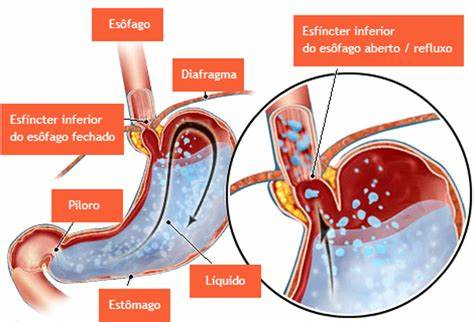
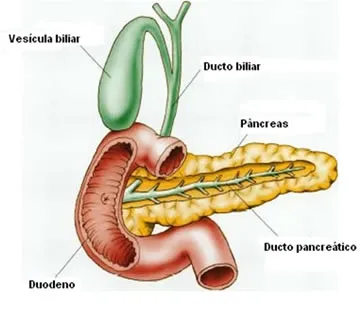
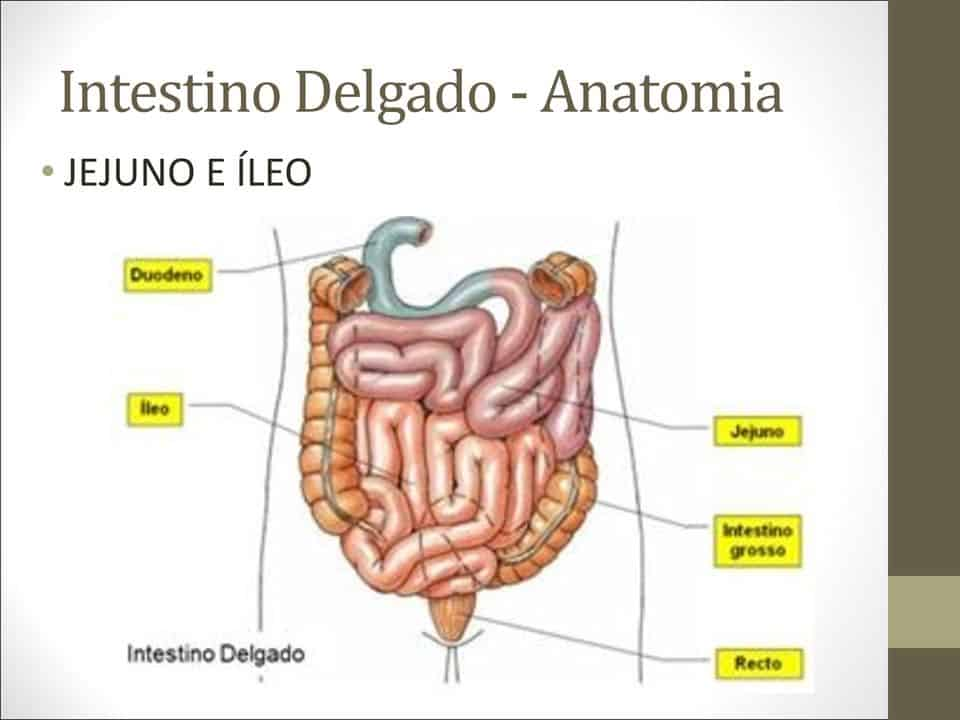
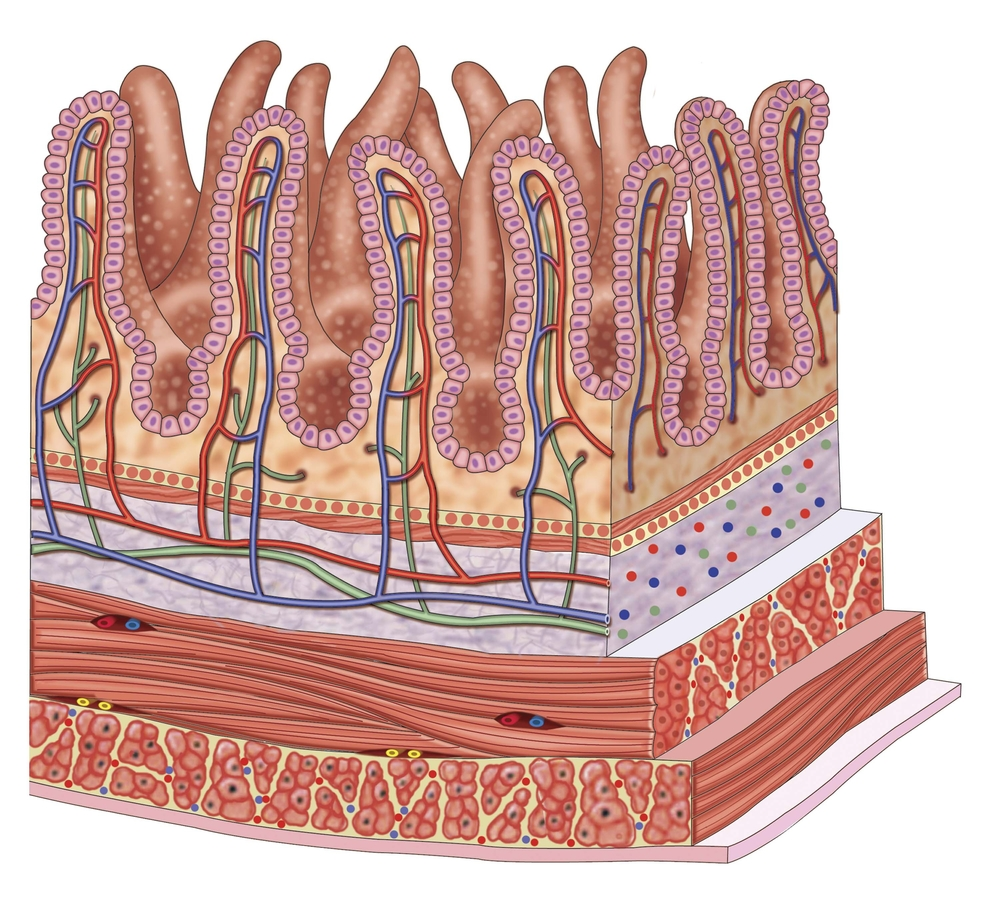
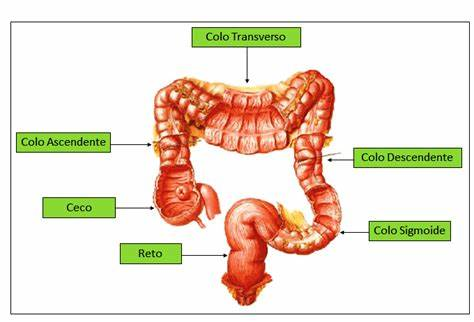
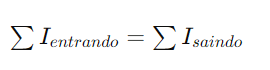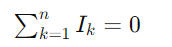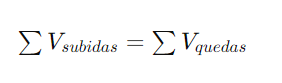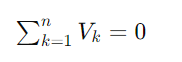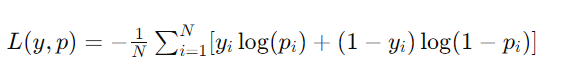Baixe o instalador assistido para seu sistema operacional
Baixe o compilador da sua plataforma
Execute o instalador, e aguarde o processo de instalação.
Após a instalação, rode o programa
cargo –version
teste do rust instalado
Após a sua instalação, o mesmo deve ser mostrado conforme apresentado.
