Simulador de eventos físicos
Simulador de eventos físicos:
Site de documentação da Maurinsoft
Site de documentação da Maurinsoft

Descreve Equação de Newton tratando da Força.
Formula 1
Força = m * a
Formula 2
N- P = m * a
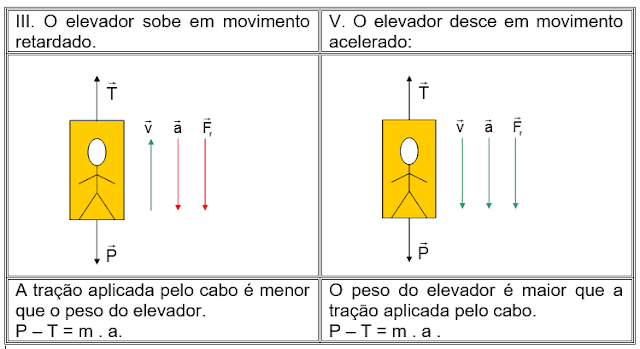
Tipo de movimento em função da aceleração do elevador
Movimento de Queda Livre É quando não há aceleração de N, apenas a aceleração da gravidade.
P-N= m * a , onde N = 0;
Exercício
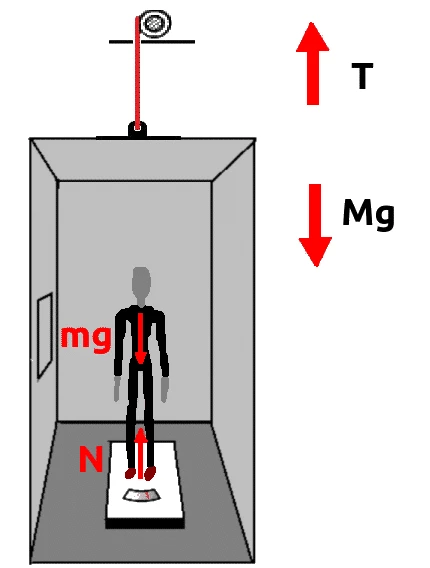
Dado: g = 10 m/s
P = 95kg * 10 m/s
a = 0,5m/s
N-P = m * a
N -950 = 95 * 0,5
N – 950 = 95 * (1/2)
N = (95/2) + 950 -> N = 47,5 + 950 -> N= 997,5N
P/N = 950 /997,5 = 0,95 ou 95% da força normal.
2) Determine o peso aparente de uma pessoa de massa igual a 50 Kg que está em um elevador que desce com aceleração igual a 1m/s^2 . Dado g = 10 m/s^2
M = 50kg
a = 1m/s^2
g = 10m/s^2
P = m.a -> P. 50 * (10-1)
P = 50 * 9
P=450N
3) Um corpo de massa 2,0Kg está pendurado em um dinamômetro preso ao teto de um elevador. Uma pessoa no interior deste elevador observa que a indicação fornecida pelo dinamômetro é 26N. Considerando a aceleração local da gravidade de 10m/s^2 , qual o movimento do elevador ?]
M = 2Kg
F = 26N
F= m * a => 25 = 2 * a -> a = 25/2 ->a = 12,5 m/s^2
Com base no movimento, podemos deduzir, que é um movimento desce acelerado.


Transformers é uma biblioteca de IA muito utilizada para predição de texto.
Iremos apresentar não a parte teórica, porem a instalação e um exemplo prático.
Antes de tudo, quero apresentar, que sou estudante sobre transformers, e ainda há muito a ser aprendido.
Para instalação use o seguinte comando:
pip install transformers torchO procedimento realizado é super rápido e segue conforme o exemplo:

Neste segundo artigo irei utilizar os grafos para realizar uma pesquisa.
Para isso usarei partes do projeto já criado.
Se você não viu o primeiro artigo, recomendo que veja ele primeiro:
Este segundo artigo é mais prático, então vamos a mão na massa!
Criando conexão:
import mysql.connector
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words('portuguese'))
# Configuração da conexão com o banco
DB_CONFIG = {
"host": "localhost",
"user": "username",
"password": "password",
"database": "graph_db"
}
"""Cria arestas com base em frases de exemplo."""
