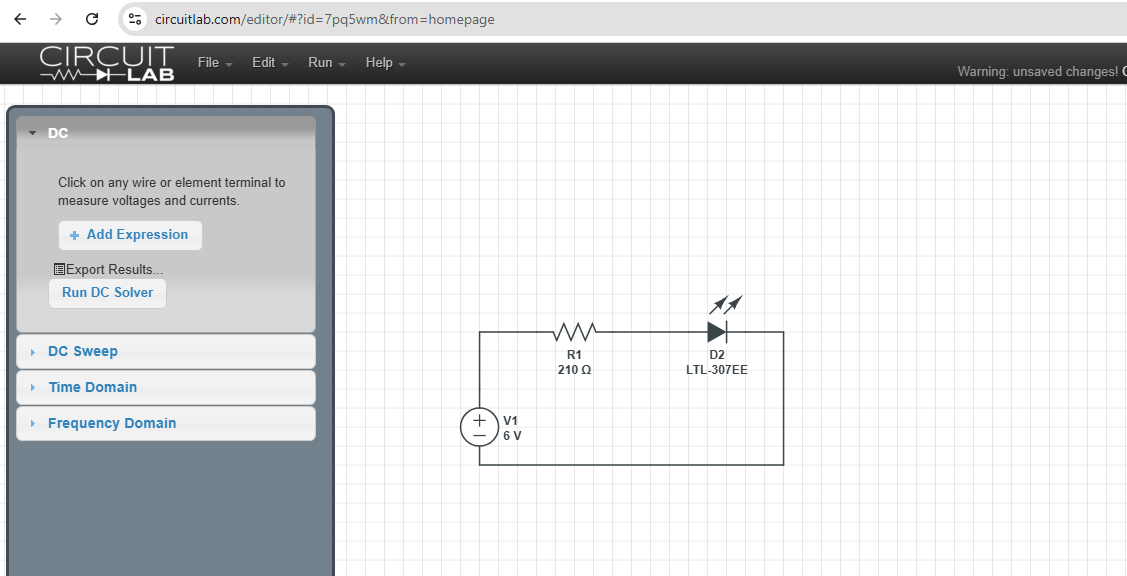
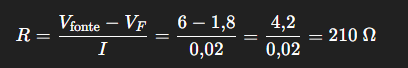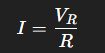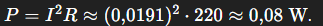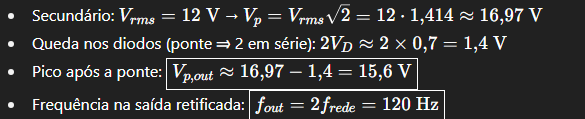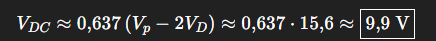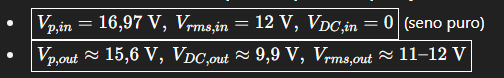A – Primeiro Bloco
1. O que é levantamento de requisitos
- É a etapa de coleta, análise, documentação e manutenção das necessidades do sistema.
- Serve para garantir que o software atenda às necessidades dos usuários e aos objetivos do negócio.
- É uma fase essencial para evitar erros, retrabalho, atrasos e custos extras.
Palavras-chave:
levantamento de requisitos, necessidades do usuário, objetivos do negócio, documentação, análise, ciclo de vida do projeto
2. Importância dos requisitos
- Funcionam como a base do projeto de software.
- Ajudam a alinhar cliente, equipe e stakeholders.
- Reduzem mal-entendidos e mudanças tardias.
- Melhoram a qualidade da entrega final.
Palavras-chave:
base do projeto, alinhamento, stakeholders, qualidade, comunicação, redução de riscos
3. Requisitos funcionais
- Descrevem o que o sistema deve fazer.
- Representam funções, ações e operações que o usuário pode executar.
- Exemplos:
- criar conta e fazer login;
- agendar consulta;
- cancelar ou reagendar consulta;
- enviar notificações automáticas.
Palavras-chave:
requisitos funcionais, funcionalidades, ações do sistema, operações, comportamento esperado
4. Requisitos não funcionais
- Descrevem como o sistema deve ser ou se comportar.
- Envolvem atributos de qualidade, como:
- desempenho;
- segurança;
- confiabilidade;
- usabilidade;
- compatibilidade;
- conformidade legal.
Palavras-chave:
requisitos não funcionais, desempenho, segurança, usabilidade, confiabilidade, conformidade, compatibilidade
5. Exemplos práticos apresentados
Aplicativo bancário
- Permitir transações, consulta de saldo e notificações.
- Definir tanto funcionalidades quanto comportamento esperado do sistema.
Aplicativo de agendamento de consultas
- Marcar, reagendar e cancelar consultas.
- Enviar lembretes e orientações preparatórias.
- Melhorar a gestão do tempo dos médicos.
Software de e-commerce
- Cadastro de usuários, carrinho de compras e checkout.
- Requisitos de escalabilidade, criptografia e conformidade.
Aplicativo de finanças pessoais
- Caso usado para mostrar mudanças de requisitos durante o projeto.
- Inclusão de novas funções e exigências regulatórias afetando prazo e custo.
Palavras-chave:
aplicativo bancário, clínica, e-commerce, finanças pessoais, exemplo prático, escopo
6. Técnicas e ferramentas de levantamento
- Uso de:
- entrevistas;
- brainstorming;
- workshops;
- análise de feedback;
- reuniões com stakeholders.
- Ferramentas citadas:
Palavras-chave:
entrevistas, brainstorming, workshops, stakeholders, JIRA, Azure DevOps, coleta de requisitos
7. Metodologias ágeis x tradicionais
- As abordagens tradicionais fazem levantamento e documentação mais detalhados antes da implementação.
- No modelo em cascata, os requisitos são definidos antes de seguir para as próximas fases.
- As abordagens ágeis tendem a ser mais adaptáveis a mudanças.
Palavras-chave:
metodologias ágeis, metodologias tradicionais, modelo cascata, adaptação, documentação, flexibilidade
8. Segurança e conformidade
- O sistema deve proteger dados sensíveis.
- Medidas citadas:
- autenticação em dois fatores;
- criptografia de dados;
- conformidade com normas como LGPD e, em exemplo internacional, HIPAA.
Palavras-chave:
segurança, autenticação, criptografia, LGPD, HIPAA, privacidade, proteção de dados
9. Gestão de mudanças em requisitos
- Mudanças podem surgir no meio do projeto e impactar:
- escopo;
- prazo;
- custo;
- recursos disponíveis.
- É importante ter um processo claro para:
- documentar mudanças;
- aprovar mudanças;
- implementar mudanças;
- comunicar impactos às partes interessadas.
Palavras-chave:
gestão de mudanças, escopo, prazo, custo, aprovação, documentação, impacto
10. Riscos no levantamento de requisitos
- Riscos podem comprometer a viabilidade do projeto.
- Técnicas citadas para identificar e avaliar riscos:
- análise qualitativa;
- análise quantitativa;
- análise de cenários;
- brainstorming;
- checklists baseados em projetos anteriores.
Palavras-chave:
riscos, análise qualitativa, análise quantitativa, cenários, checklist, mitigação
11. Comunicação com stakeholders
- A comunicação eficaz é essencial durante o levantamento e a gestão de mudanças.