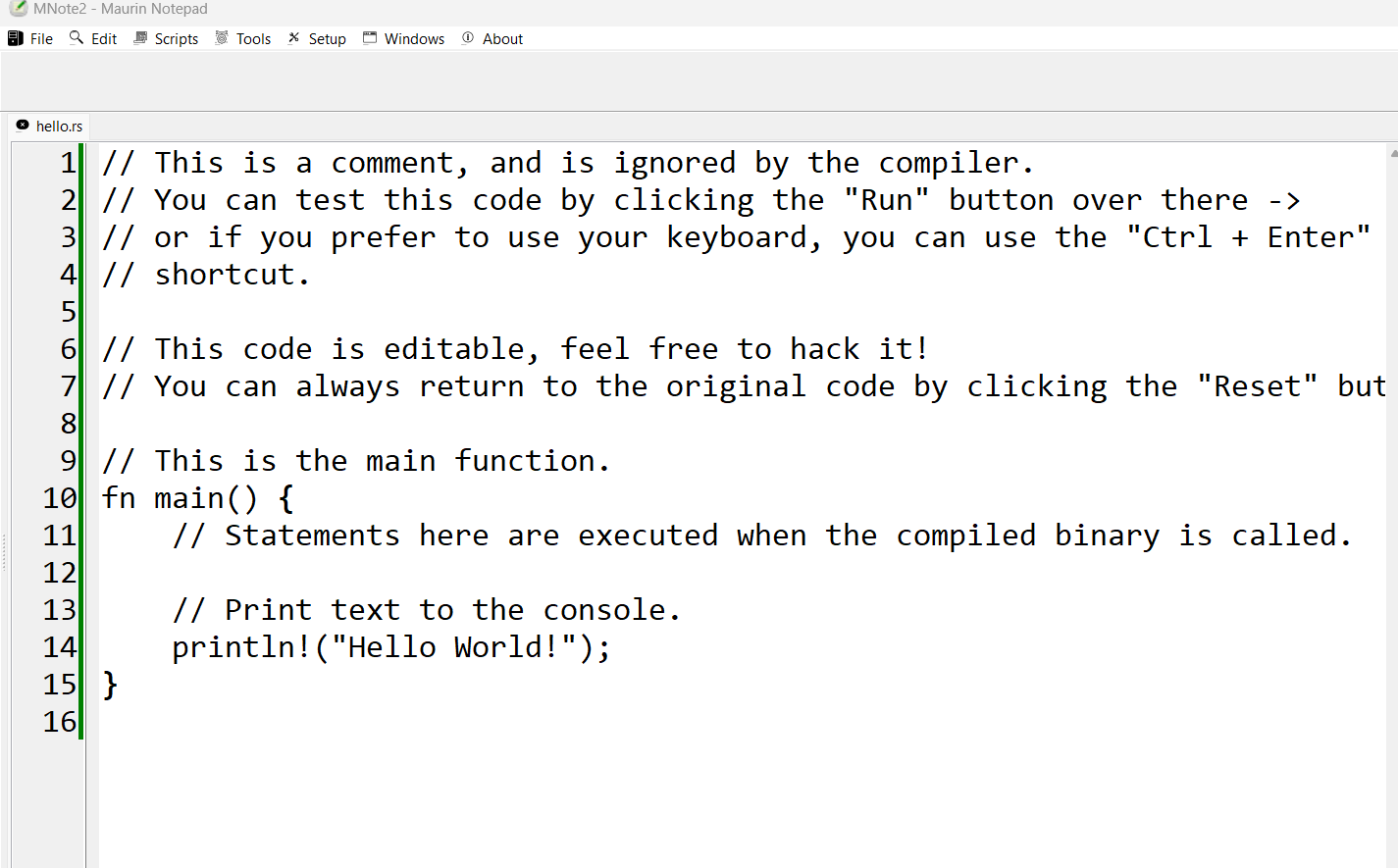
Crie um hello world.rs
// This is a comment, and is ignored by the compiler.
// You can test this code by clicking the "Run" button over there ->
// or if you prefer to use your keyboard, you can use the "Ctrl + Enter"
// shortcut.
// This code is editable, feel free to hack it!
// You can always return to the original code by clicking the "Reset" button ->
// This is the main function.
fn main() {
// Statements here are executed when the compiled binary is called.
// Print text to the console.
println!("Hello World!");
}
Pronto agora é só salvar na maquina.
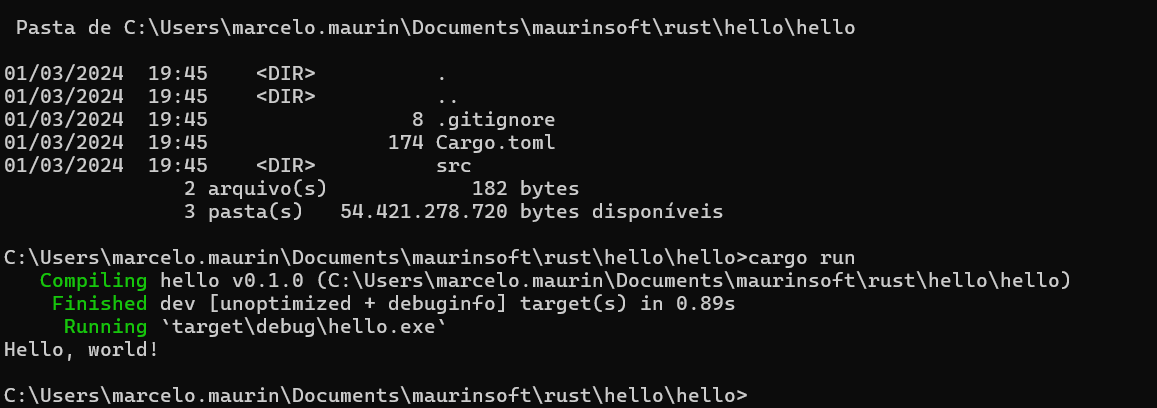
Agora iremos criar o projeto
cargo init hello
Cria o projeto do rust
Será criado uma pasta com o mesmo nome do projeto.