frases = [
"Comece a gravação de áudio",
"Salve esse texto importante",
"Defina um alerta para amanhã",
"Quero a gravação dessa reunião",
"Salve a anotação rapidamente"
]
comandos = [
"Iniciar gravação",
"Salvar texto",
"Configurar alerta",
"Iniciar gravação",
"Salvar anotação"
]
#Treinamento e teste
matriz = [
["Comece a gravar agora", "Iniciar gravação"],
["Inicie a gravação do áudio", "Iniciar gravação"],
["Por favor, ative a gravação", "Iniciar gravação"],
["Vamos começar a gravação", "Iniciar gravação"],
["Quero que comece a gravar", "Iniciar gravação"],
["Dê início à gravação", "Iniciar gravação"],
["Preciso gravar isso", "Iniciar gravação"],
["Vamos gravar essa conversa", "Iniciar gravação"],
["Inicie a captação do áudio", "Iniciar gravação"],
["Gostaria de gravar este momento", "Iniciar gravação"],
["Por gentileza, inicie a gravação", "Iniciar gravação"],
["Capture esse áudio", "Iniciar gravação"],
["Quero guardar esse som", "Iniciar gravação"],
["Vamos documentar esse áudio", "Iniciar gravação"],
["Grave essa sessão", "Iniciar gravação"],
["Desejo registrar esse som", "Iniciar gravação"],
["Vamos dar start na gravação", "Iniciar gravação"],
["Por favor, comece a gravar", "Iniciar gravação"],
["Gostaria de iniciar a gravação", "Iniciar gravação"],
["Desejo capturar este áudio", "Iniciar gravação"],
["Preserve este texto", "Salvar texto"],
["Quero guardar essa informação", "Salvar texto"],
["Salve estas palavras", "Salvar texto"],
["Documente este conteúdo", "Salvar texto"],
["Registre esta informação", "Salvar texto"],
["Gostaria de salvar este documento", "Salvar texto"],
["Por favor, salve esse texto", "Salvar texto"],
["Desejo guardar este conteúdo", "Salvar texto"],
["Capture esta informação em texto", "Salvar texto"],
["Guarde essa anotação", "Salvar texto"],
["Defina um alarme para 9h", "Configurar alerta"],
["Quero ser alertado às 10h", "Configurar alerta"],
["Lembre-me de algo às 11h", "Configurar alerta"],
["Ative um lembrete para o meio-dia", "Configurar alerta"],
["Preciso de um alerta para as 13h", "Configurar alerta"],
["Por favor, configure um alerta para 14h", "Configurar alerta"],
["Quero ser notificado às 15h", "Configurar alerta"],
["Defina um lembrete para 16h", "Configurar alerta"],
["Lembre-me disso às 17h", "Configurar alerta"],
["Configure um alerta para 18h", "Configurar alerta"],
["Faça uma nota disto", "Salvar anotação"],
["Quero que isso fique registrado", "Salvar anotação"],
["Documente esta observação", "Salvar anotação"],
["Anote isto, por favor", "Salvar anotação"],
["Preserve esta anotação", "Salvar anotação"],
["Por favor, faça uma nota sobre isso", "Salvar anotação"],
["Desejo que isso seja anotado", "Salvar anotação"],
["Guarde este registro", "Salvar anotação"],
["Capture esta nota", "Salvar anotação"],
["Quero esta informação documentada", "Salvar anotação"],
]Agora criamos a função de conexão com banco de dados:
def connect_to_database():
"""Retorna uma conexão com o banco de dados."""
return mysql.connector.connect(**DB_CONFIG)Eu pedi ao chatGPT criar a matriz estática contendo variações de solicitações de comando.
Desta forma poderia apresentar o texto e testar os resultados.
Lembrando que como uso grafos duplamente ligados, a qualidade dos resultados depende muito do treinamento.
matriz_teste = [
["Dê início à captura de som", "Iniciar gravação"],
["Gostaria de ouvir isso depois", "Iniciar gravação"],
["Por gentileza, registre este momento", "Iniciar gravação"],
["Ative o modo gravação", "Iniciar gravação"],
["Preserve este áudio para mim", "Iniciar gravação"],
["Assegure que este texto esteja seguro", "Salvar texto"],
["Faça uma cópia deste conteúdo", "Salvar texto"],
["Deixe este texto registrado", "Salvar texto"],
["Fixe esta informação", "Salvar texto"],
["Quero ter este texto para depois", "Salvar texto"],
["Estabeleça um aviso para 19h", "Configurar alerta"],
["Preciso ser lembrado às 20h", "Configurar alerta"],
["Por favor, defina um bip para 21h", "Configurar alerta"],
["Quero um aviso sonoro para as 22h", "Configurar alerta"],
["Faça um lembrete vibrar às 23h", "Configurar alerta"],
["Gostaria de ter isso em minhas notas", "Salvar anotação"],
["Anote isto para mim", "Salvar anotação"],
["Mantenha esta informação como uma nota", "Salvar anotação"],
["Quero isto em formato de anotação", "Salvar anotação"],
["Por favor, transforme isso em uma nota", "Salvar anotação"]
]
No artigo anterior, criamos apenas algumas frases para popular nossa base.
Iremos modificar um pouco nosso programa
Nas palavras vamos incluir a opção de cadastro, porem se já existir ja passamos o ID:
# Função para cadastrar palavras
def CadastraWords(word_name):
connection = connect_to_database()
cursor = connection.cursor()
# Verifica se a palavra já está cadastrada
cursor.execute("SELECT word_id FROM words WHERE word_name = %s", (word_name,))
result = cursor.fetchone()
if result:
return result[0]
cursor.execute("INSERT INTO words (word_name) VALUES (%s)", (word_name,))
connection.commit()
word_id = cursor.lastrowid
cursor.close()
connection.close()
return word_idJá na opção de arestas, iremos usar o CadastraWords, conforme apresentado a seguir:
def CriaArestas(Word1, Word2, Cmd):
print(Word1)
print(Word2)
"""Cria uma aresta associando Word1 e Word2 ao comando Cmd."""