- É necessário:
- compreender os stakeholders;
- criar plano de comunicação;
- negociar prioridades e impactos.
Palavras-chave:
comunicação, stakeholders, negociação, entendimento mútuo, plano de comunicação
Resumão final
O levantamento de requisitos é uma etapa fundamental do desenvolvimento de software, pois define o que o sistema deve fazer e como ele deve se comportar. Ele envolve técnicas de coleta, análise, documentação, validação e comunicação com as partes interessadas. Também exige atenção à segurança, à qualidade, aos riscos e à gestão de mudanças, para garantir que o projeto entregue valor real ao usuário e ao negócio.
B – Segundo Bloco
1. Conceito de testes funcionais
- Verificam se o software cumpre os requisitos definidos.
- Avaliam se o sistema se comporta como esperado para o usuário.
- Podem envolver teste de interface, APIs, banco de dados e fluxos do sistema.
Palavras-chave:
testes funcionais, requisitos, comportamento esperado, validação, conformidade
2. Objetivo principal dos testes funcionais
- Garantir que o software esteja de acordo com os requisitos funcionais.
- Identificar erros e comportamentos inesperados antes da entrega ao usuário.
Palavras-chave:
conformidade, requisitos funcionais, falhas, qualidade, validação
3. Etapas do processo de teste funcional
- Levantamento de requisitos
- Planejamento de teste
- Design de teste
- Preparação do ambiente de teste
- Execução de teste
- Registro de defeitos
- Relatório de teste
Palavras-chave:
levantamento, planejamento, design, ambiente de teste, execução, defeitos, relatório
4. Casos e cenários de teste
- Servem para verificar a cobertura dos requisitos.
- Devem considerar:
- entradas válidas e inválidas;
- resultado esperado;
- funções relevantes do sistema.
Palavras-chave:
casos de teste, cenários de teste, cobertura, entradas válidas, entradas inválidas, resultado esperado
5. Caminho feliz e condições não ideais
- Um bom teste não cobre só o caminho feliz.
- Também deve avaliar:
- erros;
- exceções;
- situações de uso não ideais;
- comportamento sob carga ou condições difíceis.
Palavras-chave:
caminho feliz, exceções, erros, carga, robustez, confiabilidade
6. Metodologias tradicionais x ágeis
Tradicionais
- Processo mais sequencial.
- Testes acontecem depois do desenvolvimento.
- Menor flexibilidade para mudanças.
- Feedback mais lento.
Ágeis
- Processo iterativo e incremental.
- Testes ocorrem em paralelo ao desenvolvimento.
- Correções mais rápidas.
- Mais colaboração entre desenvolvedores e testadores.
- Maior adaptação a mudanças.
Palavras-chave:
tradicional, ágil, cascata, sprint, iteração, feedback, colaboração, flexibilidade
7. Teste funcional no desenvolvimento ágil
- Os testes são integrados em cada sprint.
- Testadores participam do planejamento.
- Critérios de aceitação precisam ser testáveis.
- Ajuda na identificação rápida de defeitos.
- Uso frequente de testes automatizados para regressão e novas funcionalidades.
Palavras-chave:
sprint, critérios de aceitação, defeitos, regressão, integração contínua, desenvolvimento ágil
8. Automação de testes funcionais
- Indicada para testes repetitivos e estáveis.
- Boa quando o custo manual é alto.
- Deve usar ferramentas compatíveis com a tecnologia da equipe.
- Não elimina testes manuais e exploratórios.
Palavras-chave:
automação, testes repetitivos, scripts reutilizáveis, testes manuais, testes exploratórios
9. Estratégias de teste
- Uma estratégia eficaz começa com:
- análise de requisitos;
- perfil de risco.
- O objetivo é priorizar áreas mais críticas e mais suscetíveis a falhas.
Palavras-chave:
estratégia de teste, análise de requisitos, perfil de risco, priorização, áreas críticas
10. Gerenciamento de dados de teste
- Pode usar:
- dados sintéticos;
- dados reais anonimizados.
- Os dados devem representar:
- casos comuns;
- casos limite;
- situações reais do sistema.
Palavras-chave:
dados de teste, dados sintéticos, anonimização, casos limite, manutenção de dados
11. Ferramentas e tecnologias
- Automação de testes: Selenium, QTP, TestComplete
- Gestão de testes: JIRA, TestRail
- Integração contínua: Jenkins, Travis CI
Palavras-chave:
Selenium, QTP, TestComplete, JIRA, TestRail, Jenkins, Travis CI
12. Qualidade e testes
- Teste está ligado à qualidade do software.
- As melhores práticas reduzem erros e aumentam a confiança no produto final.
- A qualidade deve ser acompanhada ao longo do ciclo de desenvolvimento.
Palavras-chave:
qualidade, garantia de qualidade, melhores práticas, confiança, ciclo de desenvolvimento
13. Avaliação de riscos
- A equipe deve identificar e priorizar riscos:
- técnicos;
- de negócios;
- de usabilidade.
- Depois, selecionar os principais riscos e propor ações preventivas.
Palavras-chave:
avaliação de risco, riscos técnicos, riscos de negócios, usabilidade, mitigação, priorização
Resumão final
Os testes funcionais garantem que o software entregue ao usuário esteja funcionando conforme os requisitos definidos. Eles envolvem planejamento, criação de cenários, execução, registro de defeitos e análise de resultados. No modelo ágil, os testes são contínuos e integrados às sprints. Além disso, a qualidade dos testes depende de boa estratégia, dados de teste adequados, automação bem aplicada e análise de riscos.
C – Terceiro bloco
1. O que são testes de software
- São processos usados para avaliar a qualidade do software.
- Verificam se o sistema atende aos critérios de exigência.
- Envolvem a execução do programa para encontrar erros e confirmar se o comportamento está conforme o esperado.
Palavras-chave:
testes de software, qualidade, erros, critérios de exigência, comportamento esperado
2. Importância dos testes
- Ajudam a garantir a qualidade da entrega.
- Evitam problemas na operação da empresa.
- Validam funcionalidades e ajudam a atender requisitos do usuário e expectativas do negócio.
Palavras-chave:
qualidade da entrega, operação, requisitos do usuário, expectativas do negócio, validação
3. Objetivos dos testes de software
- Verificação: confirmar que o software atende aos requisitos técnicos e funcionais.
- Validação: assegurar que atende às necessidades do usuário final.
- Descoberta de defeitos: identificar e documentar falhas.
- Garantia de qualidade: dar confiança aos stakeholders.
- Prevenção de defeitos: usar os resultados para evitar erros futuros.
Palavras-chave:
verificação, validação, defeitos, garantia de qualidade, prevenção de erros, stakeholders
4. Níveis de teste
- A aula destaca a diferenciação entre:
- testes unitários;
- testes de integração;
- testes de sistema;
- testes de aceitação.
Palavras-chave:
teste unitário, teste de integração, teste de sistema, teste de aceitação
5. Testes funcionais
- Verificam se o sistema está de acordo com os requisitos funcionais.
- O foco é testar as funcionalidades do software.
- Exemplo: em um e-commerce, verificar carrinho, cálculo do total, cupons e checkout.
Palavras-chave:
testes funcionais, funcionalidades, requisitos funcionais, carrinho, checkout
6. Testes não funcionais
- Avaliam aspectos como:
- desempenho;
- usabilidade;
- confiabilidade;
- segurança.
