_name)] += 1
conn.close()
# Plota a matriz de confusão
plt.figure(figsize=(10,7))
sns.heatmap(confusion_matrix, annot=True, cmap="YlGnBu", xticklabels=comandos, yticklabels=comandos)
plt.xlabel('Comando Previsto')
plt.ylabel('Comando Verdadeiro')
plt.show()
Por fim, chamamos os dados de Testa_Validacao.
Testa_Validacao()
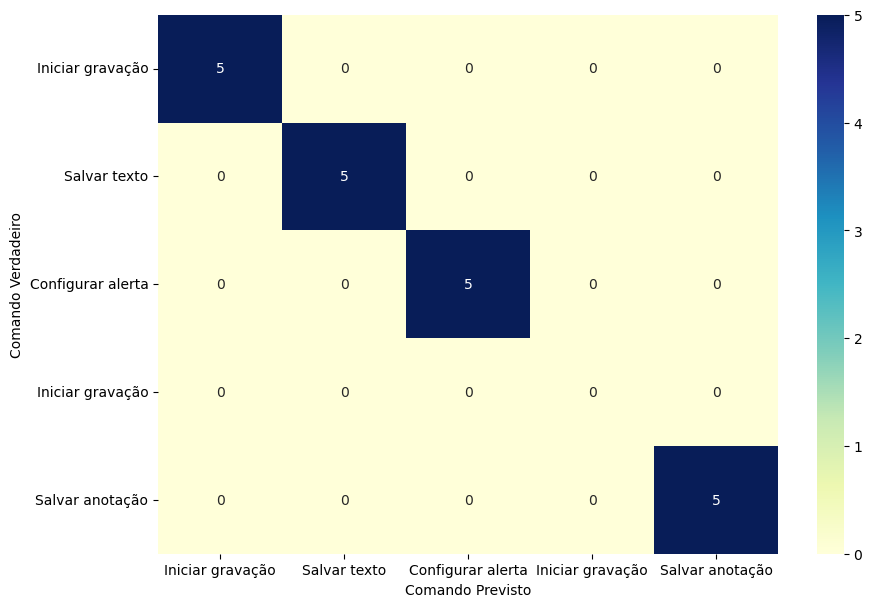
Gerando uma matriz conforme apresentado:
Perceba que a linha diagonal, é o que realmente desejamos. Perceba que houve intencionalmente uma duplicação do iniciar gravação, e que a segunda vez que ele apareceu, os dados não foram mostrados.
A apresentação deste problema pode ocorrer, em especial quando existir muitos grafos e muitos comandos, e seu tratamento será necessário pelo algoritmo que o propuser.
Por fim, para os amantes do fonte de graça, segue a referencia do GITHUB:
Parte do material deste tutorial veio do CHATGPT4.
Origem
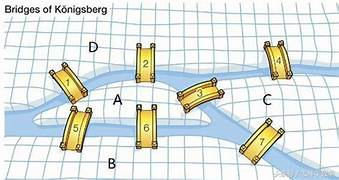
Problema das Pontes de Königsberg (1736): Leonhard Euler demonstrou ser impossível caminhar pela cidade de Königsberg, passando por cada uma das sete pontes exatamente uma vez e retornando ao ponto de partida. Este problema é a origem da teoria dos grafos.
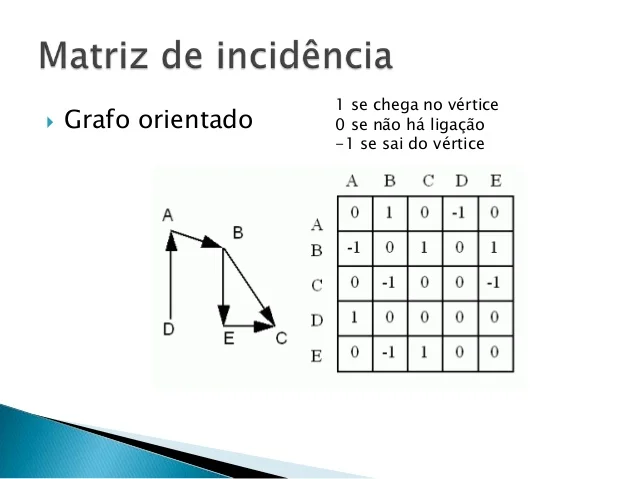
Gustav Kirchhoff: Introduziu a matriz de incidência e estudou árvores abrangentes.