#word1_id = get_id_words(Word1, "word_name")
#word2_id = get_id_words(Word2, "word_name")
word1_id = CadastraWords(Word1)
word2_id = CadastraWords(Word2)
cmd_id = get_id_commands(Cmd, "command_name")
print(word1_id);
print(word2_id);
print(cmd_id);
if not word1_id or not word2_id or not cmd_id:
print("Erro: Um ou mais valores não foram encontrados no banco de dados.")
return
connection = connect_to_database()
cursor = connection.cursor()
insert_query = """
INSERT INTO edges (word_id1, word_id2, command_id)
VALUES (%s, %s, %s)
"""
try:
cursor.execute(insert_query, (word1_id, word2_id, cmd_id))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir aresta: {err}")
cursor.close()
connection.close()Por fim iremos incluir nos grafos os itens do treinamento:
Nela criamos e povoamos os 200 testes.
# Função para popular com dados de teste
def Popula_Teste():
stop_words = set(stopwords.words('portuguese'))
for item in matriz_teste:
frase, comando = item
words = word_tokenize(frase, language="portuguese")
filtered_words = [w for w in words if w.lower() not in stop_words and w.isalpha()]
for i in range(len(filtered_words) - 1):
CriaArestas(filtered_words[i], filtered_words[i + 1], comando)
Agora iremos chamar a função e testar:
Popula_Teste()Agora iremos utilizar nossa matriz de teste (matriz_teste) para aferir quais os resultados que ele acha. Lembrando que para realizar tal façanha usamos novos códigos.
Nesta primeira função testamos o resultado, individualmente.
def Teste_Validacao(Frase, comando):
stop_words = set(stopwords.words('portuguese'))
connection = connect_to_database()
cursor = connection.cursor()
# Tokenize e limpe a frase
words = word_tokenize(Frase, language="portuguese")
filtered_words = [w.lower() for w in words if w.lower() not in stop_words and w.isalpha()]
# Obtenha o ID do comando
cursor.execute("SELECT command_id FROM commands WHERE command_name = %s", (comando,))
command_id = cursor.fetchone()
if not command_id:
return "Comando não encontrado."
command_id = command_id[0]
# Verifique a presença de pares de palavras na tabela edges
total_matches = 0
for i in range(len(filtered_words) - 1):
cursor.execute("""SELECT COUNT(*) FROM edges
WHERE word_id1 = (SELECT word_id FROM words WHERE word_name = %s)
AND word_id2 = (SELECT word_id FROM words WHERE word_name = %s)
AND command_id = %s""", (filtered_words[i], filtered_words[i + 1], command_id))
total_matches += cursor.fetchone()[0]
# Matriz de confusão: [Predicted True, Predicted False; Actual True, Actual False]
confusion_matrix = [[0, 0], [0, 0]]
if total_matches > 0: # Se houver combinações, assuma que a previsão é verdadeira
confusion_matrix[0][0] = 1
else: # Se não houver combinações, assuma que a previsão é falsa
confusion_matrix[1][1] = 1
cursor.close()
connection.close()
return confusion_matrixNeste segundo, usamos a matriz para criar uma matriz de confusão:
def plot_confusion_matrix(confusion_matrix, classes, title='Matriz de Confusão', cmap=plt.cm.Blues):
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix, annot=True, cmap=cmap, fmt='g', xticklabels=classes, yticklabels=classes)
plt.ylabel('Comando verdadeiro')
plt.xlabel('Comando previsto')
plt.title(title)
plt.show()
def Testa_Validacao():
conn = connect_to_database()
cursor = conn.cursor()
# Lista de stopwords em português
stop_words = set(stopwords.words('portuguese'))
confusion_matrix = np.zeros((len(comandos), len(comandos)))
for item in matriz_teste:
frase, comando_verdadeiro = item
# Processa a frase: remove stopwords, converte para minúsculo
palavras = [word for word in frase.lower().split() if word not in stop_words and not word.isdigit()]
# Encontre os IDs das palavras
word_ids = []
for palavra in palavras:
cursor.execute("SELECT word_id FROM words WHERE word_name = %s", (palavra,))
result = cursor.fetchone()
if result:
word_ids.append(result[0])
# Encontre a aresta com maior frequência baseada nas palavras
comando_previsto = None
max_count = -1
for i in range(len(word_ids)-1):
cursor.execute("""
SELECT command_id, COUNT(*) as freq
FROM edges
WHERE word_id1 = %s AND word_id2 = %s
GROUP BY command_id
ORDER BY freq DESC
LIMIT 1
""", (word_ids[i], word_ids[i+1]))
result = cursor.fetchone()
if result and result[1] > max_count:
comando_previsto = result[0]
max_count = result[1]
if comando_previsto:
# Converte o ID do comando para nome
cursor.execute("SELECT command_name FROM commands WHERE command_id = %s", (comando_previsto,))
result = cursor.fetchone()
if result:
comando_previsto_name = result[0]
confusion_matrix[comandos.index(comando_verdadeiro)][comandos.index(comando_previsto_name)] += 1
conn.close()
# Plota a matriz de confusão
plt.figure(figsize=(10,7))
sns.heatmap(confusion_matrix, annot=True, cmap="YlGnBu", xticklabels=comandos, yticklabels=comandos)
plt.xlabel('Comando Previsto')
plt.ylabel('Comando Verdadeiro')
plt.show()Por fim, chamamos os dados de Testa_Validacao.