- Exemplo: testar carga de acessos simultâneos, segurança do pagamento e facilidade de navegação.
Palavras-chave:
testes não funcionais, desempenho, usabilidade, confiabilidade, segurança, carga
7. Testes automatizados
- Usam ferramentas para executar testes sem intervenção humana contínua.
- São úteis para tarefas repetitivas e grandes volumes de código.
- Exemplos citados:
Palavras-chave:
testes automatizados, automação, Selenium, JUnit, repetição, eficiência
8. Testes manuais
- São executados por testadores sem automação.
- São úteis em cenários mais complexos ou que exigem intuição humana.
- Têm mais flexibilidade para detectar problemas inesperados, embora sejam mais lentos.
Palavras-chave:
testes manuais, intuição humana, flexibilidade, cenários complexos, experiência do usuário
9. Testes de regressão
- Verificam se mudanças recentes no sistema afetaram negativamente funcionalidades já existentes.
- São importantes para identificar problemas sutis após alterações no código.
- Podem ser implementados com automação e integração contínua, usando ferramentas como:
Palavras-chave:
teste de regressão, mudança de código, funcionalidade existente, GitLab CI/CD, Jenkins
10. Plano de testes
As etapas destacadas para desenvolver um plano de testes são:
- análise de requisitos;
- definição de escopo;
- estratégia de testes;
- alocação de recursos;
- cronograma;
- gestão de riscos;
- critérios de entrada e saída.
Palavras-chave:
plano de testes, requisitos, escopo, estratégia, recursos, cronograma, riscos, critérios
11. Organização e priorização de casos de teste
Os casos de teste devem ser priorizados com base em:
- importância do negócio;
- frequência de uso;
- complexidade e risco;
- impacto da falha.
Palavras-chave:
priorização, casos de teste, importância do negócio, risco, impacto da falha
12. Métricas de teste
As aulas destacam o uso de métricas para medir o progresso e a eficácia dos testes, como:
- taxa de cobertura de teste;
- taxa de sucesso/falha;
- número de defeitos encontrados por ciclo;
- tempo médio para correção de defeitos.
Palavras-chave:
métricas, cobertura de teste, sucesso, falha, defeitos, progresso, eficácia
13. Exemplo prático apresentado
Foi usada uma aplicação de to-do list chamada TaskMaster para exercitar plano de testes. Os requisitos incluíam:
- criar tarefa;
- editar tarefa;
- excluir tarefa;
- marcar como completa;
- filtrar tarefas por status.
Palavras-chave:
TaskMaster, to-do list, criar tarefa, editar tarefa, excluir tarefa, completar tarefa, filtro
14. Ideia central das aulas
As aulas mostram que testar software não é só procurar erro: é também organizar estratégia, definir prioridades, medir resultados e garantir que o sistema funcione com qualidade e segurança.
Palavras-chave:
estratégia de teste, qualidade, segurança, organização, eficiência
Resumão final
Os testes de software existem para garantir que o sistema funcione corretamente, atenda aos requisitos e entregue qualidade ao usuário e ao negócio. Eles incluem testes funcionais, não funcionais, manuais, automatizados e de regressão. Além disso, um bom processo de teste depende de planejamento, priorização, métricas e gestão de riscos.
D – Quarto bloco
1. O que é modelagem de dados
- É o processo de definir, analisar e organizar os dados necessários para apoiar os processos de negócio.
- Os dados são mapeados para que possam ser armazenados em banco de dados.
- Ajuda a estruturar informações de forma útil, acessível e eficiente.
Palavras-chave:
modelagem de dados, organização dos dados, processos de negócio, banco de dados, estruturação
2. Importância da modelagem de dados
- Facilita a comunicação entre desenvolvedores e usuários de negócio.
- É fundamental para criar sistemas de informação eficientes.
- Busca garantir dados de alta qualidade, bem estruturados e prontos para uso.
Palavras-chave:
comunicação, usuários de negócio, qualidade dos dados, eficiência, sistemas de informação
3. Objetivos da modelagem de dados
- Representar visualmente as regras de negócio.
- Mostrar como os dados interagem entre si.
- Preparar a base para desenvolvimento, armazenamento e manutenção das informações.
Palavras-chave:
regras de negócio, interação entre dados, representação visual, manutenção, desenvolvimento
4. Tipos de modelos de dados
As aulas destacam três tipos principais:
a) Modelo conceitual
- É um modelo de alto nível.
- Foca na visão do negócio e nas necessidades iniciais do projeto.
- É usado para alinhar analistas e usuários finais sem entrar em detalhes técnicos.
Palavras-chave:
modelo conceitual, alto nível, visão do negócio, fase inicial, necessidades de negócio
b) Modelo lógico
- É mais detalhado que o conceitual.
- Define entidades, atributos e relacionamentos.
- Não se preocupa ainda com a forma física de armazenamento.
Palavras-chave:
modelo lógico, entidades, atributos, relacionamentos, estrutura do banco
c) Modelo físico
- Mostra como os dados serão armazenados de fato.
- Inclui detalhes técnicos como tabelas, colunas, índices, partições e estratégias de armazenamento.
- É usado para construir o banco real e otimizar desempenho.
Palavras-chave:
modelo físico, tabelas, colunas, índices, partições, desempenho, armazenamento
5. Normalização de dados
- É o processo de organizar os dados para reduzir redundância e melhorar a integridade.
- Envolve dividir tabelas grandes em tabelas menores e relacionadas.
- Ajuda na manutenção, consistência e evolução do banco de dados.
Palavras-chave:
normalização, redundância, integridade, consistência, tabelas relacionadas
6. Benefícios da normalização
- Diminui duplicidade de dados.
- Melhora a integridade dos dados.
- Facilita a manutenção e atualização.
- Torna o armazenamento mais eficiente.
Palavras-chave:
duplicidade, integridade, manutenção, eficiência, organização
7. SGBD – Sistemas de Gerenciamento de Banco de Dados
- São softwares usados para criar, manipular e interagir com bancos de dados.
- Funcionam com base em um modelo de dados e, geralmente, em uma linguagem de consulta como SQL.
- Exemplos citados:
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
- MongoDB
Palavras-chave:
SGBD, SQL, MySQL, PostgreSQL, Oracle, SQL Server, MongoDB
8. Modelos de dados quanto à tecnologia
Relacional
- Usa tabelas para representar dados e relações.
- Adequado para dados estruturados e consultas complexas.
NoSQL
- Permite armazenar dados em formatos menos rígidos.
- Pode ser orientado a documentos, colunar ou gráfico.
NewSQL
- Combina o modelo relacional com escalabilidade de sistemas NoSQL.
- Mantém propriedades ACID e é útil em ambientes com muitas transações.
Palavras-chave:
relacional, NoSQL, NewSQL, escalabilidade, ACID, consultas complexas
9. Integridade e segurança de dados
- Integridade significa precisão e consistência dos dados ao longo do tempo.
- Segurança protege contra acesso não autorizado, corrupção ou perda.
Práticas recomendadas:
- controle de acesso;
- criptografia em repouso e em trânsito;
- backups regulares;
- auditoria e monitoramento;
- validação e restrições de integridade.