James Joseph Sylvester: Investigou grafos planares.
Teoremas e Problemas Notáveis
Teorema das quatro cores: Qualquer mapa em um plano pode ser colorido com no máximo quatro cores distintas, de modo que regiões adjacentes não tenham a mesma cor. Provado em 1976.
Problema do caixeiro-viajante: Busca o caminho mais curto que visita cada cidade exatamente uma vez, retornando à origem.
Algoritmos de Dijkstra e Floyd-Warshall: Encontram caminhos mais curtos em grafos.
Aplicações Modernas
Século XXI: Uso extensivo da teoria dos grafos em redes sociais, internet das coisas e sistemas complexos.
Essa síntese destaca os marcos e conceitos mais relevantes na evolução da teoria dos grafos.
Elementos dos Grafos
Os grafos são relações entre partes, e podemos entender seus elementos como se segue:
Elementos Básicos de Grafos
Vértices (ou Nós): São as entidades do grafo. Em contextos práticos, podem representar cidades, computadores em uma rede, pessoas em uma rede social, entre outros.
Arestas (ou Ligações): São as conexões entre os vértices. Em um mapa, por exemplo, uma aresta pode representar uma estrada conectando duas cidades.
Grafos Dirigidos vs. Não Dirigidos: Em um grafo dirigido (ou digrafo), as arestas têm uma direção, indo de um vértice para outro. Em grafos não dirigidos, as arestas não têm direção.
Peso: As arestas podem ter um peso associado, que pode representar distâncias, custos, etc.
Implementações
A implementação de um grafo pode ser feita de várias formas, pois é um conceito.
Porem as formas mais comuns são descritos a seguir:
Lista de Adjacência
É uma lista onde, para cada vértice do grafo, armazenamos uma lista de seus vértices adjacentes. É uma forma eficiente de armazenar grafos esparso.
Exemplo em python:
Matriz de Adjacência
A matriz de adjacência é uma das formas mais comuns de representar um grafo em termos de estrutura de dados. Ela utiliza uma matriz bidimensional (um array de arrays) para expressar as relações entre os vértices de um grafo.
Características Básicas
Tamanho da Matriz: Se um grafo tem V vértices, sua matriz de adjacência será de tamanho V×V.
Grafos Não Dirigidos:
Se o vértice i estiver conectado ao vértice j, então matriz[i][j] = 1 (ou o peso da aresta, em grafos ponderados).
Como o grafo é não dirigido, matriz[j][i] também será 1.
Em outras palavras, a matriz é simétrica em relação à sua diagonal principal.
Grafos Dirigidos (Digrafos):
Se existir uma aresta dirigida do vértice i para o vértice j, então matriz[i][j] = 1 (ou o peso da aresta).
Neste caso, a matriz não é necessariamente simétrica.
Grafos Ponderados:
Em vez de conter apenas valores binários (0 ou 1), a matriz contém os pesos das arestas. Se não houver conexão entre dois vértices, um valor padrão (geralmente 0 ou infinito) é usado.
Diagonal Principal: Em muitos grafos, a diagonal principal (matriz[i][i] para todos os i) contém zeros, porque muitos grafos não têm laços (uma aresta que conecta um vértice a si mesmo). Se o grafo permitir laços, o valor na diagonal principal representará a presença (ou o peso) de tal laço.
Vantagens e Desvantagens da Matriz de Adjacência
Vantagens:
Acesso direto: A verificação da existência de uma aresta entre dois vértices é realizada em tempo constante.
Representação intuitiva: É fácil visualizar e entender, especialmente para grafos pequenos.
Desvantagens:
Uso de espaço: Para um grafo com V vértices, é necessário V² espaço, o que pode ser ineficiente para grafos grandes e esparsos.
Iterar sobre os vizinhos: Em um grafo esparso, descobrir os vizinhos de um vértice exige que se verifique toda uma linha ou coluna, o que pode ser ineficiente.