Testa_Validacao()
Gerando uma matriz conforme apresentado:
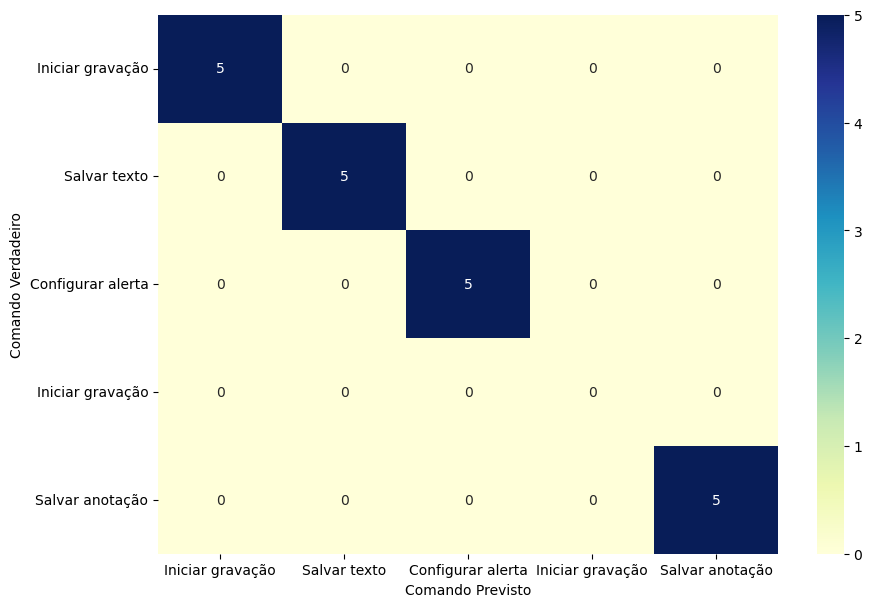
Perceba que a linha diagonal, é o que realmente desejamos. Perceba que houve intencionalmente uma duplicação do iniciar gravação, e que a segunda vez que ele apareceu, os dados não foram mostrados.
A apresentação deste problema pode ocorrer, em especial quando existir muitos grafos e muitos comandos, e seu tratamento será necessário pelo algoritmo que o propuser.
Por fim, para os amantes do fonte de graça, segue a referencia do GITHUB:

Parte do material deste tutorial veio do CHATGPT4.
grafo = {
"A": ["B", "C"],
"B": ["A", "D", "E"],
"C": ["A", "F"],
"D": ["B"],
"E": ["B", "F"],
"F": ["C", "E"]
}
Essa síntese destaca os marcos e conceitos mais relevantes na evolução da teoria dos grafos.
Os grafos são relações entre partes, e podemos entender seus elementos como se segue:
A implementação de um grafo pode ser feita de várias formas, pois é um conceito.
Porem as formas mais comuns são descritos a seguir:
É uma lista onde, para cada vértice do grafo, armazenamos uma lista de seus vértices adjacentes. É uma forma eficiente de armazenar grafos esparso.
Exemplo em python:
A matriz de adjacência é uma das formas mais comuns de representar um grafo em termos de estrutura de dados. Ela utiliza uma matriz bidimensional (um array de arrays) para expressar as relações entre os vértices de um grafo.
Vantagens:
Desvantagens:
Para o grafo com vértices A,B,C e arestas (A,B),(B,C):
A matriz de adjacência (não ponderada) seria:
A B C
A [0, 1, 0]
B [1, 0, 1]
C [0, 1, 0]Se este fosse um grafo ponderado, onde a aresta (A,B) tem peso 3 e (B,C) tem peso 2, a matriz seria:
A B C
A [0, 3, 0]
B [3, 0, 2]
C [0, 2, 0]
Apresentaremos um problema de Rota, onde teremos apenas 5 pontes para ir do ponto A ao ponto C.
Nele apresentaremos uma proposta descritiva e depois uma proposta em Python.
Vamos ao grafo dado:
Vértices:A,B,C,D,E Ligações: A−B,B−E,E−C,D−A,B−C
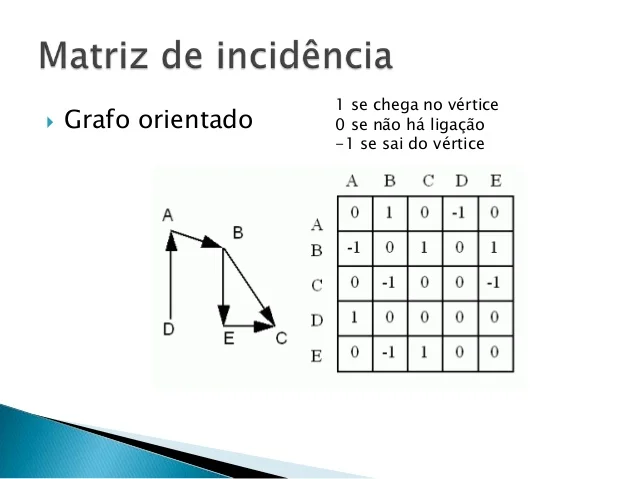
A matriz de adjacência é uma matriz n×n onde n é o número de vértices. A entrada M(i,j) será 1 se o vértice i estiver ligado ao vértice j e 0 caso contrário.