Palavras-chave:
integridade, segurança, controle de acesso, criptografia, backup, auditoria, validação
10. Design de dados
- É a etapa que define como os dados serão armazenados, acessados e mantidos.
- Envolve metodologias como:
- modelagem conceitual;
- modelagem lógica;
- normalização;
- modelagem física.
Palavras-chave:
design de dados, armazenamento, acesso, manutenção, metodologias
11. Arquitetura de dados
- É o quadro que organiza dados, tecnologia, infraestrutura e serviços analíticos para atender às necessidades do negócio.
As aulas citam exemplos de arquitetura:
- arquitetura tradicional com data warehouse;
- data lakes para dados brutos e estruturados;
- arquitetura orientada a serviços com serviços de dados reutilizáveis.
Palavras-chave:
arquitetura de dados, data warehouse, data lake, serviços de dados, infraestrutura, analytics
12. Escalabilidade e futuro dos dados
- O design e a arquitetura de dados devem permitir que o sistema cresça e se adapte às mudanças do negócio.
- Tendências citadas:
- Big Data e Analytics Avançado;
- Internet das Coisas (IoT);
- Blockchain;
- Data as a Service (DaaS);
- privacidade e conformidade, como LGPD.
Palavras-chave:
escalabilidade, Big Data, analytics, IoT, blockchain, DaaS, LGPD, conformidade
13. Exemplos práticos trabalhados nas aulas
- Inventário de empresa/e-commerce: criação de plano de modelagem com modelos conceitual, lógico e físico.
- Universidade: exemplo de modelagem conceitual com alunos, cursos e matrículas.
- E-commerce: exemplo de modelagem lógica com usuários, produtos, pedidos e pagamentos.
- Livraria on-line: atividade para definir entidades, atributos e relacionamentos.
Palavras-chave:
inventário, universidade, e-commerce, livraria on-line, entidades, atributos, relacionamentos
14. Ideia central das aulas
As aulas mostram que a modelagem de dados é a base para construir sistemas bem organizados, seguros, escaláveis e alinhados às necessidades do negócio. Ela começa em um nível mais abstrato, passa pelo detalhamento lógico e chega à implementação física, sempre com foco em qualidade, integridade e eficiência.
Palavras-chave:
base do sistema, organização, escalabilidade, integridade, eficiência, negócio
Resumão final
A modelagem de dados é o processo de planejar e estruturar os dados de um sistema. Ela envolve os modelos conceitual, lógico e físico, além de práticas como normalização, segurança, integridade e definição da arquitetura de dados. Tudo isso serve para garantir bancos de dados mais consistentes, eficientes e preparados para crescer com o negócio.
E – Quinto bloco
1. O que é UML
- UML significa Unified Modeling Language.
- É uma linguagem padrão de modelagem usada para visualizar, especificar, construir e documentar sistemas de software.
- Seu papel é criar uma linguagem comum entre todos os envolvidos no desenvolvimento.
Palavras-chave:
UML, linguagem padrão, modelagem, visualização, documentação, linguagem comum
2. Origem e evolução da UML
- Surgiu no início dos anos 1990, quando a modelagem orientada a objetos crescia, mas ainda sem padronização.
- A UML unificou métodos como:
- Booch
- OMT (Rumbaugh)
- OOSE (Jacobson)
- A unificação começou com Booch e Rumbaugh na Rational Software, depois com Jacobson.
- A UML 1.0 virou padrão oficial em 1997, após adoção pela OMG.
Palavras-chave:
anos 1990, Booch, OMT, OOSE, Rational Software, OMG, padronização, evolução
3. Importância da UML
- Facilita a comunicação entre equipe técnica e stakeholders.
- Ajuda na documentação de software.
- Apoia o entendimento da estrutura e do comportamento do sistema.
- Serve como ponte entre ideia, projeto, implementação e manutenção.
Palavras-chave:
comunicação, stakeholders, documentação, entendimento, manutenção, desenvolvimento
4. Elementos básicos da UML
Os principais elementos citados são:
a) Classes
- Representam entidades ou conceitos.
- Possuem atributos e operações/métodos.
b) Objetos
- São instâncias das classes em tempo de execução.
c) Relacionamentos
- Conexões entre classes e objetos.
- Exemplos:
- associação
- generalização/herança
- dependência
d) Diagramas
- Representações gráficas dos elementos e de seus relacionamentos.
Palavras-chave:
classes, objetos, atributos, métodos, relacionamentos, associação, herança, dependência, diagramas
5. Diagramas de caso de uso
- Representam as funcionalidades do sistema sob a perspectiva do usuário.
- Mostram a interação entre o sistema e os atores.
- Cada caso de uso é representado por uma elipse.
- A ligação entre ator e caso de uso é feita por linha sólida.
- Pode haver relações de inclusão e extensão entre casos de uso.
Palavras-chave:
caso de uso, ator, funcionalidade, perspectiva do usuário, elipse, inclusão, extensão
6. Diagramas de classe
- São o pilar da modelagem orientada a objetos.
- Representam a estrutura estática do sistema.
- Mostram:
- nome da classe;
- atributos;
- métodos/operações;
- relações entre classes.
- As classes aparecem em caixas divididas em três partes.
- A herança é mostrada com seta vazada para a classe pai.
- Associações são mostradas com linhas sólidas.
Palavras-chave:
diagrama de classe, estrutura estática, atributos, métodos, herança, associação, caixa de classe
7. Diagramas de sequência
- Mostram como os objetos interagem ao longo do tempo.
- Representam a sequência temporal das mensagens trocadas entre objetos.
- Usam:
- linhas verticais para participantes;
- setas horizontais para mensagens.
Palavras-chave:
diagrama de sequência, interação, sequência temporal, mensagens, participantes
8. Diagramas de colaboração
- Também chamados de diagramas de comunicação.
- Focam a organização estrutural dos objetos que interagem.
- São parecidos com os diagramas de sequência, mas destacam mais a relação entre objetos do que a ordem temporal.
Palavras-chave:
diagrama de colaboração, diagrama de comunicação, organização estrutural, interação entre objetos
9. Diagramas de atividade
- Representam fluxos de trabalho e processos de negócio.
- Mostram:
- início do processo;
- atividades;
- decisões;
- transições;
- término do processo.
Elementos técnicos
- nó inicial e final
- atividades
- decisões
- sincronização e concorrência
- transições com guardas
Palavras-chave:
diagrama de atividade, fluxo de trabalho, processo de negócio, decisão, transição, concorrência, guarda
10. Diagramas de estado
- Capturam os diferentes estados de um objeto ao longo do seu ciclo de vida.
- Mostram as transições entre estados.
- São úteis para modelar objetos dinâmicos com comportamentos diferentes em cada fase.
Elementos técnicos
- estados
- transições
- eventos
- ações
- estado inicial e final
Palavras-chave:
diagrama de estado, ciclo de vida, estados, transições, eventos, ações
11. Diagramas de componentes e implantação
- As aulas apontam esses diagramas como importantes para representar a arquitetura e a organização dos componentes físicos do software.
Palavras-chave:
diagramas de componentes, implantação, arquitetura, componentes físicos, organização
12. UML no ciclo de vida do software
- A UML pode ser usada desde a concepção das ideias até:
- análise;
- projeto;
- implementação;
- documentação;
- manutenção.