Exemplo
Para o grafo com vértices A,B,C e arestas (A,B),(B,C):
A matriz de adjacência (não ponderada) seria:
A B C
A [0, 1, 0]
B [1, 0, 1]
C [0, 1, 0]
Se este fosse um grafo ponderado, onde a aresta (A,B) tem peso 3 e (B,C) tem peso 2, a matriz seria:
A B C
A [0, 3, 0]
B [3, 0, 2]
C [0, 2, 0]
Exemplo de Solução de Problema de Rota
Apresentaremos um problema de Rota, onde teremos apenas 5 pontes para ir do ponto A ao ponto C.
Nele apresentaremos uma proposta descritiva e depois uma proposta em Python.
Vamos ao grafo dado:
Vértices:A,B,C,D,E Ligações: A−B,B−E,E−C,D−A,B−C
A matriz de adjacência é uma matriz n×n onde n é o número de vértices. A entrada M(i,j) será 1 se o vértice i estiver ligado ao vértice j e 0 caso contrário.
Resolvendo o problema com python
Uma maneira simples de fazer isso é usando uma busca em largura (BFS). Vamos criar um exemplo em Python para isso:
import heapq
def heuristic(node, goal):
# Como um grafo não possui coordenadas espaciais, podemos usar uma heurística trivial.
return 0
def a_star(graph, start, goal):
open_list = [(0, start)]
g_costs = {node: float('inf') for node in range(len(graph))}
g_costs[start] = 0
came_from = {}
while open_list:
current_cost, current_node = heapq.heappop(open_list)
if current_node == goal:
path = []
while current_node in came_from:
path.insert(0, current_node)
current_node = came_from[current_node]
path.insert(0, start)
return path
for neighbor, cost in enumerate(graph[current_node]):
if cost == 1: # Existe uma aresta
tentative_g_cost = g_costs[current_node] + 1
if tentative_g_cost < g_costs[neighbor]:
came_from[neighbor] = current_node
g_costs[neighbor] = tentative_g_cost
f_cost = tentative_g_cost + heuristic(neighbor, goal)
heapq.heappush(open_list, (f_cost, neighbor))
return None
graph = [
[0, 1, 0, 1, 0], # A
[1, 0, 1, 0, 1], # B
[0, 1, 0, 0, 1], # C
[1, 0, 0, 0, 0], # D
[0, 1, 1, 0, 0] # E
]
path = a_star(graph, 0, 2)
if path:
print(" -> ".join(chr(65 + node) for node in path))
else:
print("Não foi encontrado um caminho de A para C.")
Resultado:
A -> B -> C
Outros usos de Grafo:
Outro problema complexo
Agora teremos como objetivo desenvolver um NLP que irá analisar de comandos dados de forma textual, utilizando grafos como base de tomada de decisão.
Para isso temos duas tabelas:
Palavras: Contem uma lista de palavras usadas nos textos.
Comandos: Contem uma lista de comandos possíveis.
Usaremos como exemplo de vértice apenas quando duas palavras em sequencia estiverem atendidas em determinado grafo, ai ligaremos estes aos comandos.
Tabela Palavras:
Esta tabela contém uma lista de palavras chave que podem ser usadas para determinar ações.
Palavras
Grave
Diário
Reproduza
Música
Ligue
Luz
Tabela Ações:
Esta tabela associa sequências de palavras a ações específicas.
Sequência de Palavras
Ação
Grave Diário
Gravação de entradas no diário
Reproduza Música
Tocar música
Ligue Luz
Acender a luz
Neste caso, o grafo seria algo assim:
O vértice “Grave” tem uma aresta direcionada para “Diário”, que representa a ação “Gravação de entradas no diário”.
O vértice “Reproduza” tem uma aresta direcionada para “Música”, representando a ação “Tocar música”.
O vértice “Ligue” tem uma aresta direcionada para “Luz”, representando a ação “Acender a luz”.
A ideia aqui é que, se alguém dissesse “Grave meu Diário”, o sistema reconheceria a sequência “Grave Diário” e acionaria a função correspondente de “Gravação de entradas no diário”. As stop words, como “meu”, seriam ignoradas pelo sistema.