Uma maneira simples de fazer isso é usando uma busca em largura (BFS). Vamos criar um exemplo em Python para isso:
import heapq
def heuristic(node, goal):
# Como um grafo não possui coordenadas espaciais, podemos usar uma heurística trivial.
return 0
def a_star(graph, start, goal):
open_list = [(0, start)]
g_costs = {node: float('inf') for node in range(len(graph))}
g_costs[start] = 0
came_from = {}
while open_list:
current_cost, current_node = heapq.heappop(open_list)
if current_node == goal:
path = []
while current_node in came_from:
path.insert(0, current_node)
current_node = came_from[current_node]
path.insert(0, start)
return path
for neighbor, cost in enumerate(graph[current_node]):
if cost == 1: # Existe uma aresta
tentative_g_cost = g_costs[current_node] + 1
if tentative_g_cost < g_costs[neighbor]:
came_from[neighbor] = current_node
g_costs[neighbor] = tentative_g_cost
f_cost = tentative_g_cost + heuristic(neighbor, goal)
heapq.heappush(open_list, (f_cost, neighbor))
return None
graph = [
[0, 1, 0, 1, 0], # A
[1, 0, 1, 0, 1], # B
[0, 1, 0, 0, 1], # C
[1, 0, 0, 0, 0], # D
[0, 1, 1, 0, 0] # E
]
path = a_star(graph, 0, 2)
if path:
print(" -> ".join(chr(65 + node) for node in path))
else:
print("Não foi encontrado um caminho de A para C.")Resultado:
A -> B -> C
Outros usos de Grafo:
Agora teremos como objetivo desenvolver um NLP que irá analisar de comandos dados de forma textual, utilizando grafos como base de tomada de decisão.
Para isso temos duas tabelas:
Palavras: Contem uma lista de palavras usadas nos textos.
Comandos: Contem uma lista de comandos possíveis.
Usaremos como exemplo de vértice apenas quando duas palavras em sequencia estiverem atendidas em determinado grafo, ai ligaremos estes aos comandos.
Esta tabela contém uma lista de palavras chave que podem ser usadas para determinar ações.
| Palavras |
|---|
| Grave |
| Diário |
| Reproduza |
| Música |
| Ligue |
| Luz |
Esta tabela associa sequências de palavras a ações específicas.
| Sequência de Palavras | Ação |
|---|---|
| Grave Diário | Gravação de entradas no diário |
| Reproduza Música | Tocar música |
| Ligue Luz | Acender a luz |
Neste caso, o grafo seria algo assim:
A ideia aqui é que, se alguém dissesse “Grave meu Diário”, o sistema reconheceria a sequência “Grave Diário” e acionaria a função correspondente de “Gravação de entradas no diário”. As stop words, como “meu”, seriam ignoradas pelo sistema.
Para implementar isso, você poderia criar um dicionário em Python que mapeia sequências de palavras (arestas) a ações, e então usar esse dicionário para determinar a ação apropriada com base na entrada do usuário.
Certifique-se de que você tem o MySQL instalado e em execução. Depois, você pode instalar o conector MySQL para Python:
pip install mysql-connector-python
pip install nltk
Crie um novo banco de dados chamado graph_db e um usuário para esse banco de dados. Você pode fazer isso usando a interface de linha de comando do MySQL ou um cliente GUI como o MySQL Workbench.
Aqui está uma sugestão de estrutura:
words: Guarda os vértices do tipo palavra.commands: Guarda os vértices do tipo comando.edges: Guarda as arestas, referenciando palavras e comandos.CREATE DATABASE graph_db;
USE graph_db;
-- Tabela de palavras
CREATE TABLE words (
word_id INT AUTO_INCREMENT PRIMARY KEY,
word_name VARCHAR(50) UNIQUE NOT NULL
);
-- Tabela de comandos
CREATE TABLE commands (
command_id INT AUTO_INCREMENT PRIMARY KEY,
command_name VARCHAR(50) UNIQUE NOT NULL
);
-- Tabela de arestas
CREATE TABLE edges (
edge_id INT AUTO_INCREMENT PRIMARY KEY,
word_id1 INT,
word_id2 INT,
command_id INT,
FOREIGN KEY (word_id1) REFERENCES words(word_id),
FOREIGN KEY (word_id2) REFERENCES words(word_id),
FOREIGN KEY (command_id) REFERENCES commands(command_id)
);
Nesta estrutura:
words tem um ID único para cada palavra e um nome que é exclusivo.commands tem um ID único para cada comando e um nome que é exclusivo.edges tem um ID único para cada aresta. As colunas word_id e command_id são chaves estrangeiras que apontam para os IDs nas tabelas words e commands, respectivamente.Com essa estrutura, a tabela edges representa as relações entre palavras e comandos. Isso significa que cada entrada (linha) na tabela edges é uma relação entre uma palavra específica na tabela words e um comando específico na tabela commands.