- Cada tipo de diagrama ajuda a enxergar um aspecto diferente do sistema.
Palavras-chave:
ciclo de vida, análise, projeto, implementação, manutenção, documentação
13. UML no desenvolvimento ágil
- No ágil, a UML é usada de forma seletiva.
- O foco não é documentação extensa, mas comunicação rápida e clara.
- Pode ser usada em:
- planejamento de sprint;
- discussão com stakeholders;
- esclarecimento de fluxos e funcionalidades.
Palavras-chave:
desenvolvimento ágil, comunicação rápida, sprint, stakeholders, documentação leve
14. Exemplos práticos citados
- Pedido online: seleção de produtos, checkout, pagamento e confirmação em diagrama de atividade.
- Leilão online: escolha do produto, lance, validação do maior lance e envio de notificações.
- Resgate de senha em e-commerce: solicitar recuperação, enviar e-mail, clicar no link e criar nova senha.
Palavras-chave:
pedido online, leilão online, resgate de senha, e-commerce, fluxo, notificação
15. Ideia central das aulas
As aulas mostram que a UML é uma ferramenta essencial para entender, comunicar, documentar e projetar software, usando diferentes diagramas para representar estrutura, comportamento, interação e fluxo do sistema.
Palavras-chave:
estrutura, comportamento, interação, fluxo, documentação, comunicação, projeto
Resumão final
A UML é uma linguagem padrão de modelagem que ajuda a representar sistemas de software de forma visual e organizada. Seus principais elementos são classes, objetos, relacionamentos e diagramas. Entre os diagramas mais importantes estão os de caso de uso, classe, sequência, colaboração, atividade e estado. Ela pode ser usada tanto em processos tradicionais quanto no desenvolvimento ágil, sempre ajudando na comunicação, documentação e compreensão do sistema.
F – Sexto Bloco
1. O que é POO
- A programação orientada a objetos é um paradigma baseado na criação de objetos.
- Esses objetos unem dados (estado) e comportamentos (ações/métodos).
- A POO ajuda a criar programas mais fáceis de entender, modificar e manter.
Palavras-chave:
POO, paradigma, objetos, estado, comportamento, manutenção, organização
2. Fundamentos básicos da POO
- Os conceitos centrais apresentados são:
- classes;
- objetos;
- atributos;
- métodos.
Palavras-chave:
classes, objetos, atributos, métodos, estrutura, comportamento
3. Classe
- A classe é o molde ou modelo usado para criar objetos.
- Ela descreve características e comportamentos que os objetos terão.
- Exemplo da aula: a classe Automóvel define marca, modelo, cor e ações como acelerar e frear.
Palavras-chave:
classe, molde, modelo, automóvel, características, comportamentos
4. Objeto
- O objeto é a instância concreta criada a partir de uma classe.
- É a representação real de algo descrito pela classe.
- Exemplo: um Ford Mustang vermelho de 2020 é um objeto da classe Automóvel.
Palavras-chave:
objeto, instância, exemplo concreto, instanciamento, automóvel
5. Método
- Os métodos representam as ações que os objetos podem executar.
- Funcionam como funções dentro da classe.
- Exemplo:
ligarMotor, acelerar, frear, exibirDetalhes.
Palavras-chave:
método, ação, comportamento, função, operação
6. Quatro pilares da POO
A POO é baseada em quatro princípios fundamentais:
a) Encapsulamento
- Protege os dados internos do objeto.
- O acesso ocorre por meio de métodos definidos.
- Ajuda a evitar estados inconsistentes.
Palavras-chave:
encapsulamento, proteção de dados, controle de acesso, integridade
b) Abstração
- Simplifica a complexidade do mundo real.
- Foca no que é essencial e ignora detalhes menos importantes.
Palavras-chave:
abstração, simplificação, foco no essencial, complexidade
c) Herança
- Permite que uma classe herde características e comportamentos de outra.
- Favorece reutilização de código e organização hierárquica.
Palavras-chave:
herança, reutilização, classe pai, classe filha, hierarquia
d) Polimorfismo
- Permite usar uma interface comum para objetos diferentes.
- Cada objeto pode responder de forma própria ao mesmo método.
Palavras-chave:
polimorfismo, interface comum, respostas diferentes, flexibilidade
7. Benefícios da POO
- Reutilização de código
- Modularidade
- Facilidade de manutenção
- Melhor organização
- Solução de problemas complexos
Palavras-chave:
reutilização, modularidade, manutenção, organização, flexibilidade
8. POO e mundo real
- A POO incentiva pensar em objetos do mundo real durante o desenvolvimento.
- Isso torna o projeto mais intuitivo e mais alinhado ao problema que se quer resolver.
Palavras-chave:
mundo real, modelagem, intuição, domínio do problema
9. Divisão de contexto em classes
- As aulas mostram como pegar um problema real e separar em classes.
- Exemplo trabalhado:
- Cliente
- Pedido
- Produto
- Pagamento
- Também é importante definir:
- atributos;
- métodos;
- relacionamentos entre classes.
Palavras-chave:
análise de contexto, classes, cliente, pedido, produto, pagamento, relacionamentos
10. Design orientado a objetos
- É a organização do sistema com base em objetos e classes.
- Serve para planejar software de forma mais robusta e manutenível.
Palavras-chave:
design orientado a objetos, planejamento, organização, robustez, manutenção
11. Padrões de projeto
São soluções típicas para problemas recorrentes em design de software. As aulas citam três grupos:
a) Criacionais
- Relacionados à criação de objetos.
- Exemplos: Singleton, Factory, Builder.
b) Estruturais
- Relacionados à composição de classes e objetos.
- Exemplos: Adapter, Decorator, Composite.
c) Comportamentais
- Relacionados à comunicação e responsabilidade entre objetos.
- Exemplos: Observer, Strategy, Command.
Palavras-chave:
padrões de projeto, criacionais, estruturais, comportamentais, Singleton, Factory, Observer
12. Princípios SOLID
As aulas apresentam os cinco princípios SOLID para construir sistemas mais compreensíveis, flexíveis e manuteníveis:
- S – Responsabilidade Única
- O – Aberto/Fechado
- L – Substituição de Liskov
- I – Segregação de Interface
- D – Inversão de Dependência
Palavras-chave:
SOLID, responsabilidade única, aberto/fechado, Liskov, segregação de interface, inversão de dependência
13. Refatoração e testes em POO
- A aplicação prática da POO também envolve:
- refatoração de código;
- testes unitários;
- uso de mock para validar a lógica dos objetos.
Palavras-chave:
refatoração, testes unitários, mock, qualidade, validação
14. Aplicação prática
- A terceira aula mostra que os pilares da POO ajudam a construir sistemas:
- flexíveis;
- manuteníveis;
- preparados para evoluir com novas demandas.
Palavras-chave:
sistemas flexíveis, manuteníveis, evolução, longo prazo
Resumão final
A programação orientada a objetos organiza o software com base em classes e objetos, reunindo atributos e métodos. Seus quatro pilares são encapsulamento, abstração, herança e polimorfismo. Além disso, a POO se conecta com design orientado a objetos, padrões de projeto, SOLID, refatoração e testes, tudo para criar sistemas mais organizados, reutilizáveis e fáceis de manter.