Para implementar isso, você poderia criar um dicionário em Python que mapeia sequências de palavras (arestas) a ações, e então usar esse dicionário para determinar a ação apropriada com base na entrada do usuário.
Passos:
Instalar as bibliotecas necessárias
Configurar o banco de dados
Criar a tabela de arestas no banco de dados
Implementar funções em Python para interagir com o banco de dados
1. Instalar as bibliotecas necessárias
Certifique-se de que você tem o MySQL instalado e em execução. Depois, você pode instalar o conector MySQL para Python:
Crie um novo banco de dados chamado graph_db e um usuário para esse banco de dados. Você pode fazer isso usando a interface de linha de comando do MySQL ou um cliente GUI como o MySQL Workbench.
Criação do Banco
Aqui está uma sugestão de estrutura:
words: Guarda os vértices do tipo palavra.
commands: Guarda os vértices do tipo comando.
edges: Guarda as arestas, referenciando palavras e comandos.
SQL para criação das tabelas:
CREATE DATABASE graph_db;
USE graph_db;
-- Tabela de palavras
CREATE TABLE words (
word_id INT AUTO_INCREMENT PRIMARY KEY,
word_name VARCHAR(50) UNIQUE NOT NULL
);
-- Tabela de comandos
CREATE TABLE commands (
command_id INT AUTO_INCREMENT PRIMARY KEY,
command_name VARCHAR(50) UNIQUE NOT NULL
);
-- Tabela de arestas
CREATE TABLE edges (
edge_id INT AUTO_INCREMENT PRIMARY KEY,
word_id1 INT,
word_id2 INT,
command_id INT,
FOREIGN KEY (word_id1) REFERENCES words(word_id),
FOREIGN KEY (word_id2) REFERENCES words(word_id),
FOREIGN KEY (command_id) REFERENCES commands(command_id)
);
Nesta estrutura:
A tabela words tem um ID único para cada palavra e um nome que é exclusivo.
A tabela commands tem um ID único para cada comando e um nome que é exclusivo.
A tabela edges tem um ID único para cada aresta. As colunas word_id e command_id são chaves estrangeiras que apontam para os IDs nas tabelas words e commands, respectivamente.
Com essa estrutura, a tabela edges representa as relações entre palavras e comandos. Isso significa que cada entrada (linha) na tabela edges é uma relação entre uma palavra específica na tabela words e um comando específico na tabela commands.
Configurando aplicação e Banco de dados
Iremos primeiramente criar as ferramentas basicas para cadastrar as informações e o ambiente.
Então temos a conexão com o banco de dados.
import mysql.connector
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words('portuguese'))
# Configuração da conexão com o banco
DB_CONFIG = {
"host": "localhost",
"user": "your_username",
"password": "your_password",
"database": "graph_db"
}
"""Cria arestas com base em frases de exemplo."""
frases = [
"Comece a gravação de áudio",
"Salve esse texto importante",
"Defina um alerta para amanhã",
"Quero a gravação dessa reunião",
"Salve a anotação rapidamente"
]
comandos = [
"Iniciar gravação",
"Salvar texto",
"Configurar alerta",
"Iniciar gravação",
"Salvar anotação"
]
Criaremos a função de criar a conexão:
def connect_to_database():
"""Retorna uma conexão com o banco de dados."""
return mysql.connector.connect(**DB_CONFIG)
Criamos agora a função de pegar o ID:
def get_id(name, table):
"""Busca o ID de um item pelo nome, na tabela especificada."""
connection = connect_to_database()
cursor = connection.cursor()
column = "word_name" if table == "words" else "command_name"
query = f"SELECT * FROM {table} WHERE {column}=%s"
cursor.execute(query, (name,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
Agora criamos a função que popula as arestas:
def populaArestas(word1, word2, command):
"""Popula a tabela edges com as relações entre palavras e comando."""
connection = connect_to_database()
cursor = connection.cursor()
word1_id = get_id(word1, 'words')
word2_id = get_id(word2, 'words')
command_id = get_id(command, 'commands')
if not word1_id or not word2_id or not command_id:
print(f"Erro: Palavras ou comando não encontrados: '{word1}', '{word2}', '{command}'")
return
insert_query = "INSERT INTO edges (word_id, command_id) VALUES (%s, %s)"
# Inserindo relação da primeira palavra com o comando
cursor.execute(insert_query, (word1_id, command_id))
# Inserindo relação da segunda palavra com o comando
cursor.execute(insert_query, (word2_id, command_id))
connection.commit()
cursor.close()
connection.close()
Agora iremos criar os nossos comandos, para isso temos duas funções:
CadastraCMD que cria o registro de comandos.