Configurando aplicação e Banco de dados
Iremos primeiramente criar as ferramentas basicas para cadastrar as informações e o ambiente.
Então temos a conexão com o banco de dados.
import mysql.connector
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words('portuguese'))
# Configuração da conexão com o banco
DB_CONFIG = {
"host": "localhost",
"user": "your_username",
"password": "your_password",
"database": "graph_db"
}
"""Cria arestas com base em frases de exemplo."""
frases = [
"Comece a gravação de áudio",
"Salve esse texto importante",
"Defina um alerta para amanhã",
"Quero a gravação dessa reunião",
"Salve a anotação rapidamente"
]
comandos = [
"Iniciar gravação",
"Salvar texto",
"Configurar alerta",
"Iniciar gravação",
"Salvar anotação"
]
Criaremos a função de criar a conexão:
def connect_to_database():
"""Retorna uma conexão com o banco de dados."""
return mysql.connector.connect(**DB_CONFIG)Criamos agora a função de pegar o ID:
def get_id(name, table):
"""Busca o ID de um item pelo nome, na tabela especificada."""
connection = connect_to_database()
cursor = connection.cursor()
column = "word_name" if table == "words" else "command_name"
query = f"SELECT * FROM {table} WHERE {column}=%s"
cursor.execute(query, (name,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else NoneAgora criamos a função que popula as arestas:
def populaArestas(word1, word2, command):
"""Popula a tabela edges com as relações entre palavras e comando."""
connection = connect_to_database()
cursor = connection.cursor()
word1_id = get_id(word1, 'words')
word2_id = get_id(word2, 'words')
command_id = get_id(command, 'commands')
if not word1_id or not word2_id or not command_id:
print(f"Erro: Palavras ou comando não encontrados: '{word1}', '{word2}', '{command}'")
return
insert_query = "INSERT INTO edges (word_id, command_id) VALUES (%s, %s)"
# Inserindo relação da primeira palavra com o comando
cursor.execute(insert_query, (word1_id, command_id))
# Inserindo relação da segunda palavra com o comando
cursor.execute(insert_query, (word2_id, command_id))
connection.commit()
cursor.close()
connection.close()Agora iremos criar os nossos comandos, para isso temos duas funções:
def cadastreCMD(command_name):
"""Cadastra um novo comando na tabela commands."""
connection = connect_to_database()
cursor = connection.cursor()
insert_query = "INSERT INTO commands (command_name) VALUES (%s)"
try:
cursor.execute(insert_query, (command_name,))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir comando '{command_name}': {err}")
cursor.close()
connection.close()
def ExemploCMD():
for cmd in comandos:
cadastreCMD(cmd)Agora iremos cadastrar nossas palavras, para isso iremos usar o exemplo a seguir:
Serão implementadas da seguinte forma:
def CadastraWords(word_name):
"""Cadastra uma nova palavra na tabela words."""
connection = connect_to_database()
cursor = connection.cursor()
insert_query = "INSERT INTO words (word_name) VALUES (%s)"
try:
cursor.execute(insert_query, (word_name,))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir palavra '{word_name}': {err}")
cursor.close()
connection.close()
def ExemploWords():
for frase in frases:
palavras = frase.split() # Separa a frase em palavras individuais
for palavra in palavras:
# Ignoramos palavras muito comuns (stop words) e números
if palavra.lower() not in stop_words and not palavra.isnumeric():
CadastraWords(palavra)Agora iremos criar a função:
get_id_from_Table – Retorna o ID de uma dado valor de uma dada tabela para uma dada coluna.
CriaArestas – Cria a tabela de relacionamento (grafo) de Palavras.
def get_id_words(value, column_name):
"""Retorna o ID associado a um valor em uma coluna e tabela específicos."""
connection = connect_to_database()
cursor = connection.cursor()
select_query = f"SELECT word_id FROM words WHERE {column_name} = %s"
cursor.execute(select_query, (value,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
def get_id_commands(value, column_name):
"""Retorna o ID associado a um valor em uma coluna e tabela específicos."""
connection = connect_to_database()
cursor = connection.cursor()
select_query = f"SELECT command_id FROM commands WHERE {column_name} = %s"
cursor.execute(select_query, (value,))
result = cursor.fetchone()
cursor.close()
connection.close()
return result[0] if result else None
def CriaArestas(Word1, Word2, Cmd):
print(Word1)
print(Word2)
"""Cria uma aresta associando Word1 e Word2 ao comando Cmd."""
word1_id = get_id_words(Word1, "word_name")
word2_id = get_id_words(Word2, "word_name")
cmd_id = get_id_commands(Cmd, "command_name")
print(word1_id);
print(word2_id);
print(cmd_id);
if not word1_id or not word2_id or not cmd_id:
print("Erro: Um ou mais valores não foram encontrados no banco de dados.")
return
connection = connect_to_database()
cursor = connection.cursor()
insert_query = """
INSERT INTO edges (word_id1, word_id2, command_id)
VALUES (%s, %s, %s)
"""
try:
cursor.execute(insert_query, (word1_id, word2_id, cmd_id))
connection.commit()
except mysql.connector.Error as err:
print(f"Erro ao inserir aresta: {err}")
cursor.close()
connection.close()Agora iremos povoar as arestas. Para isso usaremos a função:
ExemploAresta – Faz o cadastro das arestas baseado nas stop-words e palavras não numéricas.
def ExemploAresta():
for index, frase in enumerate(frases):
palavras = [palavra for palavra in frase.split() if palavra.lower() not in stop_words and not palavra.isnumeric()]
for i in range(len(palavras) - 1):
# Criamos arestas entre palavras sequenciais e associamos a um comando
CriaArestas(palavras[i], palavras[i+1], comandos[index])
Neste código podemos ver onde tudo se encaixa.