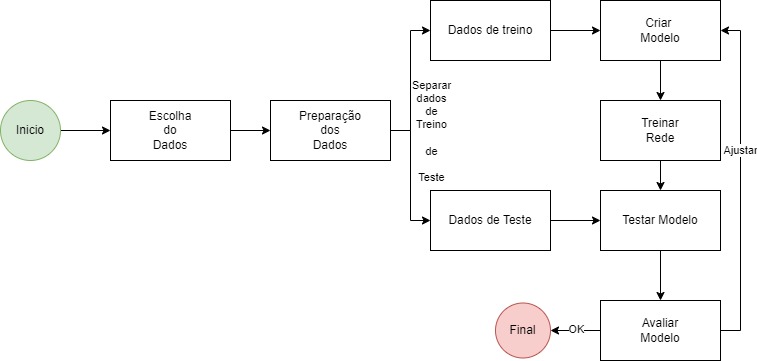
Neste fluxo bem simplificado, apresentamos uma visão de criação de uma IA.
Na primeira etapa, escolhemos os dados e entendemos a qualidade e características desses dados.
Em projetos de IA, nem sempre temos prontos os dados, muitas vezes precisamos preparar e coletar tais dados.
Em um segundo faz a preparação dos dados, acertando problemas e ajustando os dados. Na vida real, é praticamente impossível pegar bases prontas de clientes. Muitas vezes as bases de clientes, exigem uma analise e pré processamento, para realizar ajustes ou cortes. Necessários para obter dados coerentes com que queremos analisar.
A próxima etapa é separar dados em treinamento e testes. Onde usa-se o bom senso para avaliar as escolhas dos dados. Sendo uma referencia 70 /30% , onde 70 % dos itens serão utilizados para treinamento e os demais, serão usados para teste. Levando sempre em consideração a diversidade dos dados tanto para testes, como para treinamentos. A escolha aleatória dos 30% garante uma melhor probabilidade de sucesso, pois evita selecionar modelos com caracteristicas próximas , que podem iludir ou derrubar as estatísticas dos resultados.
Treinamento
O treinamento consiste em pegar os dados e aplicar a um modelo de IA conhecido, podendo ser NLP , redes convulocionais, ou outros tipos como Grafos.
Nesta etapa cria-se as estruturas e linguagem necessária para gerar a rede treinada.
Testes ou Validação
Nesta etapa usa-se os dados para gerar as informações separadas para validar a rede criada.
Analisando os resultados a partir de respostas conhecidas.
Melhoria ou Validação
A partir da analise dos resultados, são de fato, avaliados duas decisões:
Finalização do projeto ou etapa
Retorno a etapa de codificação, ajustando técnicas ou processos para corrigir problemas identificados.
Gustav Robert Kirchhoff foi um físico alemão que fez contribuições significativas em vários campos da física e da química. Ele é mais conhecido por suas leis que descrevem o fluxo de corrente elétrica em circuitos elétricos, as Leis de Kirchhoff, que são fundamentais para a engenharia elétrica e a física.
Kirchhoff nasceu em 1824 e faleceu em 1887. Durante sua vida, ele trabalhou em problemas de termodinâmica, óptica e espectroscopia, além de eletricidade. Junto com Robert Bunsen, Kirchhoff desenvolveu a espectroscopia, que é um método para analisar a composição química de materiais baseado na luz que eles emitem ou absorvem. Através desse trabalho, eles foram capazes de descobrir novos elementos químicos, como o césio e o rubídio.