ExemploCMD que monta os exemplos que iremos usar.
def cadastreCMD(command_name):
"""Cadastra um novo comando na tabela commands."""
connection = connect_to_database()
cursor = connection.cursor()
insert_query = "INSERT INTO commands (command_name) VALUES (%s)"
try:
cursor.execute(insert_query, (command_name,))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir comando '{command_name}': {err}")
cursor.close()
connection.close()
def ExemploCMD():
for cmd in comandos:
cadastreCMD(cmd)
Agora iremos cadastrar nossas palavras, para isso iremos usar o exemplo a seguir:
CadastraWords – Cadastra a lista de palavras avaliadas nos textos
ExemploWords – Lista as frases, criando as palavras.
Serão implementadas da seguinte forma:
def CadastraWords(word_name):
"""Cadastra uma nova palavra na tabela words."""
connection = connect_to_database()
cursor = connection.cursor()
insert_query = "INSERT INTO words (word_name) VALUES (%s)"
try:
cursor.execute(insert_query, (word_name,))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir palavra '{word_name}': {err}")
cursor.close()
connection.close()
def ExemploWords():
for frase in frases:
palavras = frase.split() # Separa a frase em palavras individuais
for palavra in palavras:
# Ignoramos palavras muito comuns (stop words) e números
if palavra.lower() not in stop_words and not palavra.isnumeric():
CadastraWords(palavra)
Agora iremos criar a função:
get_id_from_Table – Retorna o ID de uma dado valor de uma dada tabela para uma dada coluna.
CriaArestas – Cria a tabela de relacionamento (grafo) de Palavras.
def get_id_words(value, column_name):
"""Retorna o ID associado a um valor em uma coluna e tabela específicos."""
connection = connect_to_database()
cursor = connection.cursor()
select_query = f"SELECT word_id FROM words WHERE {column_name} = %s"
cursor.execute(select_query, (value,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
def get_id_commands(value, column_name):
"""Retorna o ID associado a um valor em uma coluna e tabela específicos."""
connection = connect_to_database()
cursor = connection.cursor()
select_query = f"SELECT command_id FROM commands WHERE {column_name} = %s"
cursor.execute(select_query, (value,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
def CriaArestas(Word1, Word2, Cmd):
print(Word1)
print(Word2)
"""Cria uma aresta associando Word1 e Word2 ao comando Cmd."""
word1_id = get_id_words(Word1, "word_name")
word2_id = get_id_words(Word2, "word_name")
cmd_id = get_id_commands(Cmd, "command_name")
print(word1_id);
print(word2_id);
print(cmd_id);
if not word1_id or not word2_id or not cmd_id:
print("Erro: Um ou mais valores não foram encontrados no banco de dados.")
return
connection = connect_to_database()
cursor = connection.cursor()
insert_query = """
INSERT INTO edges (word_id1, word_id2, command_id)
VALUES (%s, %s, %s)
"""
try:
cursor.execute(insert_query, (word1_id, word2_id, cmd_id))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir aresta: {err}")
cursor.close()
connection.close()
Agora iremos povoar as arestas. Para isso usaremos a função:
ExemploAresta – Faz o cadastro das arestas baseado nas stop-words e palavras não numéricas.
def ExemploAresta():
for index, frase in enumerate(frases):
palavras = [palavra for palavra in frase.split() if palavra.lower() not in stop_words and not palavra.isnumeric()]
for i in range(len(palavras) - 1):
# Criamos arestas entre palavras sequenciais e associamos a um comando
CriaArestas(palavras[i], palavras[i+1], comandos[index])
Juntando tudo
Neste código podemos ver onde tudo se encaixa.
Onde criamos os exemplos, e finalizamos o cadastro.