G- Setimo bloco
1. O que é elicitação de requisitos
- É o processo de coletar requisitos do cliente, dos usuários e das demais partes interessadas.
- É uma das fases mais críticas do desenvolvimento de software.
- Seu objetivo é garantir que os requisitos sejam completos, claros e validados.
Palavras-chave:
elicitação de requisitos, coleta, cliente, usuários, requisitos claros, requisitos validados
2. Importância da elicitação
- Define o que será necessário para o projeto ter sucesso.
- Ajuda a entender as necessidades reais do negócio e dos usuários.
- Reduz riscos, falhas de comunicação e retrabalho.
Palavras-chave:
sucesso do projeto, necessidades do negócio, entendimento, alinhamento, redução de riscos
3. Tipos de requisitos
As aulas destacam três tipos principais:
a) Requisitos de usuário
- São descritos em linguagem natural e diagramas.
- Focam no que o usuário precisa e espera do sistema.
- Devem ser compreensíveis por todos os envolvidos.
b) Requisitos de sistema
- São mais técnicos e detalhados.
- Servem como guia para a equipe de desenvolvimento construir o sistema.
c) Requisitos funcionais
- Especificam o comportamento interno do sistema.
- Descrevem o que o sistema fará em determinadas condições ou entradas.
Palavras-chave:
requisitos de usuário, requisitos de sistema, requisitos funcionais, linguagem natural, detalhamento técnico
4. Técnicas de elicitação
As técnicas mais citadas são:
a) Entrevistas
- Conversas diretas com stakeholders.
- Permitem entender necessidades, expectativas e até conhecimentos tácitos.
- São flexíveis e profundas, pois o entrevistador pode adaptar as perguntas em tempo real.
b) Questionários
- Conjunto de perguntas escritas para coletar respostas de muitas pessoas.
- Úteis para obter uma variedade maior de necessidades e opiniões.
c) Workshops
- Reuniões colaborativas com vários stakeholders.
- Servem para discutir, definir e alinhar requisitos.
d) Observação
- Consiste em analisar o ambiente de trabalho do usuário e como ele executa suas tarefas.
- Ajuda a identificar requisitos que nem sempre são verbalizados.
Palavras-chave:
entrevistas, questionários, workshops, observação, stakeholders, conhecimento tácito
5. Validação de requisitos
- Serve para confirmar se os requisitos realmente refletem as necessidades dos stakeholders.
- Também verifica se os requisitos são técnica e economicamente viáveis.
- Pode envolver revisão com usuários e uso de protótipos.
Palavras-chave:
validação, necessidades dos stakeholders, viabilidade técnica, viabilidade econômica, revisão, protótipos
6. Negociação de requisitos
- Nem todos os requisitos podem ser atendidos por limitações de:
- tempo;
- custo;
- tecnologia.
- Por isso, é necessário discutir prioridades e resolver conflitos entre stakeholders.
Palavras-chave:
negociação, prioridades, restrições, custo, tempo, conflitos, alinhamento
7. Modelagem e prototipagem
- São técnicas usadas na elicitação e validação.
- Ajudam a visualizar e testar funcionalidades antes da implementação completa.
Modelagem
- Cria representações abstratas do sistema.
- Exemplos:
- diagrama de fluxo de dados;
- modelo entidade-relacionamento;
- diagrama de caso de uso.
Prototipagem
- Desenvolve uma versão inicial limitada do sistema.
- Pode variar de wireframes e mockups até sistemas parcialmente funcionais.
- Facilita o feedback dos usuários.
Palavras-chave:
modelagem, prototipagem, visualização, wireframe, mockup, caso de uso, feedback
8. Análise de stakeholders
- É o processo de identificar quem pode afetar ou ser afetado pelo projeto.
- Busca entender:
- interesses;
- expectativas;
- influência;
- impacto no projeto.
Etapas principais
- Identificação dos stakeholders;
- Envolvimento de cada parte no momento adequado;
- Análise de necessidades, expectativas e poder de influência.
Palavras-chave:
análise de stakeholders, identificação, envolvimento, influência, impacto, prioridades
9. Elicitação em metodologias ágeis
- Nas metodologias ágeis, a elicitação é um processo contínuo, colaborativo e iterativo.
- Ela acontece ao longo dos ciclos curtos de desenvolvimento, como as sprints.
Elementos citados
- User Stories: descrições curtas das funcionalidades na perspectiva do usuário.
- Backlog Grooming: refinamento e priorização contínua dos requisitos.
- Iterações curtas: permitem ajustes frequentes.
- Feedback contínuo: incorpora mudanças ao longo do projeto.
Palavras-chave:
metodologias ágeis, sprints, user stories, backlog grooming, iteração, feedback contínuo
10. Comunicação na elicitação
- A comunicação eficaz é essencial para alinhar expectativas e entender o projeto profundamente.
- Ajuda a minimizar:
- riscos;
- mal-entendidos;
- conflitos.
Palavras-chave:
comunicação, alinhamento, expectativas, mal-entendidos, colaboração, riscos
11. Habilidades de comunicação importantes
As aulas destacam:
- escuta ativa;
- comunicação não verbal;
- feedback construtivo;
- adaptação de linguagem;
- clareza e concisão;
- uso de ferramentas visuais.
Palavras-chave:
escuta ativa, comunicação não verbal, feedback construtivo, clareza, concisão, linguagem adequada
12. Workshops de requisitos
- São sessões estruturadas com stakeholders para definir e concordar com requisitos.
- Exigem:
- preparação com objetivos claros;
- seleção dos participantes;
- agenda definida;
- facilitação durante a reunião.
Palavras-chave:
workshops de requisitos, sessões estruturadas, facilitação, agenda, participação, consenso
13. Gerenciamento de conflitos
- Conflitos são comuns porque diferentes stakeholders têm visões, necessidades e prioridades diferentes.
- A gestão de conflitos envolve:
- reconhecer o conflito;
- compreender as posições das partes;
- buscar entendimento mútuo.
Palavras-chave:
gerenciamento de conflitos, prioridades diferentes, reconhecimento, compreensão, entendimento mútuo
14. Exemplos práticos das aulas
Evento de treinamento interno
- Foi proposta uma atividade em que um e-mail incompleto exigia levantamento adicional de requisitos.
- O aluno deveria montar questionário, fluxo simples do evento e protótipo de agenda.
Projeto X com conflito entre equipes
- Um exemplo mostrou conflito entre desenvolvimento e marketing:
- desenvolvimento queria mais tempo para funções técnicas avançadas;
- marketing queria lançamento antes da temporada de festas.
- O exercício pedia um plano de ação para reconciliar requisitos conflitantes.
Palavras-chave:
evento, questionário, agenda, fluxo, conflito entre equipes, plano de ação, priorização
15. Ideia central das aulas
As aulas mostram que elicitar requisitos não é só perguntar o que o sistema deve fazer. Também envolve entender pessoas, contexto, prioridades, comunicação, conflitos e mudanças, usando técnicas adequadas para transformar necessidades em requisitos úteis e viáveis.
Palavras-chave:
pessoas, contexto, prioridades, viabilidade, comunicação, colaboração, requisitos úteis
Resumão final
A elicitação de requisitos é a etapa de descobrir, entender e organizar o que o sistema precisa entregar. Para isso, usa técnicas como entrevistas, questionários, workshops, observação, modelagem e prototipagem. Também depende de validação, negociação, análise de stakeholders, comunicação eficiente e gerenciamento de conflitos, especialmente em ambientes ágeis, onde os requisitos evoluem continuamente.