As duas leis de Kirchhoff para circuitos elétricos, formuladas em 1845, são:
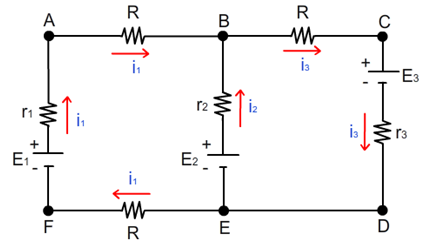
A Lei dos Nós (ou Lei das Correntes de Kirchhoff): A soma das correntes que entram em um ponto (ou nó) do circuito é igual à soma das correntes que saem desse ponto. Isso é uma consequência da conservação da carga elétrica.
A Lei das Malhas (ou Lei das Tensões de Kirchhoff): A soma das diferenças de potencial elétrico (tensões) em uma malha fechada é igual a zero. Isso é baseado no princípio da conservação de energia.
Essas leis são aplicadas no design e análise de circuitos elétricos, permitindo calcular correntes e tensões em diversos pontos de um circuito. Além de suas contribuições para a física, as descobertas de Kirchhoff tiveram um impacto duradouro em várias áreas da ciência e tecnologia.
Leis de Kirchhoff
As Leis de Kirchhoff são dois princípios aplicados em circuitos elétricos que ajudam a entender a conservação da carga e da energia em tais sistemas. Elas são fundamentais para a análise de circuitos elétricos em engenharia e física. As leis foram formuladas por Gustav Kirchhoff em 1845 e são conhecidas como Lei dos Nós (Primeira Lei) e Lei das Malhas (Segunda Lei).
1. Lei dos Nós (Lei das Correntes de Kirchhoff)
A Primeira Lei de Kirchhoff, ou Lei dos Nós, afirma que a soma algébrica das correntes em qualquer nó de um circuito é igual a zero. Isso significa que a quantidade total de corrente elétrica que flui para um nó é igual à quantidade total de corrente que sai dele. Matematicamente, isso pode ser expresso como:
ou, de forma mais geral,
onde ��Ik representa a corrente da k-ésima conexão em um nó, com correntes entrando no nó tratadas como positivas e correntes saindo como negativas. Essa lei é uma consequência da conservação da carga elétrica.
2. Lei das Malhas (Lei das Tensões de Kirchhoff)
A Segunda Lei de Kirchhoff, ou Lei das Malhas, afirma que a soma algébrica das diferenças de potencial (tensões) em qualquer malha fechada do circuito é igual a zero. Isso significa que a soma das quedas de tensão (consumo de energia) é igual à soma das tensões fornecidas (fontes de energia) em uma malha. Em outras palavras, a energia total em um circuito fechado é conservada. Matematicamente, pode ser expressa como:
ou, de forma mais geral,
onde Vk representa a diferença de potencial (tensão) na k-ésima componente da malha, com tensões no sentido do percurso assumidas como positivas e tensões contra o percurso como negativas.
Essas duas leis juntas permitem a análise completa de circuitos elétricos complexos, possibilitando calcular correntes e tensões em diversas partes de um circuito.
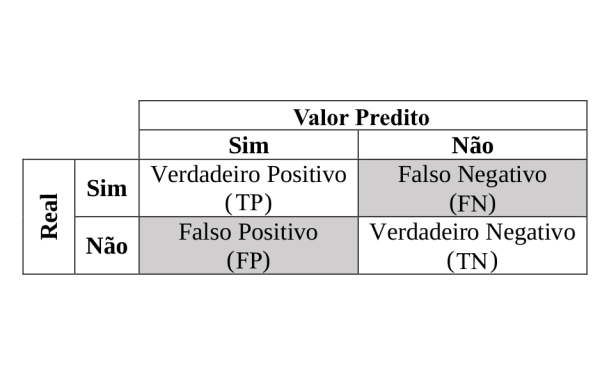
r = Sensibilidade (Sensivity) ou Repescagem (RECALL)
Logarithmic Loss (Perda Logarítmica)
A perda logarítmica, também conhecida como log loss ou cross-entropy loss, é uma medida de desempenho usada em problemas de classificação, especialmente em classificações binárias e multiclasse. Essa métrica quantifica quão distantes estão as probabilidades previstas de um modelo em relação aos valores verdadeiros ou reais (0 ou 1). A ideia é penalizar não apenas as classificações incorretas, mas também a confiança errada nas previsões.