Onde criamos os exemplos, e finalizamos o cadastro.
connect_to_database()
ExemploWords();
ExemploCMD();
ExemploAresta();Aqui disponibilizo o arquivo do grafo, já montado.
GITHUB:
https://github.com/marcelomaurin/grafo01
No próximo post iremos apresentar a conclusão com o projeto montado o sistema de busca, onde faremos conclusões e testes no projeto.
Ecocardiografia: Novas Tecnologias e Tendências
Eco cardiograma portátil
A eco cardiografia é uma ferramenta diagnóstica essencial no mundo da cardiologia. Ao longo dos anos, a técnica tem evoluído consideravelmente, incorporando novas tecnologias e tendências que aprimoram a qualidade dos exames e oferecem informações mais detalhadas sobre o coração e suas estruturas adjacentes. Vamos explorar algumas das inovações recentes nesta área:
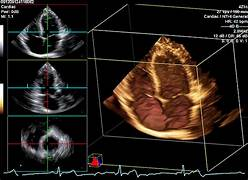
Ecocardiograma 3D
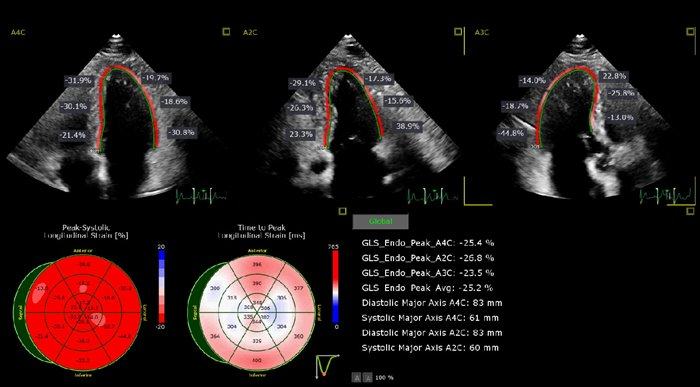
Stain Imaging
À medida que a tecnologia avança, é evidente que a eco cardiografia continuará a se adaptar e a incorporar essas novas ferramentas. Tais inovações não apenas melhoram a capacidade diagnóstica, mas também garantem que os pacientes recebam o mais alto padrão de cuidados cardíacos.

No artigo anterior:
Aprendemos a instalar o Espeak no windows.
Em outro artigo, ensinei a programar o espeak no linux:
https://maurinsoft.com.br/?docs=robotinics-2/software/srvfala
Agora iremos rodar o espeak no windows.
Primeiro iremos criar nosso projeto, Arquivo > Novo > Projeto.
Selecione Aplicativo de Console C++
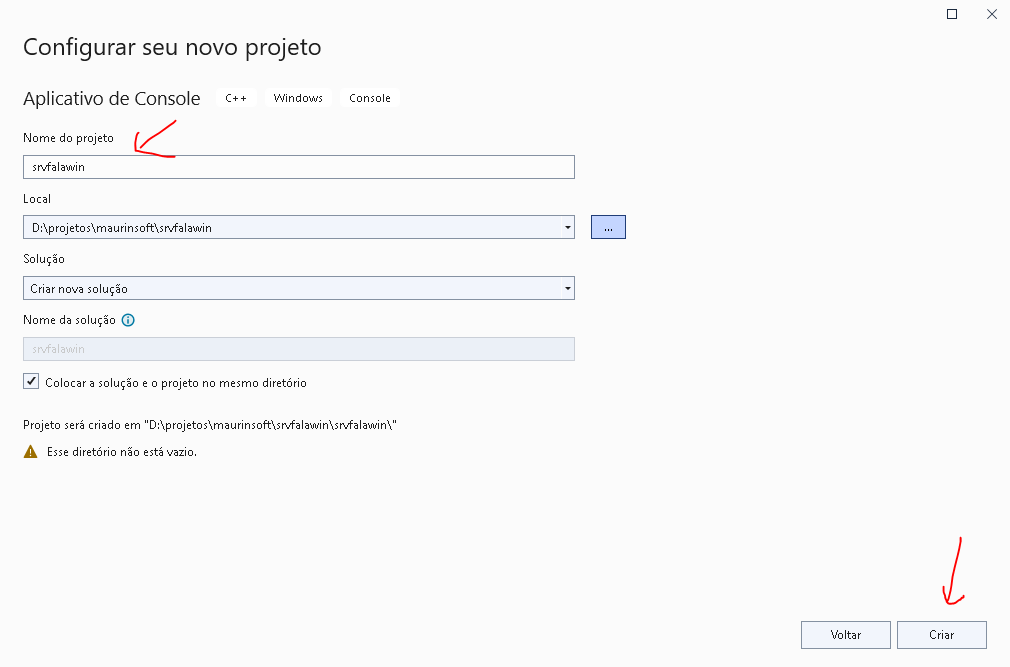
Crie o srvfalawin, apontando para o caminho onde irá criar o arquivo.