H – Bloco final
1. O que é modelagem de dados relacional
- É a base de quase todos os bancos de dados empresariais.
- Serve para estruturar dados de forma eficiente e alinhada às necessidades de informação da organização.
- Sua função é organizar entidades, atributos, chaves e relacionamentos.
Palavras-chave:
modelagem relacional, banco de dados, estrutura de dados, organização, eficiência
2. Entidades
- Uma entidade representa um objeto ou conceito do mundo real com existência independente.
- Exemplos citados:
- estudante;
- professor;
- curso;
- aluno.
- As entidades são os blocos básicos da modelagem relacional.
Palavras-chave:
entidade, objeto do mundo real, existência independente, bloco básico
3. Atributos
- Atributos são as características que descrevem uma entidade.
- Cada atributo armazena um tipo específico de dado, como:
- texto;
- número;
- data;
- binário.
- Exemplo:
- Estudante: nome, ID, curso, data de nascimento;
- Curso: nome do curso, código, departamento, créditos.
Palavras-chave:
atributos, propriedades, características, dados, nome, ID, data
4. Relação entre entidades e atributos
- A entidade é o objeto principal.
- Os atributos são os dados que descrevem esse objeto.
- Em outras palavras, entidades representam coisas; atributos representam informações sobre essas coisas.
Palavras-chave:
entidade e atributo, descrição, representação, informação
5. Chave primária
- A chave primária identifica de forma única cada registro de uma tabela.
- Pode ser formada por um atributo ou conjunto de atributos.
- Deve ser:
- única;
- obrigatória;
- exclusiva para cada entidade.
- Exemplo: ID do estudante.
Palavras-chave:
chave primária, identificação única, registro, unicidade, obrigatoriedade
6. Chave estrangeira
- A chave estrangeira é um atributo em uma tabela que referencia a chave primária de outra tabela.
- Ela cria a ligação entre tabelas e viabiliza os relacionamentos.
- Exemplo: na tabela Estudante, o campo ID do Curso pode ser chave estrangeira.
Palavras-chave:
chave estrangeira, referência, ligação entre tabelas, relacionamento
7. Normalização de dados
- É o processo de organizar dados em tabelas e relações para:
- minimizar redundância;
- reduzir dependências indevidas;
- melhorar a estrutura do banco.
- É realizada em etapas chamadas formas normais (1NF, 2NF, 3NF etc.).
Palavras-chave:
normalização, redundância, dependência, formas normais, organização
8. Objetivo da normalização
- Evitar duplicidade de dados.
- Reduzir inconsistências.
- Tornar as relações entre tabelas mais eficientes.
Palavras-chave:
duplicidade, inconsistência, eficiência, estrutura relacional
9. Tipos de relacionamentos
No modelo entidade-relacionamento, os relacionamentos são classificados em três tipos principais.
a) Um-para-Um (1:1)
- Uma entidade se relaciona com, no máximo, uma entidade da outra tabela.
- Exemplo: Pessoa e Passaporte.
Palavras-chave:
um-para-um, 1:1, pessoa, passaporte
b) Um-para-Muitos (1:N)
- Uma entidade pode estar associada a várias entidades da outra tabela.
- Exemplo: Professor e Curso. Um professor pode ministrar vários cursos, mas cada curso tem apenas um professor.
Palavras-chave:
um-para-muitos, 1:N, professor, curso
c) Muitos-para-Muitos (N:N)
- Uma entidade pode se relacionar com várias da outra tabela, e vice-versa.
- Exemplo: Alunos e Cursos.
Palavras-chave:
muitos-para-muitos, N:N, alunos, cursos
10. Tabela de associação
- Em relacionamentos muitos-para-muitos, normalmente é necessária uma tabela de associação.
- Exemplo:
- Matrículas ligando Aluno e Curso.
- Essa tabela contém:
- chaves estrangeiras das duas entidades;
- atributos próprios da relação.
Palavras-chave:
tabela de associação, matrículas, relacionamento N:N, chaves estrangeiras
11. Atributos da associação
- A tabela de associação também pode guardar informações da própria relação.
- Exemplo de atributos:
- DataDeMatricula;
- NotaFinal.
- Isso permite registrar dados específicos do vínculo entre as entidades.
Palavras-chave:
atributos da associação, data de matrícula, nota final, vínculo
12. Integridade referencial
- Garante a consistência e validade dos relacionamentos entre tabelas.
- Se uma tabela A possui chave estrangeira apontando para tabela B, então o valor dessa chave deve existir como chave primária em B.
- Isso evita registros órfãos.
Palavras-chave:
integridade referencial, consistência, validade, registro órfão, relacionamento
13. Cascade delete e cascade update
- Alterações ou exclusões em uma tabela relacionada devem considerar as dependências entre tabelas.
- Restrições como:
- cascade delete;
- cascade update
ajudam a manter a integridade dos dados.
Palavras-chave:
cascade delete, cascade update, integridade, dependência entre tabelas
14. MER e DER
- O conteúdo trabalha com o Modelo Entidade-Relacionamento (MER) e sua representação em diagramas.
- O MER é usado para representar:
- entidades;
- atributos;
- relacionamentos;
- associações.
Palavras-chave:
MER, DER, diagrama entidade-relacionamento, representação gráfica
15. Desnormalização
- É o processo inverso da normalização.
- Reintroduz deliberadamente redundância para melhorar o desempenho das leituras.
- Pode ser útil quando:
- há muitas junções complexas;
- o sistema faz mais leitura que escrita;
- os dados mudam pouco.
Palavras-chave:
desnormalização, redundância controlada, desempenho, leitura, junções
16. Como aplicar desnormalização
- Combinar tabelas frequentemente usadas juntas.
- Adicionar colunas redundantes para acesso rápido.
- Pré-agregar dados, como:
- somas;
- médias;
- totais para dashboards e relatórios.
Palavras-chave:
pré-agregação, consolidação, coluna redundante, dashboard, relatórios
17. Indexação e performance
- Índices são estruturas criadas para acelerar a busca de registros.
- Funcionam como um “sumário” dos dados.
- São úteis principalmente em colunas usadas em:
- WHERE;
- JOIN;
- ORDER BY;
- GROUP BY.
Palavras-chave:
índices, performance, velocidade, busca, WHERE, JOIN, ORDER BY, GROUP BY
18. Cuidados com indexação
- Índices demais podem prejudicar:
- inserções;
- atualizações;
- exclusões.
- Isso acontece porque os índices também precisam ser atualizados.
Palavras-chave:
indexação excessiva, inserção, atualização, exclusão, custo de manutenção
19. Modelagem para Big Data
- Big Data exige adaptação da modelagem tradicional por causa de:
- grande volume;
- alta velocidade;
- maior complexidade dos dados.
- Em muitos casos, são usados bancos NoSQL, como:
Palavras-chave:
Big Data, NoSQL, MongoDB, Cassandra, escalabilidade, esquemas flexíveis
20. Escalabilidade
- A modelagem para Big Data deve considerar crescimento horizontal e distribuição dos dados em vários servidores desde o início.