Para uma previsão perfeita, a perda logarítmica é 0, e ela aumenta à medida que a previsão se afasta do valor real. Um aspecto importante da perda logarítmica é que ela penaliza severamente as previsões que estão confiantemente erradas. Por exemplo, uma previsão errada com alta certeza (por exemplo, prever a probabilidade de uma classe como 0.9 quando a classe verdadeira é a outra) resultará em uma penalidade maior do que uma previsão errada com baixa certeza.
A fórmula para a perda logarítmica em classificação binária é dada por:
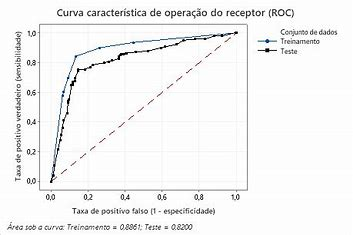
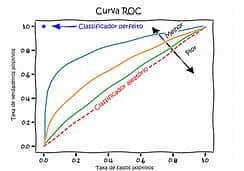
Receiver Operator Characteristic (ROC)
A Característica de Operação do Receptor (ROC, do inglês “Receiver Operating Characteristic”) é uma ferramenta utilizada para avaliar o desempenho de modelos de classificação binária. Ela é representada graficamente por uma curva que compara a taxa de verdadeiros positivos (sensibilidade) com a taxa de falsos positivos (1 – especificidade), para diferentes limiares de decisão.
A área sob a curva ROC (AUC, do inglês “Area Under the ROC Curve”) é um indicador da capacidade do modelo de discriminar entre as duas classes. Um valor de AUC igual a 1 indica um modelo perfeito, capaz de separar completamente as duas classes sem erros. Um valor de AUC igual a 0,5 sugere um desempenho não melhor do que o acaso, ou seja, o modelo não tem capacidade de discriminação entre as classes.
A curva ROC é particularmente útil porque permite a avaliação do desempenho do modelo em diferentes limiares, facilitando a escolha de um ponto de corte que equilibre entre a captura de verdadeiros positivos e a minimização de falsos positivos, de acordo com o contexto e os custos associados a cada tipo de erro.
AUC – Area Under Curve
AUC, que significa “Área Sob a Curva”, é um termo amplamente utilizado em análise de dados e machine learning, especialmente quando se refere à Curva ROC (Característica de Operação do Receptor). A AUC é uma métrica que quantifica o desempenho geral de um modelo de classificação, independentemente do limiar de decisão aplicado.
Características Principais da AUC
Avaliação de Desempenho: A AUC mede a capacidade do modelo de discriminar entre classes positivas e negativas. Um modelo com uma AUC de 1.0 é considerado perfeito, capaz de separar perfeitamente as duas classes. Um modelo com uma AUC de 0.5 não tem capacidade de discriminação, equivalente a um palpite aleatório.
Independente do Limiar: A AUC é particularmente útil porque é independente do ponto de corte escolhido. Isso significa que ela fornece uma medida do desempenho do modelo que não é afetada pela seleção de um limiar específico para a classificação de positivos e negativos.
Comparação de Modelos: A AUC permite comparar o desempenho de diferentes modelos de classificação diretamente. Um modelo com uma AUC maior é geralmente considerado melhor na discriminação das classes.
Aplicável em Diversos Contextos: Embora frequentemente associada à Curva ROC, o conceito de AUC pode ser aplicado a outras curvas, como a Curva Precision-Recall, especialmente em contextos onde as classes são muito desbalanceadas.
Limitações
Não Capta Todas as Dimensões de Desempenho: Embora a AUC forneça uma medida útil do desempenho geral de um modelo, ela não captura todas as nuances, como o equilíbrio entre sensibilidade e especificidade ou a precisão das previsões positivas (precisão).
Desbalanceamento de Classes: Em situações com desbalanceamento acentuado de classes, a AUC pode ser enganosa, sugerindo um desempenho melhor do que o modelo realmente apresenta, especialmente se a preocupação é com a precisão da classificação da classe minoritária.
Conclusão
A AUC é uma métrica valiosa para avaliar e comparar modelos de classificação, oferecendo uma visão geral da capacidade do modelo de discriminar entre classes. Contudo, é importante considerá-la junto a outras métricas para obter uma avaliação completa do desempenho do modelo.