Agora iremos criar o código:
#include <stdio.h>
#include <stdlib.h>
int main() {
char frase[] = "Meu nome é marcelo, tudo bem com você?\0";
char comando[512];
// Criar o comando para executar o espeak.exe
snprintf(comando, sizeof(comando), "espeak.exe -v pt \"%s\"", frase);
// Executar o comando
system(comando);
return 0;
}
Neste código, fazemos uma simples referencia ao programa espeak, que eu instalei e adicionei no exemplo anterior no PATH.
Caso não tenha feito isso previamente esse programa não irá funcionar.

Neste artigo iremos descrever como instalar o ESpeak no windows, que é uma ferramenta consagrada no mundo linux para sintetização de voz.

No windows ele é pouco utilizado, porem tem vários beneficios.
Primeiramente ele é bem leve, e fácil de instalar.
Em segundo lugar ele é multi plataforma, podendo servir tanto para aplicações desktop como aplicações IoT.
Então vamos a instalação, primeiramente precisamos baixar ele no site:
https://espeak.sourceforge.net/
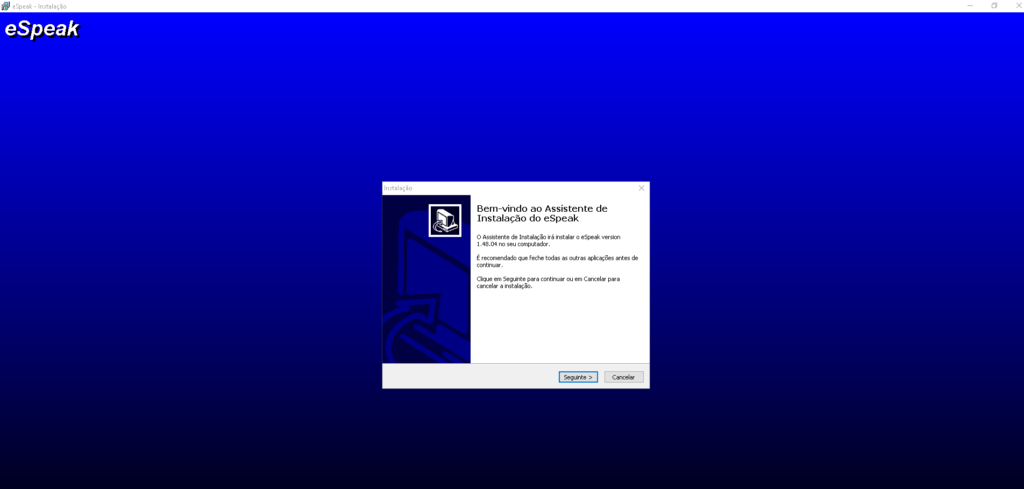
Para instalar, é muito simples, basta seguir o Next, Next , Finish.
Ele será armazenado em :
C:\Program Files (x86)\eSpeak
Agora será necessário adicionar o caminho:
C:\Program Files (x86)\eSpeak\command_line
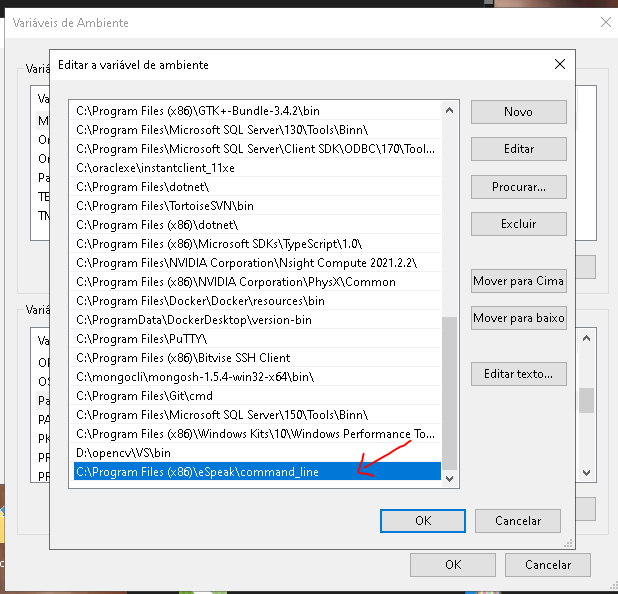
Dentro do path padrão, editando as variáveis de ambiente, assim como na imagem acima.
Agora que voce instalou o comando, iremos testar.
Entre no prompt de comando e digite o seguinte comando:
espeak -v pt "bom dia, meu nome é marcelo"Se voce fez o procedimento corretamente, o resultado é a sintetização de voz.

Pronto, voces fizeram a instalação do ESPEAK no windows.
Nós próximos artigos iremos entrar mais neste sintetizador.

Este projeto visa realizar o envase controlado de líquidos, provendo além do envase o aquecimento prévio.