Palavras-chave:
escalabilidade, crescimento horizontal, distribuição de dados, servidores
21. Ideia central das aulas
As aulas mostram que a modelagem relacional começa com entidades, atributos, chaves e relacionamentos, passa pela normalização e integridade referencial, e depois evolui para preocupações mais avançadas, como desempenho, indexação, desnormalização e adaptação para Big Data.
Palavras-chave:
entidades, atributos, relacionamentos, normalização, integridade, performance, escalabilidade
Resumão final
A modelagem de dados relacional organiza informações em entidades, atributos e relacionamentos, usando chaves primárias e estrangeiras para ligar tabelas e garantir integridade referencial. Os relacionamentos podem ser 1:1, 1:N e N:N, sendo que o último normalmente exige tabela de associação. Além disso, o banco pode ser otimizado com normalização, desnormalização, índices e adaptações para Big Data, sempre buscando equilíbrio entre consistência, desempenho e escalabilidade.
Jargões e extrangeirismos
1. Termos de requisitos e trabalho em equipe
- Stakeholders: partes interessadas no projeto, como clientes, usuários, equipe e gestores.
- Workshop: sessão estruturada de trabalho em grupo para discutir e definir requisitos.
- Brainstorming: técnica de geração rápida de ideias para levantar possibilidades, problemas ou requisitos.
- Feedback: retorno, opinião ou resposta dada sobre uma ideia, requisito ou protótipo.
Palavras-chave: stakeholders, workshop, brainstorming, feedback
2. Termos ágeis
- Sprint: ciclo curto de desenvolvimento em metodologias ágeis.
- User Stories: histórias de usuário; descrições curtas de funcionalidades do ponto de vista do usuário.
- Backlog: lista priorizada de tarefas, requisitos e funcionalidades do projeto.
- Backlog Grooming: refinamento contínuo do backlog, para revisar, esclarecer e priorizar itens.
- Frameworks: estruturas ou conjuntos de ferramentas/práticas que apoiam o desenvolvimento.
Palavras-chave: sprint, user stories, backlog, backlog grooming, frameworks
3. Termos de prototipagem e interface
- Wireframe: esboço simples da tela, mostrando estrutura e organização visual sem preocupação com acabamento.
- Mockup: modelo visual mais detalhado da interface, mais próximo da aparência final.
- UI (User Interface): interface do usuário, ou seja, a parte visual e interativa do sistema.
- UI/UX: interface do usuário e experiência do usuário. Nos PDFs, aparece ligada a decisões visuais e de uso.
- Checkout: etapa final de compra em um e-commerce, quando o usuário fecha o pedido/pagamento.
Palavras-chave: wireframe, mockup, UI, UX, checkout
4. Termos de modelagem e UML
- UML (Unified Modeling Language): linguagem padrão de modelagem usada para visualizar e documentar sistemas.
- OMT (Object-Modeling Technique): método de modelagem orientada a objetos citado na origem da UML.
- OOSE (Object-Oriented Software Engineering): outra abordagem orientada a objetos que ajudou a formar a UML.
- Design: projeto ou concepção da estrutura do software ou dos dados.
- Links: no contexto de UML, ligações entre elementos/objetos.
Palavras-chave: UML, OMT, OOSE, design, links
5. Termos de banco de dados e dados
- SQL: linguagem usada para consultar e manipular bancos de dados relacionais; aparece associada aos SGBDs.
- NoSQL: grupo de bancos de dados com estrutura menos rígida que a relacional.
- NewSQL: modelo que mistura características relacionais com escalabilidade típica de sistemas mais modernos.
- ACID: conjunto de propriedades de confiabilidade em transações de banco de dados.
- Data warehouse: repositório centralizado para armazenamento e análise de dados.
- Data lake: armazenamento de grande volume de dados brutos e estruturados em um local central.
- Dashboard: painel visual com indicadores, gráficos e resumos de dados.
- Big Data: grande volume de dados, com alta complexidade e necessidade de processamento escalável.
- Analytics: análise de dados para gerar padrões, insights e apoio à decisão.
- DaaS (Data as a Service): dados oferecidos como serviço, geralmente por nuvem e sob demanda.
- IoT (Internet of Things): internet das coisas; dispositivos conectados gerando e trocando dados.
- Blockchain: tecnologia de registro distribuído e imutável usada para garantir integridade de transações/dados.
- Compliance / conformidade: aderência a normas, leis e regulamentos sobre dados. Nos PDFs, aparece junto de privacidade e LGPD.
Palavras-chave: SQL, NoSQL, NewSQL, ACID, data warehouse, data lake, dashboard, Big Data, analytics, DaaS, IoT, blockchain, compliance
6. Termos de testes de software
- Selenium: ferramenta de automação de testes de interface em navegadores web.
- JUnit: framework usado principalmente para testes unitários em aplicações Java.
- JMeter: ferramenta voltada mais para testes de carga e desempenho.
- LoadRunner: ferramenta de teste de desempenho e carga.
- QTP e TestComplete: ferramentas citadas para automação de testes.
- JIRA e TestRail: ferramentas para gestão e rastreamento de testes.
- Jenkins e Travis CI: ferramentas de integração contínua usadas para executar testes automaticamente no processo de desenvolvimento.
- CI/CD: integração contínua e entrega/implantação contínua. Os PDFs citam CI e CD como tecnologias usadas em desenvolvimento ágil.
- Slack: ferramenta de comunicação usada no exemplo de reportar riscos.
Palavras-chave: Selenium, JUnit, JMeter, LoadRunner, QTP, TestComplete, JIRA, TestRail, Jenkins, Travis CI, CI/CD, Slack
7. Termos de POO e padrões de projeto
- Singleton: padrão de projeto para garantir uma única instância de uma classe.
- Factory: padrão para centralizar/criar objetos de forma flexível.
- Builder: padrão usado para construir objetos complexos em etapas.
- Adapter: padrão que adapta uma interface para outra.
- Decorator: padrão que adiciona responsabilidades/comportamentos a objetos.
- Composite: padrão para tratar objetos individuais e compostos de forma uniforme.
- Observer: padrão em que um objeto observa mudanças em outro.
- Strategy: padrão para trocar algoritmos/comportamentos sem alterar o restante do código.
- Command: padrão que encapsula uma ação/comando em um objeto.
- SOLID: conjunto de princípios de design orientado a objetos para tornar o software mais organizado e manutenível.
Palavras-chave: Singleton, Factory, Builder, Adapter, Decorator, Composite, Observer, Strategy, Command, SOLID
8. Jargões técnicos em português que aparecem junto
Além das palavras estrangeiras, os PDFs usam bastante jargão técnico em português, como integridade referencial, normalização, desnormalização, escalabilidade, prototipagem, caso de uso, teste de regressão, confiabilidade e usabilidade. Esses termos não são estrangeiros, mas são linguagem técnica própria da área.
Resumão final
Os PDFs misturam bastante inglês técnico da área de TI com jargão profissional em português. Os grupos que mais aparecem são: ágil (sprint, backlog, feedback), requisitos (stakeholders, workshop, brainstorming), interface/protótipo (wireframe, mockup, UI/UX), dados (SQL, NoSQL, Big Data, dashboard) e testes/automação (Selenium, Jenkins, CI/CD).