Uso da biblioteca spacy para pesquisa de caracteres usando matcher.
#!pip install spacy
import spacy
import spacy.util
from spacy.matcher import Matcher
# Verifica se o modelo 'pt_core_news_sm' está instalado
if not spacy.util.is_package("pt_core_news_sm"):
# Se não estiver instalado, baixa o modelo
!python -m spacy download pt_core_news_sm
else:
print("Modelo 'pt_core_news_sm' já está instalado.")
# Carrega o modelo de linguagem do spaCy
nlp = spacy.load("pt_core_news_sm")
# Cria o objeto Matcher e o vincula ao vocabulário do modelo de linguagem
matcher = Matcher(nlp.vocab)
def ContarOcorrenciasPalavra(palavra, lista_textos):
# Ajusta a palavra para lowercase
palavra = palavra.lower()
total_ocorrencias = 0
# Define o padrão para procurar a palavra, considerando a correspondência de texto exato em lowercase
pattern = [{"TEXT": palavra}]
matcher.add("PADRAO", [pattern])
# Converte o texto para lowercase e processa com o spaCy
doc = nlp(lista_textos.lower())
matches = matcher(doc)
# Para cada correspondência encontrada, imprime detalhes
for match_id, start, end in matches:
matched_span = lista_textos[start:end]
print(f"Achou no Texto: {lista_textos}; Palavra: '{matched_span}' na POS: {start} até {end}")
total_ocorrencias += 1
return total_ocorrencias
textos = ["Neste exemplo de caso de uso.", "São exemplos de figura de linguagem aplicadas ao exemplo.", "Este exemplo possui um erro semantico.", "Tal qual o exemplo a seguir."]
for texto in textos:
print("Texto:"+texto)
ContarOcorrenciasPalavra("exemplo",texto)
ContarOcorrenciasPalavra("uso",texto)
ContarOcorrenciasPalavra("figura",texto)
ContarOcorrenciasPalavra("aplicadas",texto)
Saída do programa ao rodar
Texto:Neste exemplo de caso de uso.
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Achou no Texto: Neste exemplo de caso de uso.; Palavra: 'e' na POS: 1 até 2
Achou no Texto: Neste exemplo de caso de uso.; Palavra: ' ' na POS: 5 até 6
Texto:São exemplos de figura de linguagem aplicadas ao exemplo.
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'e' na POS: 6 até 7
Achou no Texto: São exemplos de figura de linguagem aplicadas ao exemplo.; Palavra: 'p' na POS: 8 até 9
Texto:Este exemplo possui um erro semantico.
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Achou no Texto: Este exemplo possui um erro semantico.; Palavra: 's' na POS: 1 até 2
Texto:Tal qual o exemplo a seguir.
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
Achou no Texto: Tal qual o exemplo a seguir.; Palavra: ' ' na POS: 3 até 4
A Lei dos Cossenos é uma importante fórmula usada na trigonometria para estabelecer uma relação entre os lados de um triângulo e o cosseno de um de seus ângulos. Essencialmente, ela permite calcular um lado de um triângulo quando conhecemos os outros dois lados e um ângulo, ou calcular um ângulo quando conhecemos todos os três lados. A Lei dos Cossenos é particularmente útil para triângulos que não são retângulos, onde o Teorema de Pitágoras não se aplica.
A fórmula da Lei dos Cossenos é expressa da seguinte forma:
�2=�2+�2−2��cos(�)c2=a2+b2−2abcos(C)
Nesta equação:
c representa o comprimento do lado do triângulo oposto ao ângulo C.
a e b são os comprimentos dos outros dois lados.
cos(C) é o cosseno do ângulo oposto ao lado c.
A Lei dos Cossenos pode ser reorganizada para resolver diferentes tipos de problemas, como encontrar o ângulo C quando os três lados são conhecidos:
cos(C)=2aba2+b2−c2
Esta lei é uma generalização do Teorema de Pitágoras. De fato, quando o ângulo C é um ângulo reto (90 graus), o cos(C) é 0, e a fórmula se reduz ao bem conhecido .
A Lei dos Cossenos é aplicável em muitos contextos diferentes, desde a resolução de problemas puramente geométricos até aplicações mais práticas em física, engenharia e navegação, permitindo calcular distâncias indiretas e ângulos quando a medição direta não é possível.